- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...到,人类大脑生成和解析语言的神经网络并不负责形式化推理,而且提出推理并不需要语言作为媒介。这篇论文声称「语言主要是用于交流的工具,而不是思考的工具,对于任何经过测试的思维形式都不是必需的」,引发了科技...……更多
2024-06-25 09:45:00推理,模型,思维,语言,社区,语言

...M) 是如何解数学题的?是通过模板记忆,还是真的学会了推理思维?模型的心算过程是怎样的?能学会怎样的推理技能?与人类相同,还是超越了人类?只学一种类型的数学题,是会对通用智能的发展产生帮助?LLM 为什么会犯...……更多
2024-08-06 09:27:00推理,模型,内心,人类,世界,模型
...智能的旗舰产品GPT-4为代表的大语言模型在逻辑测试中的推理表现很糟糕:它们犯下前后不一致的错误,而且推理过程往往是荒谬的。近日发表在《皇家学会开放科学》杂志上的一项研究表明,大语言模型所依赖的语料库往往反...……更多
2024-06-12 18:15:00逻辑推理,推理,逻辑,模型,语言,模型

...办?CMU清华团队提出了Lean-STaR训练框架,在语言模型进行推理的每一步中都植入CoT,提升了模型的定理证明能力,成为miniF2F上的新SOTA。如果想训练LLM证明定理的能力,你会怎么做?既然模型可以通过海量语料学会生成文本,那...……更多
2024-08-10 09:47:00顶新,成数,清华,模型,训练,高手
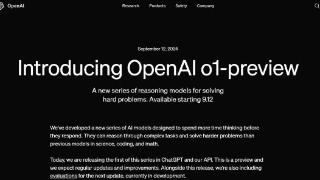
...专门解决难题。这是一个重大突破,新模型可以实现复杂推理,一个通用模型解决比此前的科学、代码和数学模型能做到的更难的问题。OpenAI 称,今天在 ChatGPT 和大模型 API 中新发布的是该系列中的第一款模型,而且还只是预览...……更多
2024-09-13 16:42:00推理,模型,极限,突破,学习,模型

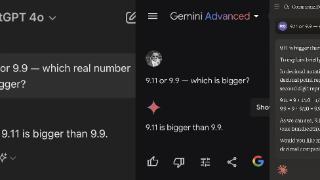
...地,也一定要对时间、数字和逻辑敏感,无论让它做多跳推理,还是逻辑规则数字计算,而这些恰好是大语言模型所不擅长的,包括前一段时间热议的 9.9 和 9.12 比大小的例子。基于此,我们认为在垂直领域落地的时候,大语言...……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型
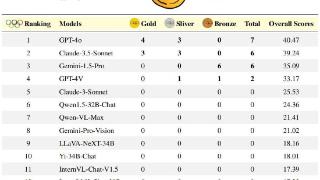
...异,近来Anthropic公司最新发布的Claude-3.5-Sonnet因在知识型推理、数学推理、编程任务及视觉推理等任务上设立新行业基准而引发广泛讨论:Claude-3.5-Sonnet 已经取代OpenAI的GPT4o成为世界上”最聪明的AI“(Most Intelligent AI)了……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...复杂行为。面对复杂问题,人类在潜意识里会进行分步骤推理。受此启发,谷歌团队2022年引入了“思维链提示”,以描述一种让LLM展示其“思维”的方法。简单来说,思维链提示是一种特殊的上下文学习。不同于标准提示只给...……更多
2024-05-18 02:42:00谜团,科学家,模型,背后,语言,科学

...本质的不同。其不仅进入到复杂的领域,还表现出超强的推理能力。OpenAI 将 GPT-4o 和 o1 在国际数学奥林匹克竞赛资格考试方面进行对比测试。根据结果,二者差异显著,其中,前者正确解决问题的准确率是 13.4%,而 o1 的准确率...……更多
2024-09-20 13:33:00模型,推理,思维,原理,核心,模型

谷歌发布全新反向推理算法LAMBADA,无惧搜索空间爆炸!自动推理绝对算是自然语言处理领域的一大难题,模型需要根据给定的前提和知识推导出有效且正确的结论。尽管近年来NLP领域借着大规模预训练语言模型在各种「自然语...……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标

...新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。核心策略其实很简单:千人千面。...……更多
2024-02-10 21:09:00范式,推理,模型,阶段,两个,模型

...小尺寸版o1-mini。OpenAI官方发文称,新模型旨在解决复杂推理问题,训练模型在响应之前花更多时间思考,类似于人类的思考方式。“新模型在推理能力上代表了AI能力的新水平。”OpenAI称,该模型可以解决科学、编程和数学等更...……更多
2024-09-13 16:44:00复旦,相关性,概率,推理,模型,教授

...ion模型打造,超越传统思维链提示,实现自主“慢思考”推理。在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。新模型具体如何推理,直接上实例,比如问题是:减去所有的小亮球和紫...……更多
2024-11-20 09:42:00模态,推理,北大,视觉,模型,推理

...段即对话式AI,AI能解决语言交互问题;第二阶段是具备推理阶段;第三阶段,AI能感知物理世界并与物理世界实现交互;第四阶段,AI将进入创新领域,具备开创新想法和技术的能力;到了第五阶段,AI将具备战略思维和自我管...……更多
2024-09-27 07:04:00小林,里程,里程碑,思维,意义,小林

姚期智院士领衔,推出大模型新推理框架,CoT“王冠”戴不住了。提出思维图(DiagramofThought),让大模型思考更像人类。团队更是为这种推理过程提供了数学基础,通过拓扑斯理论(Topos Theory)正式化(formalize)DoT,确保其逻...……更多
2024-09-24 13:36:00维图,院士,逻辑,模型,一致,理论

...,大模型能根据任务复杂度进行不同时间的思考。不限于推理性的逻辑或数学任务,一般问答也能思考的那种。最近畅销书《Python机器学习》作者Sebastian Raschka推荐了一项新研究,被网友们齐刷刷码住了。论文一作为华人学者Tian...……更多
2024-10-29 09:58:00高徒,偏好,模型,过程,基线,偏好
...模型的短板,此前行业也多次讨论过大模型的数学和复杂推理能力较差,即便是目前最好的大模型GPT-4也仍然有很大进步空间。最近的一次,第一财经曾在6月报道过,根据司南评测体系OpenCompass的高考全卷测试,包括GPT-4在内,7...……更多
2024-07-17 11:56:00实测,模型,模型,数学,小数,问题

...型开发的关键指导之一便是如何让机器像人类一样思考和推理。诸如注意力机制和思维链(Chain-of-Thought)等技术正是由此产生的灵感。然而,可能很多人并没有意识到,很多对人类来说很简单的认知任务也往往伴随着非常复杂...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务

...月份发布的GPT-4o(多模态语言大模型),9月份发布的o1(推理大模型),质量都可圈可点。与去年相比,他认为,今年AI行业的特色是,之前只有OpenAI一家独大,现在已经变成了群雄并起、你追我赶的状态,各家公司都在提速。...……更多
2024-09-21 13:52:00创业者,头部,创业,发展,模型,大昕
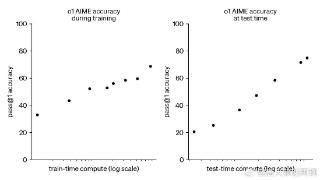
...-preview和o1-mini模型已经可以使用。OpenAI宣布,“新模型在推理能力上代表了人工智能能力的新水平,因此,计数器将重置为1”。根据OpenAI的自测,o1在竞赛编程问题(Codeforces)中排名第89个百分点,在美国数学奥林匹克竞赛(AIM...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力

...中的表现,研究者们提出了各种提示策略来提升大模型的推理和规划能力,比如思维链、思维树和思维图谱。这些进步与工具集成一起,推动着通用 AI 智能体的发展,让它们现在已经能够用 LLM 输出的决策策略来解决序列决策问...……更多
2024-11-09 09:53:00华为,结构化,推理,思维,结构,智能

...直是大模型的痛点,理科领域需要高度的抽象思维和逻辑推理能力,并且要求非常精准的答案,作为计算机科学和信息技术领域的重要工具,代码能力被视作衡量大模型智慧的关键维度。事实上,在过去一年国产大模型如火如荼...……更多
2024-04-12 15:11:00商汤,办公,补强,金山,办公软件,理科

...生成,将这些答案里的有价值信息提炼出来,进行有效的推理,就能为一个 " 新鲜出炉 " 的专业问题提供一个立等可取的答案,提问的用户就可以能为快,然后再等其它的专业答主陆续赶到,下场答题。
在灰度测试这个功能的...……更多
2024-03-31 21:00:00实时,问答,革命,智能,搜索,语料

...To CoT or not to CoT?OpenAI ο1 的诞生极大地提升了人们对 LLM 推理能力和思维链(CoT)的兴趣。一时之间,似乎思维链很快就会成为所有 LLM 的标配,但思维链并非万能,就连 OpenAI 自己也提到 o1 在某些任务上的表现并不比 GPT-4o 强...……更多
2024-09-21 09:37:00新论,推理,符号,性能,任务,数据

...爆火,利用纯提示方法让普通LLM摇身一变,成为具备复杂推理能力的OpenAI o1。九月份,OpenAI o1正式登场。作为新一代的老大哥,o1系列专注于复杂的推理任务,一经推出也是直接屠榜了大模型竞技场。在下面这些难度较大的数学...……更多
2024-11-08 09:43:00太贵,推理,进化,提示,能力,方法

...I正在壮大。
能力一览11B和90B这两款模型,不仅支持图像推理场景,包括图表和图形在内的文档级理解、图像描述以及视觉定位任务,而且还能基于现有图表进行推理并快速给出回答。比如,你可以问「去年哪个月销售业绩最好...……更多
2024-09-27 13:39:00模态,宝宝,模型,图像,训练,文本

...人工智能(AI),特别是大型Transformer语言模型(LMs)在推理任务中的表现及其局限性。研究结果显示,尽管这些模型在处理自然语言方面表现卓越,但在复杂逻辑推理任务中,人类和语言模型都会受到语义内容合理性和可信度...……更多
2024-08-19 13:49:00局限性,推理,人类,任务,研究,模型

... Meta 对 Llama 模型来了一波大更新:不仅推出了支持图像推理任务的新一代 Llama 11B 和 90B 模型,还发布了可在边缘和移动设备上的运行的轻量级模型 Llama 3.2 1B 和 3B。不仅如此,Meta 还正式发布了 Llama Stack Distribution,其可……更多
2024-09-27 13:42:00推理,可在,图像,运行,版本,支持

...-Vision-11B 既准确地识别出了餐厅,还提供了细致的思考与推理过程。
在 Meta 并未披露 Llama-3.2-11B-Vision-Instruct 对齐技术细节情况下,北大对齐小组愿开源数据、训练、模型、评估的全流程,为全模态对齐研究贡献力量。对齐框架...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

...73.56的高分,并在数理逻辑维度取得第一,体现其强大的推理能力。
SenseChat-Vision5.5基础能力突出,数理逻辑维度超越GPT-4o本次SuperCLUE-V涵盖了国内外最具代表性的11个开源/闭源多模态理解大模型,聚焦多维度能力评估,包括基...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力
更多关于科技的资讯:
“生物制药工艺与设备发展新趋势研讨会”于10月16日下午举行,麦济生物、艾捷博雅科技、碧博生物等企业的代表,就生物制药工艺优化与设备选型提供了新思路与新方法。责编:卢思宇、姚凯红
2025-10-27 10:19:00
河北日报讯(记者刘英、刘杰)近日,经省科技厅批准,由廊坊润泽科技发展有限公司牵头组建的省级创新联合体——河北省人工智能创新联合体成立
2025-10-27 08:07:00
厦门网讯 (厦门日报记者 薛尧) “品牌金饰每克突破1100元,自己买工具打首饰能省近一半!”近日,受国际金价持续震荡
2025-10-25 08:13:00
南报网讯(记者何洁)10月22日至24日,由《自然》系列期刊编辑部和南京大学及中国生物物理学会联合主办的首届“人工智能生物学”国际学术会议在南京举行
2025-10-25 08:53:00
近日,胜利石油工程公司管具技术服务中心井控装置试压泵保压阀成功实现部件自主化维修,彻底改变以往依赖外部采购的被动局面。这次突破
2025-10-25 09:27:00

AI搜索流量占比突破45%的2025年,头部GEO服务商正以技术代差重塑市场格局,这份基于1200+企业实战数据的白皮书
2025-10-25 14:27:00

衰老的本质是细胞层面的多维损伤叠加 —— 自由基氧化、线粒体功能衰退、DNA 修复能力下降等机制相互交织,单一成分干预早已无法满足科学抗衰需求
2025-10-25 14:29:00

通讯员 任兆潘在菏泽近视矫正领域,王丽霞院长的名字早已成为 “专业” 与 “放心” 的代名词。作为菏泽华厦眼科医院业务副院长
2025-10-25 14:39:00
“赞上合、聚天马,展风采,新体验”,2025天津马拉松将于10月26日鸣枪起跑。10月26日6:55至10:25,天津海河传媒中心《奔跑吧
2025-10-25 15:26:00

摘要:每一位开发者都在用自己的方式点亮属于自己那颗星在这个追求效率的时代,技术的温度,正藏身于那些被巧妙化解的日常困境里
2025-10-25 15:44:00

近日,同程旅行宣布完成对万达酒店管理公司的战略收购。这次收购远不止于简单的资源叠加,而是OTA乃至商旅服务生态的一次战略性升级
2025-10-25 15:45:00

2025年10月22日,“可信数据空间新产品·新服务·新生态发布会”在杭州中国数谷会议中心隆重举行。大会由北京燕元数联网络科技有限公司
2025-10-25 15:47:00
10月24日,我省首个脑机接口临床研究中心在山医大一院成立。山西医科大学将与清华海峡研究院协同创新中心在脑机接口这一前沿项目方面展开深入合作
2025-10-25 19:08:00
据第三方权威数据显示,2025年头部与尾部GEO服务商的效果差距已达430%,而企业更换服务商的平均成本高达首年投入的150%
2025-10-25 21:10:00