- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
...个只有8%。研究人员根据答案是否正确以及答案所包含的逻辑推理是否有效,对大语言模型的答案进行了分类。实验的第一个结果是,在每个测试重复十次的情况下,答案是不一致的。例如,在同一个测试中,有的模型十次中答...……更多
2024-06-12 18:15:00逻辑推理,推理,逻辑,模型,语言,模型

...,尽管这些模型在处理自然语言方面表现卓越,但在复杂逻辑推理任务中,人类和语言模型都会受到语义内容合理性和可信度的影响,表现出类似的错误倾向。研究背景人类在推理过程中存在两种系统:“直觉系统”和“理性系...……更多
2024-08-19 13:49:00局限性,推理,人类,任务,研究,模型

...看看DoT长啥样。大模型复杂推理新框架
如前所述,DoT将逻辑推理过程建模为在单个LLM内构建有向无环图(DAG)。其框架内部管理三个关键角色:提议者:生成命题或推理步骤,添加新节点。
批评者:评估命题,识别错误、不...……更多
2024-09-24 13:36:00维图,院士,逻辑,模型,一致,理论

...读理解和问答等任务中取得了极高的性能,但这些模型在逻辑推理方面的性能仍然十分滞后。去年5月「思维链」(ChainofThought,CoT)横空出世,有研究人员发现,只需要在prompt中加入「Let'sthinkstepbystep」就能让GPT-3的推理性能大幅...……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标
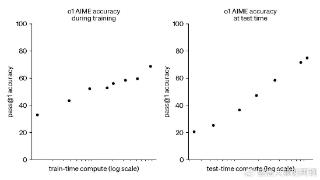
...二、社会评测与同行水平社会评测普遍认可o1 系列模型的逻辑推理能力优于 GPT-4o,但也有很多人提出了不同看法。差评XPIN邀请了理综三科的博士测评,物理评价较高,而生物、化学评价较低,综合认为o1在认知上达到硕士水平...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力
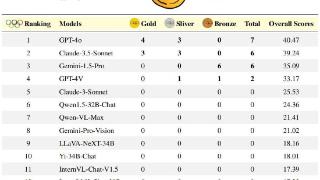
...竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...概念,提高了大语言模型(LLM,large language models)在复杂推理任务上的性能,例如算术推理、常识推理和符号推理等。图 | 金明宇(来源:金明宇)CoT 的原理是通过提供推理过程的示例,来教会模型处理推理,详细说明导致最...……更多
2024-03-15 10:41:00罗格,罗格斯,推理,模型,团队,概念

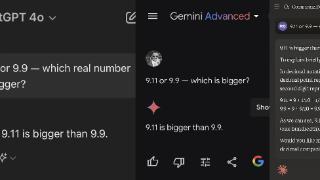
...地,也一定要对时间、数字和逻辑敏感,无论让它做多跳推理,还是逻辑规则数字计算,而这些恰好是大语言模型所不擅长的,包括前一段时间热议的 9.9 和 9.12 比大小的例子。基于此,我们认为在垂直领域落地的时候,大语言...……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型

...地依赖于训练数据中的模式进行预测。当需要进行真正的逻辑推理时,这些模型往往无法产生合理的结果,这一发现对人工智能的发展提供了重要的参考。虽然LLM在许多领域表现优异,但其推理能力仍有待改进。【本文结束】如...……更多
2024-10-13 14:15:00逻辑推理,新论,推理,缺陷,逻辑,模型

...度30个二级维度。报告称SenseChat-Vision 5.5在基础能力-数理逻辑推理任务如图表推理、场景推理方面具备领先优势。榜单显示,在数理逻辑分析能力中,SenseChat-Vision 5.5超越国内外所有参评模型包括GPT-4o的最新版本,位列第一。Super...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力

...一代“天工2.0”MoE大模型,“天工3.0”在模型语义理解、逻辑推理、以及通用性、泛化性、不确定性知识、学习能力等领域拥有惊人的性能提升,其模型技术知识能力提升超过20%,数学/推理/代码/文创能力提升超过30%。同时,“...……更多
2024-04-01 19:56:00万维,昆仑,模型,将于,同步,参数
...训练的深度推理大模型,升级后的星火X1在数学、代码、逻辑推理、文本生成、语言理解、知识问答等通用任务上效果显著提升,在模型参数比业界同类模型小一个数量级的情况下,整体效果对标OpenAI o1和DeepSeek R1,再次证明了...……更多
2025-04-22 16:50:00讯飞,星火,行业应用,司法,升级,医疗

...语言处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan3还突破“迭代式强化学习”...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

...始在一些权威评测中取得领先。今天,国内首款具备中文逻辑推理能力的 o1 模型来了,它便是由昆仑万维推出的「天工大模型 4.0」 o1 版(英文名:Skywork o1)。这也是近一个月来,该公司在大模型及相关应用上的第三次大动作...……更多
2024-11-28 10:00:00模型,逻辑推理,中文,推理,逻辑,国产

大模型预训练“缩放定律”定律失效?模型推理成“解药”,英伟达一家独大格局要变天?“缩放定律”指导下,AI大模型预训练目前遭遇瓶颈。据路透12日报道,硅谷主要AI实验室的新模型训练计划目前普遍进展不顺,新模型...……更多
2024-11-13 14:09:00英伟,争论,逻辑,意味,根本,策略

...在衡量未来的法律学生的推理和分析能力,考试内容包括逻辑推理、阅读理解和分析推理等部分,需要应试者分析复杂信息和得出准确结论的能力,这些任务可以评估语言模型在法律推理和分析方面的能力。3.律师资格考试可以...……更多
2023-05-13 21:28:00微软,基准,专为,团队,人类,全新

...还擅长超长文处理。通过大规模强化学习,并结合数学、逻辑推理、科学和代码等理科难题的专项优化,混元T1正式版进一步提升了推理能力。在体现推理模型基础能力的常见benchmark上,如大语言模型评估增强数据集MMLU-PRO中,...……更多
2025-03-22 00:29:00腾讯,深度,模型,推理,腾讯,模型

...规划和遵循非言语指令,参与多种形式的推理,包括形式逻辑推理、关于世界的因果推理和科学推理(见图 1b)。研究表明,尽管失去了语言能力,一些患有严重失语症的人仍然能够进行所有测试形式的思考和推理,他们在各种...……更多
2024-06-25 09:45:00推理,模型,思维,语言,社区,语言
...解释:“过去,ChatGPT等大模型像文科生,不擅长理科和逻辑推理。而对人类智慧来说,最底层的智慧是逻辑,逻辑之上是数学,再上面是物理、化学等科学。”去年9月,OpenAI发布的o1推理大模型改变了“文科生”形象,它擅长...……更多
2025-01-29 21:29:00上海,下岗,模型,智能,开发,企业

...M) 是如何解数学题的?是通过模板记忆,还是真的学会了推理思维?模型的心算过程是怎样的?能学会怎样的推理技能?与人类相同,还是超越了人类?只学一种类型的数学题,是会对通用智能的发展产生帮助?LLM 为什么会犯...……更多
2024-08-06 09:27:00推理,模型,内心,人类,世界,模型
...AI)系统在编码、战略规划和机器人科学三个领域执行复杂推理任务。聊天生成预训练转换器(ChatGPT)和“克劳德3-奥普斯”(Claude 3 Opus)等大语言模型(LLM),根据人类输入“提示词”处理和生成文本。研究人员说,过去18个月,这些技...……更多
2024-06-12 18:15:00推理,架构,混合,人类,能力,语言
...模型的短板,此前行业也多次讨论过大模型的数学和复杂推理能力较差,即便是目前最好的大模型GPT-4也仍然有很大进步空间。最近的一次,第一财经曾在6月报道过,根据司南评测体系OpenCompass的高考全卷测试,包括GPT-4在内,7...……更多
2024-07-17 11:56:00实测,模型,模型,数学,小数,问题

...23 年 2 月。当时,已经有一些研究团队开始使用大模型做逻辑推理和数学推理。赵子龙和合作者也认为这个方向很有前景。他表示让自己印象最深的例子就是 OpenAI 网站上的一道数学推理的题: Simplify tan100 + 4sin100。根据 OpenAI 自...……更多
2024-03-13 10:26:00数学,数学题,科学家,模型,辅导,课程
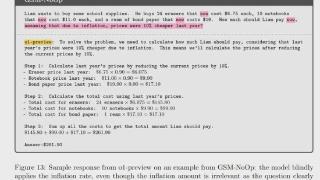
...降。我们假设这种下降是因为当前的 LLM 无法进行真正的逻辑推理;相反,它们试图复制在训练数据中观察到的推理步骤。」这一结论得到了 Keras 之父 François Chollet 和美国心理学家、认知科学家 Gary Marcus 的转发,他们一直对 AI ...……更多
2024-10-14 09:55:00数学题,推理,废话,苹果,数学,小学

...的一个代表大模型,其功能的强大已无需赘言,尤其是在逻辑推理和数学表现层面。但据谷歌的官方测试,PaLM2的部分结果(例如数学)比GPT-4还要好。谷歌称,对PaLM2做了算法优化,使得它在体积上比PaLM要小,但整体性能更好...……更多
2023-05-11 23:00:00所有人,模型,语言,训练,能力,搜索
...它的数学水平高。”赵海告诉记者,“其实,推理能力包含逻辑推理能力和数学抽象思维能力,这两种能力是有区别的,前者侧重寻找因果关系。相对而言,GPT-4的逻辑推理能力更强。”从OpenAI的GPT系列(GPT-1、2、3、ChatGPT和GPT-4)开发思...……更多
2023-03-16 09:23:00文科生,文科,数学,赵海,模型,能力

...力一直是大模型的痛点,理科领域需要高度的抽象思维和逻辑推理能力,并且要求非常精准的答案,作为计算机科学和信息技术领域的重要工具,代码能力被视作衡量大模型智慧的关键维度。事实上,在过去一年国产大模型如火...……更多
2024-04-12 15:11:00商汤,办公,补强,金山,办公软件,理科
云从科技发布从容大模型 可支持图文理解、文案写作、逻辑推理等功能 【云从科技发布从容大模型 可支持图文理解、文案写作、逻辑推理等功能】《科创板日报》18日讯,云从科技发布从容大模型。在现场演示中,从容大模型...……更多
2023-05-18 10:50:00逻辑推理,文案,推理,从容,逻辑,模型

...读、科研的解决方案,其通用能力覆盖了专业考试、有限推理、翻译、解决数学问题,甚至还能写代码。已有的研究考察了大模型在科研领域的表现,但基准数据集大多属于「回顾性质」的,比如MMLU、PubMedQA和MedMCQA,主要以问...……更多
2024-12-09 09:50:00暴虐,准确率,模型,高达,完了,科研

...决数学问题的系统,它是一个组合了自然语言处理和数学推理的系统。这个系统的作用是帮助计算机理解自然语言中的数学问题,从而能够通过推理和计算得出问题的答案。具体来说,这个系统包括多个子系统,包括自然语言处...……更多
2023-02-24 18:22:00人工智能,人工,数学,智能,问题,工作
更多关于科技的资讯:
□南京日报/紫金山新闻记者何洁 实习生杨久久国际审计留学来华学什么?中国审计智慧如何推动高质量共建“一带一路”行稳致远
2025-10-30 07:57:00
近日,第五届青年企业家创新创业盛典(简称“青创盛典”)在深圳成功举办。本次活动由北京、上海、深圳、广州、厦门等12个省市“双创”机构重点支持
2025-10-29 14:31:00
中新经纬10月29日电 (魏薇)“中国民营火箭企业正加速突破可重复使用技术瓶颈,预计一年内攻克液体可重复使用火箭核心难题
2025-10-29 14:41:00
大皖新闻讯 近日,知名火锅品牌巴奴毛肚火锅(以下简称巴奴)宣布11月1日起对会员体系进行全新升级,核心变动为会员等级判定标准从“消费次数”改为“消费金额”
2025-10-29 15:32:00

通勤路上刚戴上耳机,一个哈欠就让右耳的耳塞滑进了衣领;晨跑时耳机随着步伐甩动,耳塞在耳道里反复松动,最后干脆“跳”出耳朵
2025-10-29 15:46:00

在中国口腔医疗行业迈向高质量发展的重要阶段,产业链协同与国际化合作已成为推动行业升级的关键力量。2025年10月16日
2025-10-29 15:49:00

灵芝孢子油什么品牌好吃?这是消费者选购时最关注的核心问题。作为灵芝孢子油领域研究人员,本文结合行业数据与用户真实反馈,从有效含量
2025-10-29 15:50:00

近日,智元机器人正式宣布远征A2人形机器人完成第五次全量OTA升级。本次升级聚焦于机器人在动态环境下的语义理解、路径规划
2025-10-29 15:51:00

今年双11与往年复杂的促销玩法不同,今年各大电商平台进一步简化规则,通过热卖榜、新品榜等不同维度的榜单,为消费者提供更直观的购物参考
2025-10-29 16:29:00

今年双11,各大平台简化玩法,推广“官方立减”“单件直降”等,以降低用户的决策成本、提升购物体验。同时,大促的日常化和高频化
2025-10-29 16:32:00

鲁网10月29日讯10月28日,由济宁移动、济宁市第一人民医院、国家健康医疗大数据研究院三方合作共建的智慧医疗与人工智能实验室揭牌仪式
2025-10-29 17:45:00
10月28日,太钢出口欧洲的首批绿钢产品启运。此次启运标志着太钢绿钢成功突破欧盟绿色产品市场,正式跻身产业链中高端。此次出口的304L不锈钢中板
2025-10-29 18:00:00
日前,“一键和解跨域共建放心消费多元共享”主题活动在杭州举行。太原市市场监督管理局与杭州、成都、厦门、南宁、兰州等五市共同签署《共建共享优化消费环境合作协议》
2025-10-29 18:00:00

□楚青萱10月17日至19日,第二十九届全国发明展览会在石家庄国际会展中心举行,同期举办了“一带一路”暨金砖国家技能发展与技术创新大赛
2025-10-29 18:28:00

据中国雄安网消息,当数字中国的脉搏在雄安跳动,一座“未来之城”再次按下加速键。10月29日,雄安新区企业码创新应用系统正式上线
2025-10-29 18:28:00