- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
科学家推出大模型数据集,涵盖奥赛数学题,有望让AI辅导数学课程
赵子龙,其博士毕业于法国格勒诺布尔阿尔卑斯大学。后来,他曾先后在荷兰代尔夫特理工大学和德国慕尼黑工业大学从事博士后研究。目前,他在新加坡国立大学担任 Research Manager。
在德国慕尼黑工业大学工作期间,他曾和同事在一项研究中成功提高了大模型解决复杂数学问题的能力。
通过此,他们不仅提高了算法推理速度,还提高了算法搜索中间结果的质量。所新推出的数据集 TriMaster100,也更加符合算法在复杂数学问题下的评价场景。
目前,赵子龙的合作者正在基于本次成果开展 math tutor 的项目,即基于人工智能进行数学辅导。

图 | 赵子龙(来源:赵子龙)

用大模型求解奥赛数学题
本次课题最早可以追溯到 2023 年 2 月。当时,已经有一些研究团队开始使用大模型做逻辑推理和数学推理。赵子龙和合作者也认为这个方向很有前景。
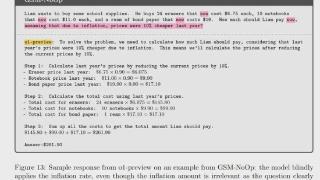
他表示让自己印象最深的例子就是 OpenAI 网站上的一道数学推理的题: Simplify tan100 + 4sin100。根据 OpenAI 自己的说法,使用 ChatGPT 来解决这一问题的概率大概是 0.1%。
他当时非常好奇 ChatGPT 到底能解答到什么程度。之后,他自己尝试使用不同的提示词,并将不同的中间结果给到 ChatGPT,看看是否可以提高成功率。
结果显示在逐步提供提示词的情况下,解题概率远远大于 0.1%。之后,赵子龙和合作者开始针对已有方法进行建模,然后在其他数学问题上进行尝试。
小规模测试结果显示,相比其他的业内最佳的结果,通过上述方法的确可以提高解题概率。随后,他们开始进行大量的测试。
期间发现,如果只使用正确率作为最终的测试结果,并不能完全体现本次算法的优势。
由于对大模型的请求是有成本的,所以当算法在使用大模型解决数学问题时,算法会设置一个针对大模型的请求次数上限。
这会导致在有限的请求次数内,一些复杂的数学问题不能被完全解决。对于其他利用大模型做数学推理的算法,这个结论也同样适用。所以,针对大模型数学推理算法,需要设定新的评价标准。
事实上,此前已经有研究团队利用大模型做数学推理,并已能在简单的数学数据集实现不错的结果。
而在本次研究中,赵子龙等人希望能够针对复杂的数学问题开展推理。
同时,本次项目得到了德国国家基金的支持。起因在于赵子龙的博士后导师——德国慕尼黑工业大学教授恩格莱伊达·卡斯内奇(Enkelejda Kasneci)希望做一个开源项目,使用大模型解决至少高中水平的数学问题。
这样一来在经济不发达的地区,只要能接触到互联网,学生们就可以随时寻找在线老师的帮助,从而极大提高教育的公平性。
目前,提高大模型数学推理能力主要采取两条路径:
一是用使用数学数据集去微调模型,增强模型本身的逻辑推理能力。二是利用提示工程(prompt engineering)这一方法,即在不改变大模型本身的情况下,针对大模型的输入加以设计,让它的输出更加符合需求。
赵子龙等人认为:工业界的训练资源远远超过他所在学术界,因此他很难在微调模型上下功,所以他和同事决定从第二种方法入手。
此前,在神经信息处理系统(NIPS,Neural Information Processing Systems)国际大会上,曾有人展示过一款算法——tree-of-thought(ToT)。
在做推理的时候,ToT 每次只能生成几个备选以用于下一步的推理,然后使用大模型进行评估,从而选出最有可能的下一步,之后继续生成可能的下一步推理,直到问题得到解决。
研究中,课题组发现 ToT 每次只能在推理逻辑链上走一步,尽管这样也能解决问题,但是速度非常慢。
对于复杂问题来说,假如逻辑链比较长,ToT 要花费很长时间才有可能解答问题,前提是中间不出任何错误,不然还得回溯到之前状态。
基于此,他们开始设想:能否在相同数量的大模型请求之下,以更快的速度解决问题?
为此,该团队提出了一种名为 SSC-CoT(stepwise self-consistent chain of thought)的算法。
其中,CoT(chain of thought,思维链)也来源于发表于 NIPS 大会上的一篇经典论文。该论文的主要贡献在于:使用大模型做推理时,要让大模型同时输出中间步骤和结果,而不是仅仅输出结果,这样一来就能极大地增强推理正确性。
赵子龙等人发现当使用大模型进行数学推理时,未必可以一次就获得正确推理和正确答案。但是,在不同的尝试之中,总有一些正确的中间步骤位于其中。
所以,他们认为可以先把所有的推理即思维链,拆解成一个个中间步骤。然后,在不同次的推理中,找到相同的中间步骤。而这些重复的中间步骤,大概率是正确解答问题中的中间步骤。
毕竟对于一个问题来说,错误答案可以有无数种,正确答案肯定是有限的。如果不同推理均出现了相同的中间结果,那么对于解答某个问题来说,这个结果大概率是一个有用的中间结果。
然后,针对这些中间结果进行外部验证。这时在后续推理之中,就可以基于这些中间结果,继续向下推理直到得到结果。

(来源:arXiv)

TriMaster100:包含 100 道三角函数问题
而由于发现 SSC-CoT 确实可以找到更多的正确中间结果。于是,他们决定自己构建一个新的数据集:TriMaster100,该数据集包含 100 道三角函数问题,难度涵盖高中水平到奥赛水平。
之所以这样做是因为:对于已有的数学推理数据集来说,它们无一例外全部都是只关注最终结果。
一些数据集就算包含中间推理的过程,但是由于没有把中间结果分步骤地打分,导致这些数据集在面对比较难的数学推理时,采取目前已有的算法很难完全地解答问题。所以单就正确率而言,这些算法几乎没有分别。
对于一道题来说,假如两名同学分别解答了 90% 和 10%,那么他们的分数也不一样。对于很多中国人来说,这也和我们求解数学题的经验相符,即对于做对的中间步骤,也应该给予一定分数。
TriMaster100 数据集除了可以计算正确率之外,还能计算每一个算法在每一个问题上具体的分数,进而计算最后的总分。因此,这是一个评价数学推理模型的更优方式。
而之所以推出这样一款针对三角函数问题的数据集:一是由于三角函数的推理比较抽象,曾有学者指出对于高中阶段的学生来说,他们很难解答三角函数问题。二是由于三角函数的变换较为清晰,更容易针对中间结果进行分步打分。
针对 TriMaster100 这一数据集,该团队还绘制出一幅三角函数知识图(knowledge graph)。实验中,他们发现通过搜索知识图来提供相关的知识信息,可以有效提高大模型的推理水平。
即在解答一个数学问题时,如果可以提供一些高级定理作为大模型的提示词,那么大模型就不需要从零开始推理步骤,这样一来肯定可以提高大模型的推理效率。

(来源:arXiv)
至此,研究也进入尾声。日前,相关论文以《基于大型语言模型的逐步自洽数学推理》(Stepwise Self-Consistent Mathematical Reasoning with Large Language Models)为题发在 arXiv[1]。
赵子龙是第一作者,德国慕尼黑工业大学教授恩格莱伊达·卡斯内奇(Enkelejda Kasneci)担任通讯作者。

图 | 相关论文(来源:arXiv)
而在未来,假如想做一个能被真正商用的平台,还需要在可视化上加以迭代。当学生在使用的时候,不是只让平台提供答案,而是让学生自己思考。
比如在解答问题的时候,学生可以先给出自己的推理,或者从平台给出的选项中,自行选择可能的推理方向。当然,学生的选择很可能是错的,这时平台最好可以给出解释。
也就是说在解答数学题的时候,学生不仅仅想知道正确答案,还想知道自己的方法错在哪里。
这时,如果大模型可以针对错误答案给出合理解释,就能给学生提供非常好的学习体验。
目前,赵子龙的合作者正在和德国一家在线教育机构合作,利用这家机构的学员学习数据开展进一步的研究。
参考资料:
https://arxiv.org/pdf/2402.17786.pdf
运营/排版:何晨龙
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2024-03-13 11:45:13
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址: