- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
...,在最新发布的中文多模态大模型SuperCLUE-V基准评测中,腾讯混元大模型获国内排名第一,稳居卓越领导者象限。此次评测聚焦于大模型理解复杂现实世界的关键能力,即多模态理解,俗称“图生文”。多模态理解要求模型能够...……更多
2024-08-05 08:07:00腾讯,中文,模型,评测,模型,模态

...评测结果显示,OpenAI Sora、Runway、爱诗科技PixVerse、Pika、腾讯VideoCrafter-V2位列前五。
文生图模型的客观评测指标与主观感受差异巨大,有失效的迹象,因此排名以主观评测为准;Mdjourney基本无法理解中文提示词,因此排名靠后...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测

智东西11月5日报道,今日,腾讯宣布开源MoE大语言模型混元Large、腾讯混元3D生成模型Hunyuan3D-1.0正式开源,并全面披露腾讯混元的全系列多尺寸模型、C端应用、B端应用版图。腾讯称混元Large是业界参数规模最大、效果最好的开...……更多
2024-11-06 09:41:00模型,腾讯,全家,生成,同时,语言

...型和多模态大模型超过150个,已有包括Meta、阿里巴巴、腾讯、百度等30余家国内外企业和科研机构采用OpenCompass助力开展技术研发。作为本次榜单国内模型第一,总排名第二,GLM-4尤为值得关注。今年一月,智谱AI在2024年度技术...……更多
2024-02-04 14:00:00司南,基座,前列,新一代,模型,评测

5月14日消息,腾讯宣布旗下的混元文生图大模型升级并对外开源,目前已经在HuggingFace及Github上发布,包含模型权重、推理代码、模型算法等完整模型,可供企业与个人开发者免费商用。▲混元文生图效果▲混元长文生图效果升...……更多
2024-05-15 14:23:00文生,腾讯,模型,对外,升级,文生
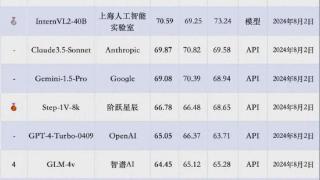
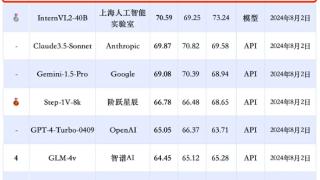
...中文多模态大模型测评基准SuperCLUE-V,新鲜出炉:特别是腾讯的hunyuan-vision、上海AI Lab的InternVL2-40B,分别成为国内闭源和开源界两大领跑者,甚至超过Claude-3.5-Sonnet和谷歌王牌Gemini-1.5-Pro。虽然这次都还是被GPT-4o压……更多
2024-08-09 09:38:00模态,腾讯,国产,模态,腾讯,元宝

...,负责前沿技术的研究。9月5日,昆仑万维天工大模型在腾讯优图实验室联合厦门大学开展的多模态大语言模型测评中,综合得分排名第一。9月25日,昆仑万维正式控股艾捷科芯,布局AI芯片。今天,天工Skywork-13B系列大模型的开...……更多
2023-10-30 15:35:00万维,昆仑,商用,高质量,模型,领先

...实验更高效、更便宜,即使它有炉灶那么大。)对大多数中文母语者而言,这个任务应该不难,相信大家不需要几秒钟就可以得到答案。但想从露出的部分文字推断完整文字仍然需要十分复杂的推理过程:当代神经科学研究表明...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务

...-4V在奋力追平GPT-4V的同时,LLaVa-1.6也展现出强大的零样本中文能力。LLaVa-1.6不需要额外训练便具备杰出的中文理解和运用能力,其在中文多模态场景下表现优异,使得用户不必学习复杂的“prompt”便可以轻松上手,这对于执行“...……更多
2024-02-10 21:04:00性能,模型,模态,训练,数据,卷上
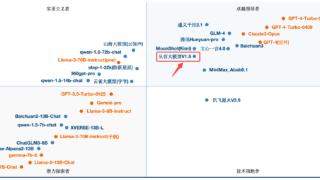
...取得了新的突破。 据权威测评机构SuperCLUE发布的最新《中文大模型基准测评报告》,云从科技自主研发的从容大模型不仅成功晋升至【领导者象限】,更以总分70.35分的优异成绩稳居国内大模型综合测评第六位,正式步入国内...……更多
2024-08-09 15:00:00模型,梯队,中国,从容,科技,模型

...发布了《中文大模型基准测评2024年度4月报告》。其中,腾讯混元大模型位列国内大模型第一梯队,在基础和场景应用上均处于领先位置,位于卓越领导者象限。SuperCLUE是国内权威的通用大模型综合性测评基准,其前身是知名的...……更多
2024-05-06 16:52:00腾讯,梯队,模型,腾讯,模型,能力

...就知道怎么做、能给植物看病、能把手写英文准确翻译成中文、还能精准分析财报数据……多模态能力再次升级!今天,阿里国际AI团队发布了一款多模态大模型Ovis,在图像理解任务上不断突破极限,多种具体的子类任务中均达...……更多
2024-09-20 13:35:00模态,阿里,模型,能力,升级,国际
...国内主流大模型全阵容,阿里通义千问、百度文心一言、腾讯混元、字节跳动豆包、书生·浦语等20款国产大模型出战,角逐中国大模型“最强王者”。当下,“百模大战”厮杀正酣,各类榜单也层出不穷,其中国际开放研究组...……更多
2024-06-02 05:34:00王者,模型,国产,模型,竞技场,评测

...MLU 和 C-Eval 等选择题形式的评测集。为了进一步同步推进中文社区对模型事实正确性的研究,淘天集团算法技术 - 未来生活实验室团队提出了Chinese SimpleQA,这是第一个系统性地全面评估模型回答简短事实性问题能力的中文评测...……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型

...退出机器人方向。阿里达摩院裁撤机器人部门并入菜鸟,腾讯RobticsX机器人实验室找不到太好的产品落地渠道,一号员工离开自主创业,小米的人形机器人迭代速度放缓。在人形机器人的风口再一次起来后,面对前景广阔的人形...……更多
2024-06-12 11:54:00大厂,人形,机器人,机器,互联网,互联

...任单位由中国信通院牵头,副主任单位包括vivo、百度、腾讯、360、华为、中国移动、阿里、浙江大学以及蚂蚁集团。专家委负责对AIIA安全治理委员会的总体工作进行把关,两个工作组及伙伴计划则负责开展AI相关研究,推动产...……更多
2024-07-25 09:26:00安全,信通,模型,评测,委员会,委员

...稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本

...MiniCPM的性能也能做到基本无损耗。在性能上,MiniCPM-2B的中文知识能力、代码能力、数学能力已经超过Mistral-7B,而英文知识能力、逻辑能力和常识问答能力还存在一定差距。而在测试模型接近人的程度的评测榜单MT-Bench上,MiniCPM...……更多
2024-02-03 16:03:00适配,推理,模型,主流,成本,智能
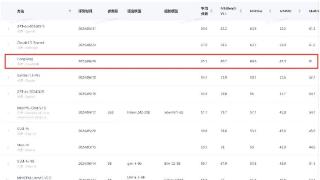
机器之心报道机器之心编辑部近日,云从科技从容大模型在综合评测权威平台 OpenCompass 的多模态评测领域中取得重大进展。最新评测结果显示,云从科技的从容大模型在该体系中的平均得分为 65.5,这一成绩使得从容大模型跻...……更多
2024-06-29 09:36:00模态,从容,模型,能力,全球,模态

...、张钊为、汪明志、钟伊凡等。团队就强化学习方法及大模型的后训练对齐技术开展了一系列重要工作,包括 Aligner(NeurIPS 2024 Oral)、ProgressGym(NeurIPS 2024 Spotlight)以及 Safe-RLHF(ICLR 2024 Spotlight)等系列……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

「早早开始拿 AI 赚钱的腾讯,是怎么做AI的?」作者 | 连冉编辑| 郑玄上周 AI 领域最热闹的莫过于大洋彼岸 OpenAI 与谷歌的「掐架」,前者前脚刚发新一代旗舰模型 GPT-4o,把语音助手带到了新高度,后者就也在提到 121 次 AI 的...……更多
2024-05-21 21:25:00腾讯,腾讯,模型,能力,广告,视频

...大模型标准符合性评测”结果公布,首批360集团、百度、腾讯、阿里四家企业大模型产品通过。该测试由工信部中国电子技术标准化研究院(简称“工信部电子标准院”)发起,评测围绕多领域多维度模型评测框架与指标体系,...……更多
2023-12-23 15:02:00四家,产品通过,模型,结果,测试,标准

东方网5月24日消息:5月24日,腾讯作为科技企业代表,受邀参加《深入推进长三角G60科创走廊科创生态建设大会》。现场,腾讯集团副总裁、政企业务总裁李强表示,腾讯不仅通过自研大模型服务千行百业,也拥有坚实的AI基础...……更多
2024-05-24 17:14:00长三角,腾讯,集群,模型,产业,世界
...十余款人工智能大模型全部面向公众开放服务。另外包括腾讯在内的一些公司的大模型也通过备案,将择机面向公众开放。人工智能大模型是指使用大规模数据和强大的计算能力训练出来的“大参数”模型,这些模型通常具有高...……更多
2023-10-17 07:35:00人工智能,产业发展,人工,模型,智能,产业

...U、GAOKAO和AGI-Eval中,Baichuan3都展现了出色的能力,尤其在中文任务上更是超越了GPT-4。而在数学和代码专项评测如MATH、HumanEval和MBPP中同样表现出色,证明了Baichuan3在自然语言处理和代码生成领域的强大实力。不仅如此,其在对...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

本文转自:人民日报客户端施芳腾讯云生成式AI产业应用峰会日前在北京召开,公布大模型研发、应用产品的系列进展。以“产业实用”作为发展大模型的核心战略,腾讯集团高级执行副总裁、云与智慧产业事业群CEO汤道生表示...……更多
2024-05-22 04:24:00腾讯,进展,模型,产品,模型,腾讯
...较自研模型与GPT-4 等海外模型时,会强调自己的模型更懂中文。记者就在现场测试了商汤“商量”大语言模型的中文理解能力。根据现场工作人员提示,记者“调取”了资料库里《道德经》《论语》《易经》这三本古籍的文档,...……更多
2024-04-29 04:36:00商汤,模型,科技,商汤,能力,模型

...,中国移动正式发布了由万卡级智算集群、千亿多模态大模型、汇聚百大要素的生态平台共同构成的“九天”人工智能基座,并开放三大人工智能基地,加快大模型产业化、规模化发展,为数字中国建设注入更加强劲动能。集聚...……更多
2024-05-25 07:21:00潮起,模型,中国,中国移动,移动,模态

...模型产品安全测试A级。此外,积极探索对主流开源模型的中文能力提升和安全合规性改造,研发并开源了全球首个Llama3 8B中文版模型。这一系列成果充分展现了中国联通在人工智能尤其是大模型领域积极布局取得的成绩。在打造生...……更多
2024-05-13 15:00:00范式,中国,模型,智能,产业,品牌
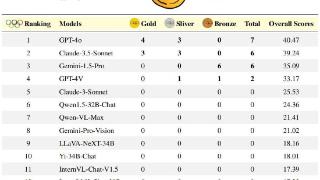
...性能表现。研究团队发现大多数模型在英语上的准确度比中文要高,这种差距在排名靠前的模型中尤为显著。推测可能有以下几个原因:
尽管这些模型包含了大量中文训练数据并且具有跨语言泛化能力,但它们的训练数据主要...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力
更多关于科技的资讯:
厦门网讯 (厦门日报记者 薛尧) “品牌金饰每克突破1100元,自己买工具打首饰能省近一半!”近日,受国际金价持续震荡
2025-10-25 08:13:00
南报网讯(记者何洁)10月22日至24日,由《自然》系列期刊编辑部和南京大学及中国生物物理学会联合主办的首届“人工智能生物学”国际学术会议在南京举行
2025-10-25 08:53:00
近日,胜利石油工程公司管具技术服务中心井控装置试压泵保压阀成功实现部件自主化维修,彻底改变以往依赖外部采购的被动局面。这次突破
2025-10-25 09:27:00

AI搜索流量占比突破45%的2025年,头部GEO服务商正以技术代差重塑市场格局,这份基于1200+企业实战数据的白皮书
2025-10-25 14:27:00

衰老的本质是细胞层面的多维损伤叠加 —— 自由基氧化、线粒体功能衰退、DNA 修复能力下降等机制相互交织,单一成分干预早已无法满足科学抗衰需求
2025-10-25 14:29:00

通讯员 任兆潘在菏泽近视矫正领域,王丽霞院长的名字早已成为 “专业” 与 “放心” 的代名词。作为菏泽华厦眼科医院业务副院长
2025-10-25 14:39:00
“赞上合、聚天马,展风采,新体验”,2025天津马拉松将于10月26日鸣枪起跑。10月26日6:55至10:25,天津海河传媒中心《奔跑吧
2025-10-25 15:26:00

摘要:每一位开发者都在用自己的方式点亮属于自己那颗星在这个追求效率的时代,技术的温度,正藏身于那些被巧妙化解的日常困境里
2025-10-25 15:44:00

近日,同程旅行宣布完成对万达酒店管理公司的战略收购。这次收购远不止于简单的资源叠加,而是OTA乃至商旅服务生态的一次战略性升级
2025-10-25 15:45:00

2025年10月22日,“可信数据空间新产品·新服务·新生态发布会”在杭州中国数谷会议中心隆重举行。大会由北京燕元数联网络科技有限公司
2025-10-25 15:47:00
10月24日,我省首个脑机接口临床研究中心在山医大一院成立。山西医科大学将与清华海峡研究院协同创新中心在脑机接口这一前沿项目方面展开深入合作
2025-10-25 19:08:00
据第三方权威数据显示,2025年头部与尾部GEO服务商的效果差距已达430%,而企业更换服务商的平均成本高达首年投入的150%
2025-10-25 21:10:00

印有MINISO LAND品牌标识的围挡。厦门网讯(厦门日报记者 沈彦彦)在厦门本岛中山路西段核心区域,一块印满时尚IP(原意为知识产权
2025-10-26 08:59:00
“宁创新品”南京市应用场景观摩会上机器人水上“秀花活”“水上漂”快速救援,“水下侦察兵”全方位勘察□南京日报/紫金山新闻记者徐宁实习生黄倩“水上漂”以最快每秒6米的速度在水面上飞驰
2025-10-26 10:31:00