- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...要对是否响应以及如何响应请求做出细微差别。如果说明不够明确,注释者可能不得不依赖个人偏见,从而导致超出预期的模型行为,如变得过于谨慎,或以不理想的风格(如评判)做出响应。例如,在 OpenAI 的一次实验中,一...……更多
2024-07-26 09:35:00不够,奖励,机制,设计,模型,安全

...模型解决复杂问题的能力,尤其是在 o1 所采用的细粒度奖励机制的加持下。这种奖励机制为模型的每一步推理提供细粒度的反馈,而不仅是依赖最终答案的正确性来评估模型的表现。通过精细化的控制,使模型能够不断优化其...……更多
2024-10-26 09:48:00算法,奖励,理念,问题,技术,模型

...penAI 安全团队发布了一项新的研究成果,发现基于规则的奖励可用于提升语言模型的安全性。这不由得让人想到了科幻作家艾萨克・阿西莫夫提出的「机器人三定律」和作为补充的「机器人第零定律」,这就相当于用自然语言给...……更多
2024-11-07 09:54:00定律,机器人,模型,规则,机器,安全

...他看来,未来世界模型需要新的算法机制,应该更加关注奖励组合的设计,不仅包括外部环境给予的奖励,也包含模拟对于人类追寻好奇心的内部奖励。通过奖励机制组合优化模型不仅能让模型追寻外部目标,也能让AI理解科学...……更多
2024-07-08 09:54:00爱因斯坦,智能,人工智能,人工,科学,人工智能

...费将自动转换为购买CMC,并通过销毁代币方式实现CMC算力奖励。这一机制不仅简化了上币流程,还增加了CMC的市场需求,确保了其价值的持续增长。此外,持有一定数量CMC的经纪人可以解锁IEO白名单特权,获得参与优质项目初始...……更多
2024-06-12 15:35:00交易所,极致,模型,哲学,交易,设计

...性,激励社区成员积极参与价值建设。25%生态发展(算力奖励):这部分代币直接打入黑洞地址,换成算力作为奖励支持生态发展,促进社区成员的参与和贡献。10%社区建设(算力奖励):用于鼓励社区新成员参与,部分代币作...……更多
2024-06-18 13:30:00一文,台币,交易所,交易,代币,交易

...励社区成员积极参与CMC价值建设。25%用于生态发展(算力奖励),这些代币将作为原生代币打入黑洞地址,换成算力支持生态发展。生态的算力奖励的目标是促进社区成员的参与和贡献,以推动项目的发展和完善。10%用于社区建...……更多
2024-06-14 17:28:00币种,交易所,初衷,对话,交易,代币

【新智元导读】Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。LLM对数据的大量消耗,不仅体现在预训练语料上,还体现在RLHF、DPO等对齐阶段...……更多
2024-08-01 09:40:00三角,进化,模型,奖励,训练,迭代

...」。
训练时,AI agent在环境中不断观察并行动,并得到奖励模型的反馈进行自我改进。但比较特别的是,奖励函数是由拟合人类反馈得到的。2019年,这项技术被用到了NLP领域,用于微调语言模型。论文地址:https://arxiv.org/abs/190...……更多
2024-08-10 13:48:00后腿,秘方,人类,奖励,模型,学习

...境,它需要做出一系列动作或决策,以最大化从环境获得的奖励。这种概念贯穿于我们的日常生活,比如一个人从A点开车到B点,他需要在每个路口做出正确的转向、刹车等决策,以最小化行驶时间(即最大化奖励)。在训练小狗的场景中...……更多
2024-04-22 11:37:00分布式,高品质,实践,亚马,亚马逊,训练

...jianguanthu.github.io/
AI Agent 的「三大短板」:为什么它们还不够「聪明」?想让 AI Agent 真正胜任助手角色,仅有海量知识是远远不够的。研究团队通过深入分析发现,当前 AI Agent 普遍存在三大短板:黑盒思维」:与优秀人类助手...……更多
2024-12-11 09:53:00清华,学徒,蚂蚁,不够,团队,怎么办

...器则是为了最大化这个值,即当前策略和最优策略之间的奖励之差为:在纳什均衡下,之前已有研究表明:
然而,如果无法获得真正的最优策略,就必须近似后悔值。利用随机策略和奖励信号,该团队设计了基于优势的代理函...……更多
2024-11-06 09:44:00框架,人类,问题,提示,策略,模型
...0万美元的比特币、BAYCNFT和5天的豪华假期等。这种创新的奖励模式吸引了大量玩家的关注和参与,让他们争夺属于他们的幸运时刻。二、解密幸运方块LuckyBlock的财富奥秘幸运方块LuckyBlock的幸运方块机制背后,是一套经过精心设...……更多
2024-02-22 15:11:00加密,幸运,方块,奥秘,财富,方块
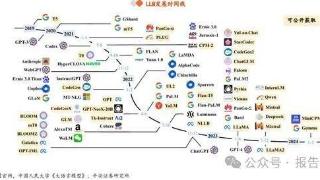
...的结果反馈给模型,让模型从两种反馈模式——人类评价奖励和环境奖励中学习策略,对模型进行持续迭代式微调。GPT-4系列:能力跃升,增加多模态能力,最新版4o突破性价比GPT系列模型的技术演变(GPT-4~GPT-4o):继ChatGPT后,O...……更多
2024-10-21 10:03:00模型,行业报告,新纪元,报告,发展,行业

...模型自身,当模型自身无法准确分辨偏好、所具有的知识不够强大的时候,它所提供的反馈可能不够精准或者没用导致所更新的模型的分布无法向着目标分布更新。为了解决上述问题,来自UNC ,芝加哥大学,UMD和罗格斯大学的研...……更多
2024-06-21 09:21:00模态,美国,瓶颈,顶尖,模型,团队

...例且实际完成合同额超过2000万元的,予以一次性100万元奖励。(责任单位:新一代信息技术产业专班)4.加强核心技术攻关。支持前沿性、颠覆性技术研究,鼓励企业面向大模型基础架构、关键算法、数据技术、人工智能芯片、...……更多
2024-03-29 16:42:00开区,高地,北京,产业,人工智能,智能
...贷”、房屋销售、土地出让、政府采购、资金扶持、表彰奖励等工作上的深度应用。3.加强信用评价模型的后续研发和保障。建立“政用产学研”创新合作工作机制,以信用主体为中心,以行政需求和市场需求为导向,持续开展...……更多
2023-02-23 09:00:00沈阳市,沈阳,信用评价,模型,运行,信用

济宁太白湖新区聚焦事业单位绩效工资管理存在的方案不够科学、程序不够严谨、落实不够到位、监督不够精准等突出问题,不断优化绩效工资管理机制,激发事业单位人员干事创业活力动力。突出“整体把控”,抓好顶层设...……更多
2024-10-24 15:37:00太白,干事,绩效,新区,事业单位,热情
...二级单位予以表扬。采取约谈问责机制。对宣传教育重视不够、落实不到位、发案率较高的二级单位主要负责人,由学校分管领导正式约谈。 ……更多
2023-10-16 11:39:00潍坊,校园建设,平安,机制,校园,建设

...成的评论,令初始模型针对自身的 response 进行修正。3. 奖励建模:将修正后的 response 与原先的 response 拼接,组成偏序对,进行奖励建模,或是 DPO 微调。4. 强化学习微调:基于训练好的奖励模型,完成完整的强化学习微调流程...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据
...“先进优先”的原则评选推荐,荣誉表彰的激励效应释放不够及时也不够充分。为此,该旅党委班子统一思想认识,“谁对战斗力贡献率大谁立功”,下决心立起向战为战的鲜明导向。党委经过反复思考,在全旅内推行“立功即...……更多
2024-01-26 05:27:00激励机制,机制,党委,二等功,一名,荣誉
...不认可管理层制定的标准,可能是他们的意愿或者主动性不够,也可能是服务能力不足;三是服务的需求与供给不相匹配。针对差距3产生的原因,可以从3个方面加以解决:一是重视服务的真实瞬间。真实瞬间是指游客在与服务...……更多
2024-05-08 06:54:00民宿,模型,质量,服务,民宿,服务

...智能应用示范场景,对入选场景给予最高100万元的一次性奖励。建立人工智能技术应用场景项目库,支持企业参评省级“百个人工智能典型应用场景”,争取省级相关补助;支持企业应用人工智能技术,在研发设计、生产制造、...……更多
2024-03-30 08:39:00人形,机器人,机器,规模,应用,人工智能

...指出,目前Sora可以用来解决一些创意辅助的场景,但是不够可靠,所以应用的场景是受限的。OpenAI公司坦承,目前Sora模型也有弱点。它可能难以准确模拟复杂场景的物理特性,且可能无法理解因果关系。例如,该系统最近生成...……更多
2024-03-02 10:00:00场景,不够,应用,生成,视频,模型

...一个 token 的预测损失是有依据的,但与下游的使用情况不够一致,而且无法推断出训练数据之外的情况。根据定义,人类的偏好是一致的,但却阻碍了在封闭系统中的学习。将这种偏好缓存到已学习的奖励模型中会使其自成一...……更多
2024-12-03 13:34:00用语,模型,限制,数据,智能,苏格拉底

...价、贷后管理等整个贷款决策流程中,每个环节均按照“奖励诚信、惩戒失信”的原则设计多维度评价模型;另一方面明确了在完成走访排查的八类灰名单人员后,客户经理不承担责任,按照推广户数及金额逐笔计酬。陈才康 ……更多
2023-11-05 06:05:00普惠,农贷,金融,农贷,申请人,兴化
...件、资源禀赋、历史机遇等原因,我国粮食生产区域格局不够平衡。2023年,13个粮食主产省(区)产量合计10834亿斤,占全国77.9%。7个主销省(市)产量合计597亿斤,占全国4.3%,需要大量调入粮食。一出一入,构成了国家粮食安...……更多
2024-03-07 14:40:00省际,主产区,横向,积极性,粮食,补偿

...通过与环境的交互,不断调整和优化策略以获得最大化的奖励。然而,现实环境中的风险与不确定性往往导致严重的安全问题。例如,在自动驾驶中,车辆不能因为探索策略而危及乘客的安全;在推荐系统中,推荐的内容不能带...……更多
2024-10-09 09:51:00同济,学习方法,深度,理论,方法,应用

...向记者表示:“我认为目前AI发展仅实现了有管理是远远不够,如何实现可管理,即有序、有效的,是当前面临的核心挑战。”那如何尽量规避这个问题,邹江兴说:“这就必须做到发展和治理两手都要硬,齐抓共管,不能滞后...……更多
2023-11-08 17:05:00科学,变革,范式,顶尖,科学研究,科学家

...格式、方法或超参数可带来改进。
阶段四:具有可验证奖励的强化学习。Ai2 引入了一个新的基于强化学习的后训练阶段,该阶段通过可验证奖励(而不是传统 RLHF PPO 训练中常见的奖励模型)来训练模型。他们选择了结果可验...……更多
2024-11-26 09:44:00模型,性能,训练,模型,训练,数据
更多关于科技的资讯:

2月15日消息,据国外媒体报道称,俄罗斯打算转让自己的技术,让印度可以自行生产苏-57战斗机。报道中提到,俄方提议可以在印度生产苏-57战斗机
2025-02-15 16:53:00

2月15日消息,《美国队长4》豆瓣开分仅5.4分。截至发稿,共有14336人进行了打分,其中超过83%的观众给出了3星及以下评价
2025-02-15 16:53:00

当璀璨烟花点亮守岁夜空,当万家灯火映照团圆笑靥,亿万中华儿女正通过智能大屏共享这场年度文化盛宴。2025年中央广播电视总台春节联欢晚会的璀璨舞台上
2025-02-15 16:56:00

快科技2月15日消息,今天OPPO宣布,旗下首款磁吸编织数据线将于2月20日19点发布。这款数据线采用磁吸设计,长度1米
2025-02-15 17:23:00

在中国教育领域,高考始终是一个无法回避的话题。每年六月,这场考试都牵动着数百万家庭的心。然而,在108度公益基金会叶锋博士看来
2025-02-15 18:11:00

快科技2月15日消息,在情人节当天,何小鹏来到民政局当证婚人,现场见证三对小鹏MONA车主领证结婚,何小鹏还送上祝福:祝愿他们夫妻恩爱
2025-02-15 18:23:00

中新经纬2月15日电 (林琬斯)“00后”周键脱下智能仿生手后,中新经纬看到,他穿戴的接受腔(连接身体和假肢的部分)内
2025-02-15 18:49:00

快科技2月15日消息,近日,网络上又现“迷惑行为”新例。起初,众人还以为是有人不慎被“封印”,未曾想竟是在网上流行起来的“塑料凳套头”挑战
2025-02-15 18:53:00

2月15日消息,据国内媒体报道称,我国外交部长王毅最近的发言中,引用了多句中国古语,其中还包括中国武侠泰斗金庸先生在小说里曾写到的两句话
2025-02-15 18:53:00

快科技2月15日消息,博主定焦数码爆料,华为Pocket 3预计在3月底4月初登场,这款新品将会和华为智能手表一起发布
2025-02-15 19:23:00

2月15日消息,据媒体报道,北京卫视正在重播电视剧《甄嬛传》,有网友发帖称,余莺儿相关戏份被剪掉。据了解,《甄嬛传》余莺儿扮演者崔漫莉自曝曾在横店镇拍戏时
2025-02-15 19:23:00

快科技2月15日消息,在第二届中国全固态电池创新发展高峰论坛上,深圳市比亚迪锂电池有限公司CTO孙华军进行了发言。孙华军透露称
2025-02-15 19:53:00

快科技2月15日消息,据媒体报道,南京医科大学一项观察性研究提示,对于工作日睡眠不足的人来说,周末补觉是正确之举,可能有助降低心血管疾病风险
2025-02-15 19:53:00

2月15日消息,据媒体报道,因《哪吒2》爆火,coser们开始模仿电影中的角色,甚至能看到coser模仿导演饺子。对此
2025-02-15 19:53:00

2月15日消息,据国内媒体报道称,近日海南一男子骑电动摩托车极速过路口,被汽车撞飞,但他仍然要负全责。公安部交通管理局社交账号近日公布一则视频
2025-02-15 19:53:00