- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
机器人迈向ChatGPT时刻!清华团队首次发现具身智能Scaling Laws

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
想象这样一个场景:你正在火锅店和朋友畅聊,一个机器人熟练地为你倒饮料、端菜,完全不需要你分心招呼服务员。这个听起来像科幻的场景,已经被清华大学交叉信息院的研究者们变成了现实!他们发现了具身智能领域的 “圣杯”——data scaling laws,让机器人实现了真正的零样本泛化,可以无需任何微调就能泛化到全新的场景和物体。这一突破性发现,很可能成为机器人领域的 “ChatGPT 时刻”,彻底改变我们开发通用机器人的方式!

视频链接:https://mp.weixin.qq.com/s/hJjE_C3KMn7gKjIvfXMhGg
从火锅店到电梯,机器人展现惊人泛化力
研究团队可不是只在实验室里玩玩具。他们把机器人带到了各种真实场景:火锅店、咖啡厅、公园、喷泉旁,甚至是电梯里。更令人震惊的是,机器人在这些前所未见的环境中都展现出了超强的适应能力!

视频链接:https://mp.weixin.qq.com/s/hJjE_C3KMn7gKjIvfXMhGg
为了确保研究的可复现性,团队慷慨地开源了所有资源,包括耗时半年收集的海量人类演示数据:

论文标题:Data Scaling Laws in Imitation Learning for Robotic Manipulation 论文链接:https://arxiv.org/abs/2410.18647 项目主页:https://data-scaling-laws.github.io/
连 Google DeepMind 的机器人专家 Ted Xiao 都忍不住为这项研究点赞,称其对机器人大模型时代具有里程碑意义!
Scaling Laws:从 ChatGPT 到机器人的制胜法则
还记得 ChatGPT 为什么能横空出世吗?答案就是 scaling laws!现在,清华团队首次证明:这个法则在机器人领域同样适用。事实上,真正的 scaling laws 包含数据、模型和算力三个维度,而本研究重点突破了最基础也最关键的数据维度。

视频链接:https://mp.weixin.qq.com/s/hJjE_C3KMn7gKjIvfXMhGg
研究团队使用便携式手持夹爪 UMI,在真实环境中收集了超过 4 万条人类演示数据。他们采用最新的 Diffusion Policy 方法从这些数据中学习机器人控制模型,并通过惊人的 15000 + 次实机测试进行严谨评估,最终发现了三个革命性的幂律关系:
模型对新物体的泛化能力与训练「物体」数量呈幂律关系。 模型对新环境的泛化能力与训练「环境」数量呈幂律关系。 模型对环境 - 物体组合的泛化能力与训练「环境 - 物体对」的数量呈幂律关系。
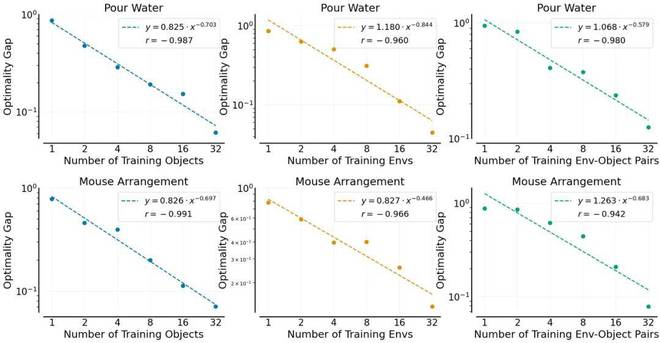
这意味着什么?简单说:只要有足够的数据,机器人就能像 ChatGPT 理解语言一样,自然地理解和适应物理世界!这一发现不仅证实了机器人领域与语言模型存在惊人的相似性,更为预测数据规模与模型性能的关系提供了坚实的理论基础。
颠覆性发现:数据收集原来要这么做!
研究团队还破解了一个困扰业界的难题:对于给定的操作任务,如何优化选择环境数量、物体数量和每个物体的演示次数?
经过大量实验,他们得出了两个出人意料的结论:
1. 当环境数量足够多时,在单一环境中收集多个不同的操作物体的数据收益极其有限 —— 换句话说,每个环境只需要一个操作物体的数据就够了。
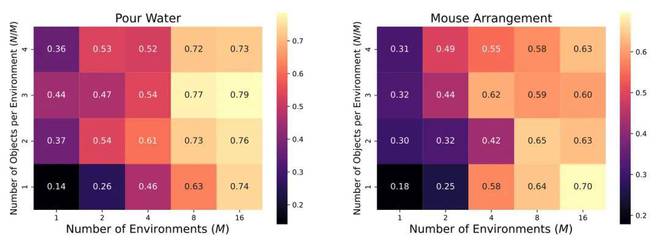
2. 单个物体的演示数据很容易达到饱和 —— 在倒水和摆放鼠标等任务中,总演示数据达到 800 次时,性能就开始趋于稳定。因此,每个物体 50 次示范基本就能搞定。
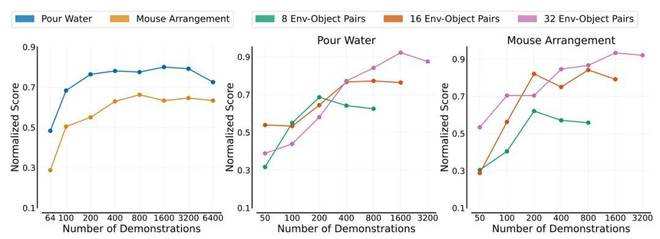
为验证这个策略,团队找来 4 个人,只花了一个下午就收集到了训练数据。结果令人震惊:在 8 个全新场景中,机器人成功率高达 90%!这意味着,原本可能需要几个月的数据收集工作,现在可能只需要几天就能完成!
模型规模化探索的意外发现
除了数据规模,研究团队还在模型规模化方面有三个重要发现:
视觉编码器必须经过预训练和完整的微调,缺一不可 扩大视觉编码器的规模能显著提升性能 最令人意外的是:扩大扩散模型的规模却没能带来明显的性能提升,这一现象还值得深入研究

未来展望
数据规模化正在推动机器人技术走向新纪元。但研究团队提醒:比起盲目增加数据量,提升数据质量可能更为重要。关键问题在于:
如何确定真正需要扩展的数据类型? 如何最高效地获取这些高质量数据?
这些都是 Data Scaling Laws 研究正在积极探索的方向。相信在不久的将来,具有超强适应力的机器人将走进千家万户,让科幻电影中的场景变为现实!而这一切,都将从清华团队发现的这个基础性规律开始!
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2024-11-04 12:45:01
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址:


















