- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
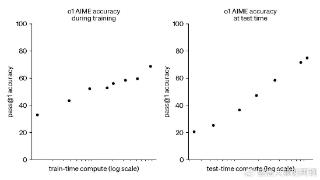
...二、社会评测与同行水平社会评测普遍认可o1 系列模型的逻辑推理能力优于 GPT-4o,但也有很多人提出了不同看法。差评XPIN邀请了理综三科的博士测评,物理评价较高,而生物、化学评价较低,综合认为o1在认知上达到硕士水平...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力
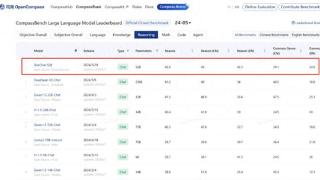
...一在今年5月的 OpenCampass 测试榜单中,TeleChat 系列模型的逻辑推理能力名列开源大模型榜单第一。作为新一代版本,TeleChat2-115B 在9月最新公布的 C-Eval 评测 Open Access 模型综合榜单中,以 86.9 分的成绩排名第一。其通用能力较 Tele……更多
2024-09-30 09:50:00万卡,重磅,模型,国产,训练,模型

...一代“天工2.0”MoE大模型,“天工3.0”在模型语义理解、逻辑推理、以及通用性、泛化性、不确定性知识、学习能力等领域拥有惊人的性能提升,其模型技术知识能力提升超过20%,数学/推理/代码/文创能力提升超过30%。同时,“...……更多
2024-04-01 19:56:00万维,昆仑,模型,将于,同步,参数

...概念,提高了大语言模型(LLM,large language models)在复杂推理任务上的性能,例如算术推理、常识推理和符号推理等。图 | 金明宇(来源:金明宇)CoT 的原理是通过提供推理过程的示例,来教会模型处理推理,详细说明导致最...……更多
2024-03-15 10:41:00罗格,罗格斯,推理,模型,团队,概念

...度30个二级维度。报告称SenseChat-Vision 5.5在基础能力-数理逻辑推理任务如图表推理、场景推理方面具备领先优势。榜单显示,在数理逻辑分析能力中,SenseChat-Vision 5.5超越国内外所有参评模型包括GPT-4o的最新版本,位列第一。Super...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力
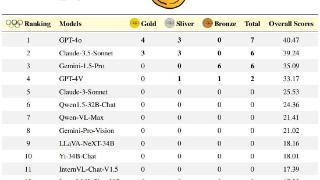
...竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...,尽管这些模型在处理自然语言方面表现卓越,但在复杂逻辑推理任务中,人类和语言模型都会受到语义内容合理性和可信度的影响,表现出类似的错误倾向。研究背景人类在推理过程中存在两种系统:“直觉系统”和“理性系...……更多
2024-08-19 13:49:00局限性,推理,人类,任务,研究,模型

...看看DoT长啥样。大模型复杂推理新框架
如前所述,DoT将逻辑推理过程建模为在单个LLM内构建有向无环图(DAG)。其框架内部管理三个关键角色:提议者:生成命题或推理步骤,添加新节点。
批评者:评估命题,识别错误、不...……更多
2024-09-24 13:36:00维图,院士,逻辑,模型,一致,理论

...地依赖于训练数据中的模式进行预测。当需要进行真正的逻辑推理时,这些模型往往无法产生合理的结果,这一发现对人工智能的发展提供了重要的参考。虽然LLM在许多领域表现优异,但其推理能力仍有待改进。【本文结束】如...……更多
2024-10-13 14:15:00逻辑推理,新论,推理,缺陷,逻辑,模型
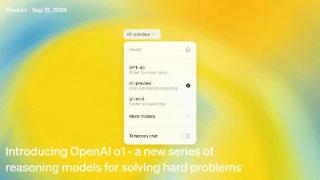
...凌晨1时许,AI时代迎来崭新的起点——能够进行通用复杂推理的大模型终于走到台前。OpenAI在官网发布公告称,开始向全体订阅用户开始推送OpenAI o1预览模型——也就是此前被广泛期待的“草莓”大模型。OpenAI表示,对于复杂推...……更多
2024-09-13 13:34:00新时代,推理,逻辑,模型,模型,问题

...外籍院士沈向洋在会上发表主旨演讲,发布IDEA研究院的重磅研产结晶与市场化成果;在大咖云集的论坛环节,多位领军科学家、企业家、创业者同台论道,碰撞“学研产投”灵感。2023年,AI技术给人类生活带来撼动,一个个看...……更多
2023-11-24 10:53:00模型,大会,问题,模型,研究,能力
...个只有8%。研究人员根据答案是否正确以及答案所包含的逻辑推理是否有效,对大语言模型的答案进行了分类。实验的第一个结果是,在每个测试重复十次的情况下,答案是不一致的。例如,在同一个测试中,有的模型十次中答...……更多
2024-06-12 18:15:00逻辑推理,推理,逻辑,模型,语言,模型

...个版本Claude 3.5 Sonnet。从官方披露的测试数据来看,其在逻辑推理、编程、数学等方面中的表现性能均超越GPT-4o。网友直言,“太卷了,现在AI竞争是要以周为单位了吗?”
从官方介绍来看,Claude 3.5全家桶仍会有3款系列模型,...……更多
2024-06-21 11:50:00逻辑推理,推理,逻辑,视觉,方面,模型

...,是全球最大的开源MoE大模型。「天工3.0」在语义理解、逻辑推理、通用性、泛化性、不确定性知识、学习能力等领域拥有突破性的性能提升,数学/推理/代码/文创能力提升超过30%。 (天工3.0模型参数超越Grok-1,成全球最大开...……更多
2024-04-17 15:31:00天工,公测,模型,音乐,中国,天工
...提供深度洞察。系统能够理解复杂的上下文关系,并通过逻辑推理为用户提供高质量的解决方案,做更懂你、更省心、更精准的AI搜索。推理能力的跨越式提升,离不开数据和信源检索技术的升级。在数据上,天工AI投入了巨大...……更多
2024-11-05 14:56:00天工,万维,昆仑,科研学术,搜索,重磅
大模型预训练“缩放定律”定律失效?模型推理成“解药”,英伟达一家独大格局要变天?“缩放定律”指导下,AI大模型预训练目前遭遇瓶颈。据路透12日报道,硅谷主要AI实验室的新模型训练计划目前普遍进展不顺,新模型...……更多
2024-11-13 14:09:00英伟,争论,逻辑,意味,根本,策略

...23 年 2 月。当时,已经有一些研究团队开始使用大模型做逻辑推理和数学推理。赵子龙和合作者也认为这个方向很有前景。他表示让自己印象最深的例子就是 OpenAI 网站上的一道数学推理的题: Simplify tan100 + 4sin100。根据 OpenAI 自...……更多
2024-03-13 10:26:00数学,数学题,科学家,模型,辅导,课程

...地,也一定要对时间、数字和逻辑敏感,无论让它做多跳推理,还是逻辑规则数字计算,而这些恰好是大语言模型所不擅长的,包括前一段时间热议的 9.9 和 9.12 比大小的例子。基于此,我们认为在垂直领域落地的时候,大语言...……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型
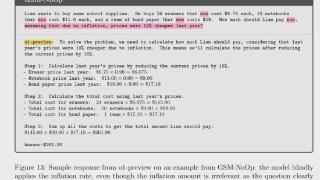
...降。我们假设这种下降是因为当前的 LLM 无法进行真正的逻辑推理;相反,它们试图复制在训练数据中观察到的推理步骤。」这一结论得到了 Keras 之父 François Chollet 和美国心理学家、认知科学家 Gary Marcus 的转发,他们一直对 AI ...……更多
2024-10-14 09:55:00数学题,推理,废话,苹果,数学,小学

...一定启示。日前,相关论文以《大型语言模型评价中的元推理革命》(MR-GSM8K: A Meta-Reasoning Revolution in Large Language Model Evaluation)为题发在 arXiv,曾忠燊是第一作者,香港中文大学教授贾佳亚担任通讯作者 [1]。图……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...语言处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan3还突破“迭代式强化学习”...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

...出现的松鼠。这类游戏的逻辑相对复杂,更考验OpenAI o1的逻辑推理能力。官方还表示,相较于GPT-4o等现有的大模型,OpenAI o1能够解决更加困难的推理问题,同时改善过往模型中存在的机制性缺陷。比如在解答编程问题时也会更有...……更多
2024-09-14 10:18:00博士生,水准,模型,博士,推理,模型

...读理解和问答等任务中取得了极高的性能,但这些模型在逻辑推理方面的性能仍然十分滞后。去年5月「思维链」(ChainofThought,CoT)横空出世,有研究人员发现,只需要在prompt中加入「Let\'sthinkstepbystep」就能让GPT-3的推理性能大幅...……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标

...不足,腾讯还特别强化了模型在高质量文本创作、数学和逻辑推理等方面的能力。
文本创作能力的显著提升在文本创作领域,大多数大模型表现平平,尤其在专业写作方面,常常缺乏足够的灵活性和精准度。混元Turbo在这方面...……更多
2024-09-14 14:04:00金鼎,腾讯,模型,腾讯,模型,推理

...市场拱手让人。另一方面,随着大模型产业的快速发展,推理成本飞速下降,也成为终端降价的基础。据百度官方透露,相比一年前,文心大模型的算法训练效率提升到了原来的5.1倍,周均训练有效率达到98.8%,推理性能提升了1...……更多
2024-05-29 09:29:00模型,逻辑,背后,国产,竞争,模型

...势以外,CoE模型在其余11项指标上均优于GPT-4o,特别是「逻辑推理」、「多步推理」、「诗词赏析」这类比较具有中文特色的问题,CoE的领先优势更加明显。目前,360的「多模型协作」已经能打败并远远甩开GPT-4o,媲美o1-preview。...……更多
2024-09-21 09:50:00周鸿,前瞻,应用,模型,推理,协作
...我们需要结合快思考的‘黑盒’预测和慢思考的‘白盒’逻辑推理,打造‘灰盒’可信大模型。具体而言,通过融合科学规律、观测数据和合成数据,开发理解物理世界的垂直领域科学大模型。”作为本届大赛评委会主席,上智...……更多
2024-07-05 14:45:00第二届,招募,选手,大赛,智能,科学

...、多维度的综合性测评基准,由十大基础任务组成,包括逻辑推理、代码、语言理解、长文本、角色扮演等。本次报告选取了国内外具有代表性的32个大模型4月份的版本,通过多维度综合性测评,真实准确地反映了国内外大模型...……更多
2024-05-06 16:52:00腾讯,梯队,模型,腾讯,模型,能力

...水平(图中0.0边界)甚至超越,其中不乏非常有挑战性的逻辑推理任务,比如需要复杂多步骤推理的BBH(Big-Bench Hard)和数学应用题测试集GSK8k。其中的HellaSwag测试集,由华盛顿大学和Allen AI在2019年推出,专门针对人类擅长但LLM...……更多
2024-07-01 08:58:00菲尔,得主,难题,经典,农夫,模型

...力一直是大模型的痛点,理科领域需要高度的抽象思维和逻辑推理能力,并且要求非常精准的答案,作为计算机科学和信息技术领域的重要工具,代码能力被视作衡量大模型智慧的关键维度。事实上,在过去一年国产大模型如火...……更多
2024-04-12 15:11:00商汤,办公,补强,金山,办公软件,理科
更多关于科技的资讯:

一、日本顶级新闻媒体概述日本拥有众多在全球具有影响力的新闻媒体,涵盖电视台、通讯社、报纸等多个领域。其中,NHK(日本放送协会)作为公共媒体
2024-11-21 21:57:00

你有没有想过,在我们享受便捷生活的同时,还有许多残障人士、老年人等特殊群体在日常生活中面临着重重障碍,而科技,特别是 AI
2024-11-21 22:31:00
近日,由江苏省消费者权益保护委员会指导、南京市消费者协会主办的“‘提升消费者满意度’2024年南京金融业服务满意与创新发展年度活动”成功举办
2024-11-21 22:37:00
兴业银行零售科技协调工作组在会议中指出,零售条线业务要在经营活动层面贯彻落实总行党委“三基”“三化”管理要求。今年7月至10月
2024-11-21 22:44:00

在2024年世界互联网大会乌镇峰会期间,云上贵州大数据(集团)有限公司(下称“贵州大数据集团”)携六大核心业务首次亮相
2024-11-21 23:12:00

本文转自:人民网全国政协委员、中国网络空间安全协会理事长赵泽良发言。主办方供图人民网桐乡11月21日电 (记者赵竹青)11月21日
2024-11-22 00:11:00
本文转自:人民日报海外版《 人民日报海外版 》( 2024年11月22日 第 11 版)据新华社 (记者孟含琪)记者近日从中国科学院长春光学精密机械与物理研究所了解到
2024-11-22 04:36:00

人人都希望获得香港身份。无论是为了子女的教育规划,还是个人的未来发展,拥有香港身份都带来了诸多优势。那么,如何挑选一个靠谱的中介来申请香港身份呢
2024-11-21 18:17:00

快科技11月21日消息,据中国航天科技集团,该集团五院研制的充气式柔性密封舱,伴随实践十九号卫星完成了在轨飞行试验,任务取得圆满成功
2024-11-21 18:26:00

快科技11月21日消息,乐道汽车总裁艾铁成近日通过微博宣布,2025年乐道品牌将推出两款新车型,包括一款六座/七座旗舰SUV和一款大五座SUV
2024-11-21 18:26:00
快科技11月21日消息,日前,有车主发布了一段上汽飞凡车主怒砸充电盖的视频,引起网友热议。视频中,一辆黑色的飞凡F7电动车在行驶中出现了充电盖板故障
2024-11-21 18:26:00

快科技11月21日消息,用户脚本管理应用篡改猴(Tampermonkey)上架苹果App Store,售价为2.99美元(约合21
2024-11-21 18:56:00

北京时间2024年11月15日23时13分,天舟八号货运飞船在我国文昌航天发射场点火起飞,南京航空航天大学李广侠团队研制的“基于天基计算的地面辐射源在轨定位试验载荷”——星眸载荷
2024-11-21 18:56:00

北京时间11月21日,英伟达公布2025财年第三季度财报。英伟达第三季度营收351亿美元,同比增长93.7%。第三季度净利润193
2024-11-21 18:56:00

快科技11月21日消息,百度集团发布了2024年第三季度的财务报告,显示公司总营收达到336亿元人民币,净利润为75.4亿元人民币
2024-11-21 18:56:00