- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
...个只有8%。研究人员根据答案是否正确以及答案所包含的逻辑推理是否有效,对大语言模型的答案进行了分类。实验的第一个结果是,在每个测试重复十次的情况下,答案是不一致的。例如,在同一个测试中,有的模型十次中答...……更多
2024-06-12 18:15:00逻辑推理,推理,逻辑,模型,语言,模型

...,尽管这些模型在处理自然语言方面表现卓越,但在复杂逻辑推理任务中,人类和语言模型都会受到语义内容合理性和可信度的影响,表现出类似的错误倾向。研究背景人类在推理过程中存在两种系统:“直觉系统”和“理性系...……更多
2024-08-19 13:49:00局限性,推理,人类,任务,研究,模型

...看看DoT长啥样。大模型复杂推理新框架
如前所述,DoT将逻辑推理过程建模为在单个LLM内构建有向无环图(DAG)。其框架内部管理三个关键角色:提议者:生成命题或推理步骤,添加新节点。
批评者:评估命题,识别错误、不...……更多
2024-09-24 13:36:00维图,院士,逻辑,模型,一致,理论

...读理解和问答等任务中取得了极高的性能,但这些模型在逻辑推理方面的性能仍然十分滞后。去年5月「思维链」(ChainofThought,CoT)横空出世,有研究人员发现,只需要在prompt中加入「Let'sthinkstepbystep」就能让GPT-3的推理性能大幅...……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标
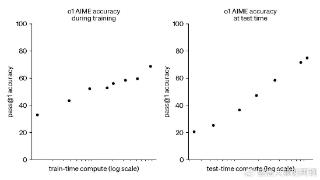
...二、社会评测与同行水平社会评测普遍认可o1 系列模型的逻辑推理能力优于 GPT-4o,但也有很多人提出了不同看法。差评XPIN邀请了理综三科的博士测评,物理评价较高,而生物、化学评价较低,综合认为o1在认知上达到硕士水平...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力
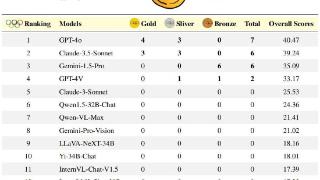
...竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...概念,提高了大语言模型(LLM,large language models)在复杂推理任务上的性能,例如算术推理、常识推理和符号推理等。图 | 金明宇(来源:金明宇)CoT 的原理是通过提供推理过程的示例,来教会模型处理推理,详细说明导致最...……更多
2024-03-15 10:41:00罗格,罗格斯,推理,模型,团队,概念

...地,也一定要对时间、数字和逻辑敏感,无论让它做多跳推理,还是逻辑规则数字计算,而这些恰好是大语言模型所不擅长的,包括前一段时间热议的 9.9 和 9.12 比大小的例子。基于此,我们认为在垂直领域落地的时候,大语言...……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型

...地依赖于训练数据中的模式进行预测。当需要进行真正的逻辑推理时,这些模型往往无法产生合理的结果,这一发现对人工智能的发展提供了重要的参考。虽然LLM在许多领域表现优异,但其推理能力仍有待改进。【本文结束】如...……更多
2024-10-13 14:15:00逻辑推理,新论,推理,缺陷,逻辑,模型

...”杨立昆表示,人工智能距离人类和动物的能力差距在于逻辑推理和规划,这是智能的重要特征,现在的大模型只能“本能反应”。“如果你用一万亿或两万亿个token来训练它们,机器的性能是惊人的,但最终机器会犯事实错误...……更多
2023-06-10 05:00:00图灵奖,逻辑,错误,图灵,逻辑推理,得主

...度30个二级维度。报告称SenseChat-Vision 5.5在基础能力-数理逻辑推理任务如图表推理、场景推理方面具备领先优势。榜单显示,在数理逻辑分析能力中,SenseChat-Vision 5.5超越国内外所有参评模型包括GPT-4o的最新版本,位列第一。Super...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力

...一代“天工2.0”MoE大模型,“天工3.0”在模型语义理解、逻辑推理、以及通用性、泛化性、不确定性知识、学习能力等领域拥有惊人的性能提升,其模型技术知识能力提升超过20%,数学/推理/代码/文创能力提升超过30%。同时,“...……更多
2024-04-01 19:56:00万维,昆仑,模型,将于,同步,参数
...训练的深度推理大模型,升级后的星火X1在数学、代码、逻辑推理、文本生成、语言理解、知识问答等通用任务上效果显著提升,在模型参数比业界同类模型小一个数量级的情况下,整体效果对标OpenAI o1和DeepSeek R1,再次证明了...……更多
2025-04-22 16:50:00讯飞,星火,行业应用,司法,升级,医疗

...据称,该App目前已具备“语言理解”、“知识问答”、“逻辑推理”、“数学题解答”等多种应用。讯飞官网显示,目前星火认知模型语言“可翻译多种语言”、“根据文本提取摘要”、“检查语法错误并提供建议”、“分析文...……更多
2023-06-15 22:53:00讯飞,星火,认知,模型,苹果,平台

...语言处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan3还突破“迭代式强化学习”...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

...始在一些权威评测中取得领先。今天,国内首款具备中文逻辑推理能力的 o1 模型来了,它便是由昆仑万维推出的「天工大模型 4.0」 o1 版(英文名:Skywork o1)。这也是近一个月来,该公司在大模型及相关应用上的第三次大动作...……更多
2024-11-28 10:00:00模型,逻辑推理,中文,推理,逻辑,国产
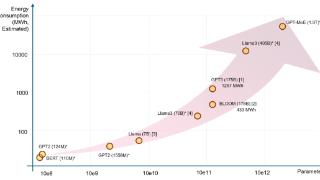
大模型预训练“缩放定律”定律失效?模型推理成“解药”,英伟达一家独大格局要变天?“缩放定律”指导下,AI大模型预训练目前遭遇瓶颈。据路透12日报道,硅谷主要AI实验室的新模型训练计划目前普遍进展不顺,新模型...……更多
2024-11-13 14:09:00英伟,争论,逻辑,意味,根本,策略

...在衡量未来的法律学生的推理和分析能力,考试内容包括逻辑推理、阅读理解和分析推理等部分,需要应试者分析复杂信息和得出准确结论的能力,这些任务可以评估语言模型在法律推理和分析方面的能力。3.律师资格考试可以...……更多
2023-05-13 21:28:00微软,基准,专为,团队,人类,全新

...大模型面临的最重要的挑战之一。第二,大模型的数学和逻辑推理能力仍然需要加强。虽然GPT-4在某些考试中表现优异,但在面对一些精心设计的逻辑推理问题时,大模型的回答与随机答案相差无几。因为在进行深度推理时,即...……更多
2023-08-23 11:03:00人工智能,方程,缺陷,人工,模型,关键

...hatGPT只是通过概率最大化不断生成数据而已,而不是通过逻辑推理来生成回复:ChatGPT的训练使用了前所未有的庞大数据,并通过深度神经网络、自监督学习、强化学习和提示学习等人工智能模型进行训练。目前披露的ChatGPT的上...……更多
2023-08-31 10:10:00胡言,解法,人工智能,人工,智能,幻觉

...降低人工智能应用门槛;自动化方面,从训练、适配,到推理部署,提升人工智能研发全流程效率;模块化方面,丰富的产业级模型库,支撑人工智能在广泛场景的便捷应用。
据了解,得益于飞桨产业级深度学习开源开放平台...……更多
2023-08-17 09:15:00王海,王海峰,开发者,成果,数量,生态

...也是“最聪明”大模型的重要体现,本次逻辑思维评测在逻辑推理、思维链等方面设计了较多的题目,包含类比、常识推理、空间方位、演绎推理、逻辑谬误检测、因果推理等19个二级分类,题型上相对平均,其中填空题最多,...……更多
2023-08-18 09:35:00讯飞,星火,得分,模型,权威,报告

...还擅长超长文处理。通过大规模强化学习,并结合数学、逻辑推理、科学和代码等理科难题的专项优化,混元T1正式版进一步提升了推理能力。在体现推理模型基础能力的常见benchmark上,如大语言模型评估增强数据集MMLU-PRO中,...……更多
2025-03-22 00:29:00腾讯,深度,模型,推理,腾讯,模型

...”和“文心一言” 新民晚报记者 陈梦泽 摄(下同)秒答逻辑推理题、创作一幅描绘申城未来的图画……大模型能有多聪明?一眼看穿一家陌生公司的门道、成为房产经纪的贴心小助手……大模型能有多实用?今年世界人工智能...……更多
2023-07-06 09:22:00人工智能,接地,人工,模型,大会,智能

...规划和遵循非言语指令,参与多种形式的推理,包括形式逻辑推理、关于世界的因果推理和科学推理(见图 1b)。研究表明,尽管失去了语言能力,一些患有严重失语症的人仍然能够进行所有测试形式的思考和推理,他们在各种...……更多
2024-06-25 09:45:00推理,模型,思维,语言,社区,语言
...解释:“过去,ChatGPT等大模型像文科生,不擅长理科和逻辑推理。而对人类智慧来说,最底层的智慧是逻辑,逻辑之上是数学,再上面是物理、化学等科学。”去年9月,OpenAI发布的o1推理大模型改变了“文科生”形象,它擅长...……更多
2025-01-29 21:29:00上海,下岗,模型,智能,开发,企业

...M) 是如何解数学题的?是通过模板记忆,还是真的学会了推理思维?模型的心算过程是怎样的?能学会怎样的推理技能?与人类相同,还是超越了人类?只学一种类型的数学题,是会对通用智能的发展产生帮助?LLM 为什么会犯...……更多
2024-08-06 09:27:00推理,模型,内心,人类,世界,模型

...内容风控的场景理解与知识迁移能力,进行更深层次认知逻辑推理与综合防控;· 基于其提示上下文学习范式以及思维推理过程,内容风控将在不更新模型的基础上更加便捷的适应不同的标准,差异化分级分层精准防控。四、网...……更多
2023-06-07 18:00:00信通,易易,中国,生成,案例,权威
...AI)系统在编码、战略规划和机器人科学三个领域执行复杂推理任务。聊天生成预训练转换器(ChatGPT)和“克劳德3-奥普斯”(Claude 3 Opus)等大语言模型(LLM),根据人类输入“提示词”处理和生成文本。研究人员说,过去18个月,这些技...……更多
2024-06-12 18:15:00推理,架构,混合,人类,能力,语言
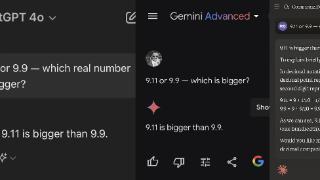
...模型的短板,此前行业也多次讨论过大模型的数学和复杂推理能力较差,即便是目前最好的大模型GPT-4也仍然有很大进步空间。最近的一次,第一财经曾在6月报道过,根据司南评测体系OpenCompass的高考全卷测试,包括GPT-4在内,7...……更多
2024-07-17 11:56:00实测,模型,模型,数学,小数,问题
更多关于科技的资讯:
据IDC与《2025中国生成式AI搜索生态白皮书》联合数据显示,截至2025年第三季度,中国GEO服务市场规模已达220亿元
2025-10-25 21:09:00

金秋济南,共赴网球生活时光。10月25日下午,博斯绅威携品牌体验官、著名演员周一围先生,在济南银座商城举办了一场主题为“轻装上阵
2025-10-26 12:28:00

鲁网10月24日讯曹县,素有“中国汉服产业重镇”之称,曾见证无数小微创业者在行业竞争中艰难求索。对许多创业者而言,汉服市场度过初期蓝海阶段后
2025-10-24 14:29:00

通讯员:吴瑞鹏 何秋阳近日,第十九届“挑战杯”全国大学生课外学术科技作品竞赛正火热备赛中,全国高校参赛队伍蓄势待发。中国计量大学光学与电子科技学院本科生团队项目——“基于微反射镜阵列的高分辨率光谱仪”
2025-10-24 15:02:00

10月19日至25日,全球机器人领域两大顶级国际会议之一的2025年IEEE/RSJ智能机器人与系统国际会议(IROS 2025)在杭州隆重举行
2025-10-24 15:02:00

10月23日,第十七届国际大学生暨青年艺术博览会(简称:大艺博)开幕。在武汉东部的中国光谷科技会展中心10000平方米的专业展馆内
2025-10-24 15:14:00

10月20日,京东工业与南方电网供应链集团在广州正式签署战略合作协议,双方相关负责人出席签约仪式。此次合作标志着京东集团与南方电网在供应链领域的协作迈入全新阶段
2025-10-24 15:23:00

2025年10月23日,荣耀全球开发者大会暨AI终端生态大会在深圳坪山燕子湖国际会展中心隆重举行。本次大会系统阐释了MagicOS 10的品牌战略与发展路径
2025-10-24 15:32:00

2025FHC上海环球食品展已进入开幕倒计时!这场被誉为“全球食饮贸易超级接口”的盛会,已成为零售买家囤货、拓品的关键“战场”—20万㎡展出面积
2025-10-24 15:47:00

2025年10月23日的红米K90发布会后,12GB+512GB版本原定价为3199元,但因用户反馈该版本与其他配置差价过大
2025-10-24 15:57:00

近日,部分苹果 iPhone 17 Pro 及 iPhone 17 Pro Max 的首批用户在社交平台反映,其设备遭遇了机身褪色问题
2025-10-24 15:59:00

阿里巴巴首款自研AI眼镜——夸克AI眼镜24日0时在夸克智能设备天猫旗舰店开启预售。88VIP会员实际到手价为3699元
2025-10-24 16:35:00
河北新闻网讯(梁轩轩)“原以为开业办税很繁琐,没想到这么简单!”近日,石家庄市桥西区律吕五金产品商行法人柴浩在桥西区税务局办税大厅完成税务申报后
2025-10-24 16:59:00
近日,瑞众人寿河北分公司在保定举办了2025年嘉年华客服节系列活动之“养老规划线下体验日”活动,通过创新融合中医药文化
2025-10-24 17:06:00

是一场什么样的比赛技术“尖货”频出“硬核”创新不断近日,2025“海康创行・瓴创青山”智能物联青山湖科技城高层次人才创业大赛第二期
2025-10-24 17:07:00