- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...觉语言、文生图、文生视频、语音语言大模型综合及专项评测结果。智源评测发现,2024年下半年大模型发展更聚焦综合能力提升与实际应用。多模态模型发展迅速,涌现了不少新的厂商与新模型,语言模型发展相对放缓。模型...……更多
2024-12-20 11:22:00评测结果,研究院,评测,结果,研究,模型

...140余个开源和商业闭源的语言及多模态大模型全方位能力评测结果。本次智源评测,分别从主观、客观两个维度考察了语言模型的简单理解、知识运用、推理能力、数学能力、代码能力、任务解决、安全与价值观七大能力;针对...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测

...中使用这些数据,从而让模型对测试内容有所准备,导致评测结果不能真实反映模型的能力。更有甚者会针对特定评测数据集进行过度拟合,使得模型在这个特定的数据集上表现得非常好,但在实际应用中却无法达到同样的性能...……更多
2024-12-23 13:44:00可信度,可信,模型,评测,全球,模型
...度和广度。此外,缺乏统一的评测标准,也让不同机构的评测结果缺乏可比性。林咏华在谈及这一问题时表示,“评测体系的开放性和科学性是关键,要实现统一标准,仍需克服多方利益博弈的障碍。”在林咏华看来,随着技术...……更多
2024-12-26 21:56:00中国,模型,厂商,优势,领域,模型

...情况,并启动了AI安全守护计划,发布了三大类别的安全评测结果。AIIA安全治理委员会成立于2023年12月底,经过半年运营,现有治理组、安全组两个工作组,近百家单位加入,主任单位由中国信通院牵头,副主任单位包括多家知...……更多
2024-07-25 09:26:00安全,信通,模型,评测,委员会,委员

...计意义思考不足,起码会带来以下几个潜在危害:其一,评测结果能否真实反映大模型的能力?如果对此认识不足,往往会过分夸大模型的效果。其二,会让人以为指标的提升,等价于大模型能力的提升、以及等价于真实场景的...……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...达到国家相关标准。该测试由工信部中国电子技术标准化研究院发起,从大模型的通用性、智能性、安全性等多个维度开展,涵盖语言、语音、视觉等多模态领域,旨在建立大模型标准符合性名录,是基于官方大模型测试基准的...……更多
2023-12-26 14:16:00人工智能,国标,人工,模型,结果,智能

...介绍,“大模型标准符合性评测”由中国电子技术标准化研究院发起,旨在建立中国大模型标准符合性名录,引领人工智能产业健康有序发展。该评测对外征集了学术界、产业界几十家头部单位意见,覆盖评估语言大模型通用性...……更多
2023-12-23 15:09:00符合性,模型,评测,标准,官方,模型

...业大模型产品通过。该测试由工信部中国电子技术标准化研究院(简称“工信部电子标准院”)发起,评测围绕多领域多维度模型评测框架与指标体系,从大模型的通用性、智能性、安全性等维度开展,涵盖语言、语音、视觉等...……更多
2023-12-23 15:02:00四家,产品通过,模型,结果,测试,标准
...技术生态、产业生态和开放性等多个维度进行评估,确保评测结果客观真实。此次评测结果将形成针对特定应用场景的综合报告和产品推荐目录,为政府、企业和研究机构建设智算中心提供芯片选型的重要参考和决策依据。在评...……更多
2023-10-23 15:02:00芯片,评测,国产,芯片,评测,人工智能
...。经过微调的对话模型进行了客观、自动化的能力评测,评测结果显示,总分上Tele-FLM完成了对GPT-3.5-Turbo的超越。在分项得分中,Tele-FLM在总共的11个分项中有十项达到或超过GPT-3.5-Turbo水平。仅今年,中国电信人工智能研究院便...……更多
2024-04-30 20:00:00研究院,中国电信,研究,人工智能,中国,人工

本文转自:中国新闻网近日,中国信息通信研究院发布大模型安全基准测试AI Safety Bench 2024年Q1的首轮测评报告(下称“测评报告”),结果显示,三六零集团自研的认知通用大模型360智脑综合排名第一。大模型安全基准测试AI Safet...……更多
2024-04-10 20:16:00信通,基准,中国,模型,测试,报告

...统的安全交互与价值对齐,指导老师为北京大学人工智能研究院杨耀东助理教授。核心成员包括吉嘉铭、周嘉懿、邱天异、陈博远、王恺乐、洪东海、楼翰涛、王旭尧、陈文琦、张钊为、汪明志、钟伊凡等。团队就强化学习方法...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

...型。Gemini/androidayuda据科技媒体《品玩》报道,北京智源研究院副院长林咏华曾透露,当下世界大模型评测C-Eval、MMLU以及CMMLU等几个测评集,已经被各路模型过度训练。一些测评榜单完全可以靠定向的训练数据拔高分数。而不少...……更多
2023-12-20 00:10:00王者,抄袭,模型,万物,公司,数据
...豹研究院发布《2023年中国大模型行研能力评测报告》。评测结果显示,商汤语言大模型“日日新·商量”以总分7.73(满分10分)斩获总榜第一,并在报告撰写能力、模型基础能力两个子榜位居第一。 ……更多
2024-01-13 00:05:00商汤,模型,语言,模型,能力,国大
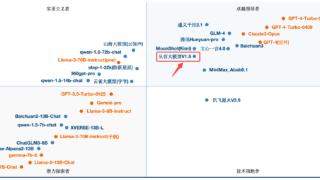
...台OpenCompass的多模态评测领域中也取得了重大进展。最新评测结果显示,从容大模型在该体系中的平均得分为65.5,这一成绩使其跻身全球前三,超越了谷歌的Gemini-1.5-Pro和GPT-4v,仅次于GPT-4o(69.9)和Claude3.5-Sonnet(67.9)。在国内...……更多
2024-08-09 15:00:00模型,梯队,中国,从容,科技,模型

近日,中国电信人工智能研究院(TeleAI)成功完成国内首个基于全国产化万卡集群训练的万亿参数大模型(万卡万参),并正式对外开源首个基于全国产化万卡集群和国产深度学习框架训练的千亿参数大模型——星辰语义大模...……更多
2024-09-30 09:50:00万卡,重磅,模型,国产,训练,模型
...考语、数、外全卷能力测试。据OpenCompass于6月19日发布的评测结果,大模型的语文、英语考试水平还不错,但数学都不及格,最高分只有75分(满分150分)。参加OpenCompass此次高考测试的大模型,分别是来自阿里巴巴、零一万物、...……更多
2024-06-26 07:26:00考生,模型,高考,模型,评测,高考

...意度和服务质量。”中国信息协会常务理事、国研新经济研究院创始院长朱克力表示,大模型在知识问答方面的表现相对较好,因为其可以通过学习大量的数据和语料库来提供准确的答案。大模型不仅适合作为智能机器人用以服...……更多
2023-10-10 17:56:00模型,业务,模型,报告,应用,能力

...特定需求的模型。目前 o1-preview 模型表现最为全面,但是评测结果展示了许多其他模型在特定垂直领域的强有力的表现(具体详见论文和榜单)。最后,欢迎广大研究者使用我们的评测集进行实验和研究。淘天集团算法技术 - 未...……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型
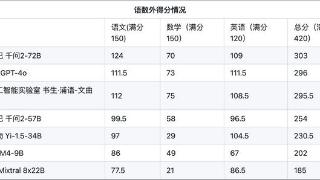
...能力测试。6月19日, OpenCompass发布了首个大模型高考全卷评测结果。语数外三科加起来的满分为420分,此次高考测试结果显示,阿里通义千问2-72B排名第一,为303分,OpenAI的GPT-4o排名第二,得分296分,上海人工智能实验室的书生...……更多
2024-06-24 09:22:00评测结果,最高分,评测,数学,高考,结果

...模态大型模型设计的评估框架,为多模态模型(LMMs)的评测提供了一站式、高效的解决方案。代码仓库: https://github.com/EvolvingLMMs-Lab/lmms-eval
官方主页: https://lmms-lab.github.io/
论文地址: https://arxiv……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本

...百城”专项评测活动11月7日正式开启,来自中国信息通信研究院泰尔系统实验室5支专业的网络质量评测团队奔赴全国百余个城市,对重点和热点区域开展移动网络测试。其实“移动网络质量专项评测活动”已经开展了4年了,中...……更多
2023-11-20 17:10:00百城,高质量,专项,评测,质量,移动

...亚辉一起出任天工智能联席CEO,并兼任昆仑万维2050全球研究院院长,负责前沿技术的研究。9月5日,昆仑万维天工大模型在腾讯优图实验室联合厦门大学开展的多模态大语言模型测评中,综合得分排名第一。9月25日,昆仑万维正...……更多
2023-10-30 15:35:00万维,昆仑,商用,高质量,模型,领先

...究中心联合中关村实验室研制的SuperBench大模型综合能力评测框架,正式对外发布2024年3月版《SuperBench大模型综合能力评测报告》。评测共包含了14个海内外具有代表性的模型,结果显示:文心一言4.0表现亮眼。例如在人类对齐能...……更多
2024-04-22 09:46:00评测报告,清华,模型,评测,能力,报告
...脸识别安全合规专家观点及实践分享。发布“护脸计划”评测结果和评估规范解读成为本次大会焦点。会上,中国信通院云大所副所长闵栋公布了通过“人脸识别安全专项评测”“金融APP人脸识别安全能力评测”“人脸识别系统...……更多
2023-01-16 20:18:00发布会,成果,年度,在线,人脸,云大

...可能会在对抗攻击的情况下被误导。”清华大学人工智能研究院副院长、计算机系教授朱军在论坛的主旨演讲中举例,监控摄像头的人脸识别验证的安全,其实在之前应用之前,就已经开始做很多的学术研究和应用,“一方面去...……更多
2023-11-09 23:33:00越来,越来越,智能,安全,技术,人工智能
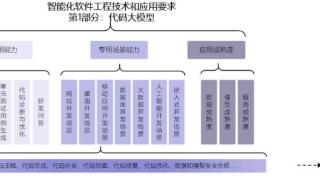
...表现优秀,获得4+评级。以阿里云通义灵码为例,信通院评测结果显示:在通用能力方面,通义灵码在代码转换、代码检查及修复、代码优化等方面表现突出;在专用场景方面,通义灵码提供网站开发、数据库开发、大数据开发...……更多
2024-06-12 09:54:00模型,评估,国产,名单,模型,能力

6月19日,上海人工智能实验室发布首个AI高考全卷评测结果,月初开源的阿里通义千问大模型Qwen2-72B排名第一,在语数外三科420分的满分中获得303分,OpenAI的GPT-4o和上海人工智能实验室的书生·浦语2.0文曲星(InternLM2-20B-WQX)排...……更多
2024-06-20 11:10:00评测结果,全都,评测,数学,高考,结果

...言医疗语料库 MMedC。2. 开发了一个全新的多语言医疗问答评测标准 MMedBench, 覆盖了 6 种语言,21 种医学子课题。3. 推出了一款名为 MMed-Llama 3 的全新基座模型,以 8B 的尺寸在多项基准测试中超越了现有的开源模型,更加适合通过...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模
更多关于科技的资讯:
近日,AI眼镜热潮再度来袭。AI眼镜是集成AI语音助手、蓝牙耳机、翻译、导航、墨镜、出行、聊天服务等功能的可穿戴设备。业内普遍猜测
2025-01-04 11:03:00

1月4日消息,你对日本的印象好吗,从实际调查情况来看,大多数都不是太好。日本民间非营利团体“言论NPO”与中国国际传播集团发布的调查报告显示
2025-01-04 11:15:00

多芬氨基酸洗面奶 160ml*2 瓶日常售价 104.9 元,今日下单赠旅行装 30g*2 支 + 官方立减 16 元
2025-01-04 11:15:00
1月4日消息,印度宝莱坞电影里,经常会出现一些身怀绝技的“神人”,刀枪不入对于他们而言都是小意思,实际上在现实生活中还有人玩的更花
2025-01-04 11:15:00

近年来,全球经济环境的不确定性以及旅游业的波动,给酒店行业带来了前所未有的挑战。加之消费者偏好的快速变化,酒店业正经历着一段艰难的低谷期
2025-01-04 11:24:00
在健康产业蓬勃发展的当下,善百年作为甘油二酯生产厂家脱颖而出,成为行业内的佼佼者,引领着甘油二酯产品的创新与发展潮流。善百年专注于甘油二酯的研发与生产
2025-01-04 11:36:00

快科技1月4日消息,九号公司最新推出了远航家M3系列电动摩托车,售价6999元起。该车号称“高端铅酸电摩新标杆”,采用了“MAX级”制动配置
2025-01-04 11:45:00

快科技1月4日消息,昨晚领克全新旗舰SUV车型领克900正式发布,然而昨天上午,网络上就有该车的相关评测视频泄露偷跑。从视频内容可知
2025-01-04 11:45:00

快科技1月4日消息,昨晚就提前泄密公开致歉的汽车博主“陈震同学”发布最新消息,称已收到 “领克900我们违约发布事件”的律师函
2025-01-04 12:15:00


随着全球化人工智能、区块链、电商科技进程的不断推进,跨境电商已成为我国对外贸易的重要发展方向。近日,香港知名科技公司中昊科技有限公司正式推出的中昊科技跨境电商寄售平台(ZHTCEP)于2024年12月15日正式上线
2025-01-04 13:10:00

快科技1月4日消息,石头科技官宣将于1月8日召开发布会,推出两款新品:石头G30 Space、石头G30。其中,石头G30 Space是最新一代扫拖机器人
2025-01-04 13:15:00

全球规模最大、最具影响力的消费电子盛会——国际消费电子展(CES)即将再度来袭。创始于1967年的CES,由美国电子消费品制造商协会(CTA)主办
2025-01-04 13:30:00

快科技1月4日消息,据韩国媒体报道称,韩国客机事故,受害者赔偿额度约合人民币73亿元。据悉,失事飞机共投保约1.5257万亿韩元(约合人民币75
2025-01-04 12:45:00

快科技1月4日消息,2025年已经拉开序幕,最近“2025是完美平方年”的话题引发热议。首先,2025是一个“完美平方数”
2025-01-04 12:45:00