- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
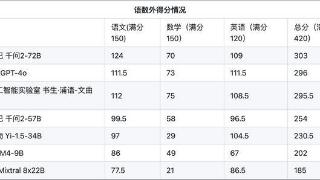
6月19日,上海人工智能实验室发布首个AI高考全卷评测结果,月初开源的阿里通义千问大模型Qwen2-72B排名第一,在语数外三科420分的满分中获得303分,OpenAI的GPT-4o和上海人工智能实验室的书生·浦语2.0文曲星(InternLM2-20B-WQX)排...……更多
2024-06-20 11:10:00评测结果,全都,评测,数学,高考,结果
...考语、数、外全卷能力测试。据OpenCompass于6月19日发布的评测结果,大模型的语文、英语考试水平还不错,但数学都不及格,最高分只有75分(满分150分)。参加OpenCompass此次高考测试的大模型,分别是来自阿里巴巴、零一万物、...……更多
2024-06-26 07:26:00考生,模型,高考,模型,评测,高考
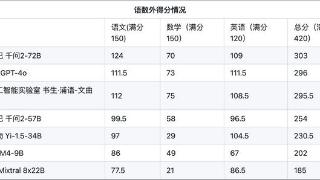
...能力测试。6月19日, OpenCompass发布了首个大模型高考全卷评测结果。语数外三科加起来的满分为420分,此次高考测试结果显示,阿里通义千问2-72B排名第一,为303分,OpenAI的GPT-4o排名第二,得分296分,上海人工智能实验室的书生...……更多
2024-06-24 09:22:00评测结果,最高分,评测,数学,高考,结果
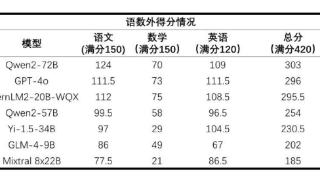
...20日消息,上海人工智能实验室19日公布了首个AI高考全卷评测结果。据介绍,2024年全国高考甫一结束,该实验室旗下司南评测体系OpenCompass选取6个开源模型及GPT-4o进行高考“语数外”全卷能力测试。评测采用全国新课标I卷,参...……更多
2024-06-20 10:19:00评测结果,人工智能,上海,人工,实验室,评测
...获国内头筹在极客公园最新发布的高考新课标Ⅰ卷大模型评测报告中,GPT-4o以562分排名文科总分第一。国内产品中,字节跳动旗下的豆包拔得头筹,成绩是542.5分。据介绍,本次评测以新课标Ⅰ卷为考题,与河南省考卷完全相同...……更多
2024-06-26 11:14:00豆包,一本,文科,模型,高考,模型

...,还真的有人试了。上海人工智能实验室近日公布了司南评测体系OpenCompass选取开源大模型测试今年高考的全国新课标I卷“语数外”的结果,为了确保“闭卷”考试,大模型的开源时间早于高考,同时邀请有高考评卷经验的教师...……更多
2024-06-26 22:29:00试卷,成绩,高考,结果,全国,模型

...计意义思考不足,起码会带来以下几个潜在危害:其一,评测结果能否真实反映大模型的能力?如果对此认识不足,往往会过分夸大模型的效果。其二,会让人以为指标的提升,等价于大模型能力的提升、以及等价于真实场景的...……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...140余个开源和商业闭源的语言及多模态大模型全方位能力评测结果。本次智源评测,分别从主观、客观两个维度考察了语言模型的简单理解、知识运用、推理能力、数学能力、代码能力、任务解决、安全与价值观七大能力;针对...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测

...究中心联合中关村实验室研制的SuperBench大模型综合能力评测框架,正式对外发布2024年3月版《SuperBench大模型综合能力评测报告》。评测共包含了14个海内外具有代表性的模型,结果显示:文心一言4.0表现亮眼。例如在人类对齐能...……更多
2024-04-22 09:46:00评测报告,清华,模型,评测,能力,报告

...了英特尔酷睿Ultra7155H、AMD7840HS等处理器核显性能。综合评测结果来看相比较AMD的Phoenix、英特尔的MeteorLake核显,AdrenoX1在基本的32位和16位浮点数学运算方面的吞吐量很有竞争力。此外得益于速度极快的LPDDR5X主控,AdrenoX1的DRAM带.……更多
2024-07-06 13:42:00高通,评测,高通,英特,英特尔,性能

...比如,谷歌引以为傲的MMLU,是一个由伯克利大学主导的评测,囊括阅读理解、大学数学以及物理和社会科学等57项测验。但如果说,这些题目,是可以事先得知的呢?9月,中国人民大学与伊利诺伊大学香槟分校联合推出了一个...……更多
2023-12-20 00:10:00王者,抄袭,模型,万物,公司,数据

...OpenAI表示, o1模型在推理能力上相比GPT-4o显著进步。综合评测显示,在绝大多数需要深入思考和复杂推理的任务中,新模型都展现出了明显优于GPT-4o的表现,并在多个细分测试上超过90%。在启用视觉感知能力的情况下,o1模型在M...……更多
2024-09-13 16:44:00复旦,相关性,概率,推理,模型,教授

在这个快节奏的时代,智能手机已经成为我们生活的一部分,而对于许多用户来说,续航焦虑和性能瓶颈是两大痛点。今天,我们要为大家带来的,是一款能够打破这些焦虑的产品——一加Ace3Pro。这款手机不仅在性能上达到了...……更多
2024-07-29 22:31:00续航,全都,评测,性能,续航,手机

兔友们,全新的安兔兔评测PC版已经正式发布了,目前已经在安兔兔官网以及各大渠道上线,欢迎大家下载体验。与Android版本测试流程相似,安兔兔评测PC版测试项目同样包括了CPU、GPU、Memroy(内存和存储)和UX(用户体验)四...……更多
2024-10-04 00:33:00评测,体验,测试,模型,处理,电脑

...5T基础平台软件产品兼容国内主流芯片。一、混元Turbo之评测混元Turbo的核心技术混元Turbo的发布凝聚了腾讯团队长期以来对大模型技术的深入研究。该模型采用全新的分层异构MoE架构,创新之处在于通过合理配置专家数量与激活...……更多
2024-09-14 14:04:00金鼎,腾讯,模型,腾讯,模型,推理

...,另一方面能够直观体现国产大模型的最新发展进程。
评测结果显示,文心一言app在智能体能力方面表现突出。在用户创建智能体功能方面,文心一言app支持用户通过上传图片或拍照的方式制作智能体形象,同时支持用户通过...……更多
2024-03-14 17:06:00数据发布,评测报告,中国,评测,智能,报告

...即可轻松部署SandboxFusion,也可直接在GitHub上进行体验。评测结果:解决难题,闭源模型仍优于开源模型发布评测基准及沙盒的同时,研究团队也基于FullStack Bench测评了全球20余款代码大模型及语言大模型的编程表现。模型包括Qwe...……更多
2024-12-06 09:50:00豆包,基准,字节,模型,编程,代码
...平台 OpenCompass 的多模态评测领域中取得重大进展。最新评测结果显示,云从科技的从容大模型在该体系中的平均得分为 65.5,这一成绩使得从容大模型跻身全球前三,超越了谷歌的 Gemini-1.5-Pro 和 GPT-4v,仅次于 GPT-4o(69.9)和 Clau...……更多
2024-06-29 09:36:00模态,从容,模型,能力,全球,模态

...公司正在向 o1 的霸主地位发起冲击,并开始在一些权威评测中取得领先。今天,国内首款具备中文逻辑推理能力的 o1 模型来了,它便是由昆仑万维推出的「天工大模型 4.0」 o1 版(英文名:Skywork o1)。这也是近一个月来,该公...……更多
2024-11-28 10:00:00模型,逻辑推理,中文,推理,逻辑,国产

...集。虽然这类数据的生成成本较低、人力需求不高,但是评测方法的开发却需要他们逐一校验,因为数据分析的结果并不仅仅依赖于执行的一致性。例如,在生成分类器的问题上,即便参考代码的执行结果和预测代码的结果不一...……更多
2024-04-07 10:50:00立新,数据分析,基准,科学家,模型,评估

...觉语言、文生图、文生视频、语音语言大模型综合及专项评测结果。智源评测发现,2024年下半年大模型发展更聚焦综合能力提升与实际应用。多模态模型发展迅速,涌现了不少新的厂商与新模型,语言模型发展相对放缓。模型...……更多
2024-12-20 11:22:00评测结果,研究院,评测,结果,研究,模型
...务上效果继续突破,展现出优异的性能。根据最新测试集评测结果,星火X1在通用任务效果评测中全面对标OpenAI o1和DeepSeek R1,在数学、知识问答等方面表现突出。数学答题和复杂的数理逻辑推理方面,星火X1能够准确识别出复杂...……更多
2025-04-22 16:50:00讯飞,星火,行业应用,司法,升级,医疗

...案间的相似度来确定评分的方式,本申请方案得到的口语评测结果更加准确。天眼查资料显示,科大讯飞股份有限公司,成立于1999年,位于合肥市,是一家以从事研究和试验发展为主的企业。企业注册资本231173.4185万人民币。通...……更多
2025-05-10 10:28:00口语,评测结果,讯飞,评测,专利,结果

《科创板日报》5月31日讯(记者 朱凌)直至五月尾声,AI应用市场的火热态势依旧不减。30日,基于混元大模型的AI助手App“腾讯元宝”上线,标志着BAT终于在AI消费C端应用领域聚首。据介绍,自2023年9月首次亮相以来,腾讯混...……更多
2024-05-31 18:07:00腾讯,陪练,元宝,语音,模型,评测

DxOMark网站于今天放出了GalaxyS23Ultra的相机评测结果,排名第10位。该机的综合得分为140分,其中拍照单项成绩为139分,视频为137分。DxOMark中文官网暂时并未放出关于GalaxyS23Ultra的详细评测信息。附官网对GalaxyS23Ultra的主要优缺点...……更多
2023-02-18 19:04:00评测结果,评测,相机,结果,光下,评测
...实则为了利益许多评测机构标榜自己是“第三方”,相关评测结果“客观中立”, 但由此引发的消费乱象时常出现。这不仅没有维护消费者的正常权益,反而扰乱了市场秩序。记者发现,相同品类的产品,不同机构的评测结果...……更多
2023-02-22 01:46:00第三方,客观,评测,评测,机构,消费

...市医药高新区大队(高港大队)辖区3月份快递外卖企业评测结果,“顺丰快递”登了“红榜”,“美团外卖”因骑手违章较多上“黑榜”。据介绍,交警部门要对上“黑榜”的快递、外卖企业负责人进行约谈,督促企业加强对...……更多
2023-03-18 22:49:00评测结果,泰州,红榜,企业,评测,结果
...空间。最近的一次,第一财经曾在6月报道过,根据司南评测体系OpenCompass的高考全卷测试,包括GPT-4在内,7个大模型在高考测试中语文和英语考试水平普遍不错,但数学这科全不及格,最高分也只有75分。在批阅大模型的数学试...……更多
2024-07-17 11:56:00实测,模型,模型,数学,小数,问题
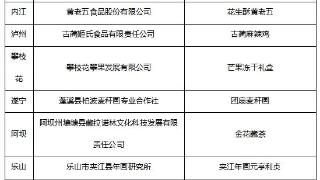
本文转自:人民网-四川频道人民网成都9月27日电 (赵祖乐)9月26日,2024年“礼遇四川”四川特色伴手礼评测活动在成都落下帷幕。经过长达数月的精心筹备与激烈角逐,最终50款极具地域特色和文化底蕴的伴手礼脱颖而出,获...……更多
2024-09-27 20:27:00四川,评测结果,礼遇,评测,特色,结果
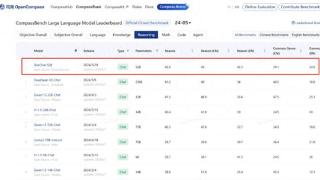
...一。作为新一代版本,TeleChat2-115B 在9月最新公布的 C-Eval 评测 Open Access 模型综合榜单中,以 86.9 分的成绩排名第一。其通用能力较 TeleChat 系列模型提升近 30%,特别是在工具使用、逻辑推理、数学计算、代码生成和长文写作等方...……更多
2024-09-30 09:50:00万卡,重磅,模型,国产,训练,模型
更多关于科技的资讯:

从“供应链”到“共赢链”,青岛智链顺达科技有限公司正通过开放、智能、协同的供应链体系,为传统制造业的转型升级提供一个价值共生
2025-10-17 17:54:00

当都市丽人的加拿大鹅绒保暖衣在冬日市场中掀起热潮,新品订货会上取得经销商5亿订单销量的数据。这个经典内衣品牌的华丽转身背后
2025-10-17 13:41:00

转眼秋意渐浓,中秋、国庆双节余温未散,团圆出游的热潮与“应季而食、适时而补”的传统饮食文化相互交织,共同点燃了金秋时节的滋补消费热情
2025-10-17 13:56:00

本报讯(全媒体记者李芳)10月9日,省药监局正式批准热敏灸机器人第二类医疗器械上市。这标志着江西热敏灸产业进入数智化时代
2025-10-17 07:10:00
厦门网讯 (厦门日报记者 薛尧)无人机、运动相机迎来降价潮!近日有市民发现相关热门产品价格跳水,记者走访了解到,我市多家大疆授权体验店中
2025-10-16 08:38:00

视弱人士庄先生在公交视弱辅助系统的帮助下乘车。厦门网讯(文/图 厦门日报记者 林钦圣 通讯员 江安娜) “我们先找到并打开公交App
2025-10-16 08:38:00
近日,中石化石油工程设计有限公司自主研发的“管道环焊缝射线检测缺陷智能辅助评判系统”,顺利完成准确率测试。本次测试中,该系统总计检查了210张油气长输管道环焊缝射线检测底片
2025-10-16 09:03:00
当“遇到问题先到社交媒体上搜索”成为一代青少年的本能反应,当班级群、兴趣圈与直播平台深度嵌入他们的日常生活,社交网络正构成这代“数字原住民”成长的基本环境
2025-10-16 09:16:00
在人工智能技术飞速发展的今天,大模型以其强大的信息处理与泛化能力,正深刻改变医学领域的科研与临床实践。与此同时,以聚类分析
2025-10-16 09:57:00

10月15日,“微信派”微信公众号发布最新一期播客,聊到了“真的很多人不发朋友圈了吗?”“人去世后,朋友圈会被回收吗?”等话题
2025-10-16 10:13:00

近日,深圳日日佳显示技术有限公司(以下简称“日日佳”或“公司”)正式签约入驻企知道科创空间。作为专注于TFT-LCD模组制造的细分领域的国家高新技术企业和深圳市专精特新中小企业
2025-10-16 10:18:00

当汽车从单纯的“交通工具”升级为承载多元需求的“出行载体”,是什么力量在守护这场变革的安全底线?2025世界NCAP大会即将在中国上海启幕
2025-10-16 10:50:00

2025年10月16日,由山东省商务厅主办的“数商兴农庆丰收暨九九网购节”电商促消费活动在青岛莱西市人民广场隆重启动。花田玑密品牌创始人
2025-10-16 10:53:00

10月15日,香港金融管理局(HKMA)与香港数码港管理有限公司联合公布第二期生成式AI沙盒参与者名单。蚂蚁银行、中银香港
2025-10-16 11:24:00