- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

在大数据时代,自动数据分析已经成为跨技术背景人员不可或缺的工具。以 GPT-4 为代表的大型语言模型,它们已经能够理解自然语言查询,并能生成相应的代码或分析,让自动数据分析变得更加接近现实。例如,Devin 的成功,...……更多
2024-04-07 10:50:00立新,数据分析,基准,科学家,模型,评估

【新智元导读】普林斯顿大学新发布的CORE-Bench基准测试,通过270个基于90篇跨学科科学论文的任务,可评估AI智能体在计算可重复性方面的表现,最简单任务的准确率可以达到60%,最难任务准确率仅有21%大模型的能力越来越强,...……更多
2024-09-26 13:38:00普林,普林斯顿,斯顿,准确率,基准,科学家

...Pengchuan Zhang是Meta AI(原Facebook AI研究院)的人工智能研究科学家,曾在微软研究院担任高级研究科学家。他的研究领域主要集中在深度学习、计算机视觉和多模态模型等方向,曾发表多项具有深远影响力的成果,例如AttnGAN、OSCAR...……更多
2024-11-07 09:53:00文生,次数,联合,方案,模型,文生

...为仅对特定神经科学领域、具有最高专业知识的人,神经科学家的准确率仍然低于大模型,为 66%和人类专家类似的是,如果大模型对预测结果表示具有高度自信时,回答结果的正确率也更高,也就是说,大模型完全可以辅助人...……更多
2024-12-09 09:50:00暴虐,准确率,模型,高达,完了,科研

...工具和依赖内部知识之间进行判断——就像训练一位年轻科学家如何在相信自己计算的同时知道何时咨询专业设备——可能比单纯地卷AI计算能力更为重要。微调方法简介微调方法由两部分组成:World Knowledge Distillation(WKD)和Too...……更多
2024-12-03 13:34:00正确率,清华,模型,全新,科学,方法
LLM可以比科学家更准确地预测神经学的研究结果!最近,来自伦敦大学学院、剑桥大学、牛津大学等机构的团队发布了一个神经学专用基准BrainBench,登上了Nature子刊《自然人类行为(Nature human behavior)》。结果显示,经过该基...……更多
2024-12-02 09:51:00结论,神经,科研,人类,水平,专家

...),还在技术报告中公布了详细的后训练方法。Ai2 研究科学家 Nathan Lambert(论文一作)的推文这份 70 多页的技术报告可以说诚意满满,非常值得详细阅读:
Tülu 3 发布后,社区反响热烈,甚至有用户表示测试后发现其表现比 GP...……更多
2024-11-26 09:44:00模型,性能,训练,模型,训练,数据

...在多项基准上刷新了SOTA。全世界高质量数据几乎枯竭。AI科学家们为了解决这一难题,可谓是绞尽脑汁。目前来看,合成数据或许就是大模型的未来,也成为业界公认的解决之法。就连英伟达科学家Jim Fan曾发文表示,合成数据...……更多
2024-08-20 13:44:00微软,力作,秘诀,生成,团队,性能

...飞也曾短暂进入工业界,出任谷歌副总裁即谷歌云AI首席科学家。她一手推动了谷歌AI中国中心正式成立,这是Google在亚洲设立的第一个AI研究中心。并带领谷歌云推出了一系列有影响力的产品,包括AutoML、Contact Center AI、Dialogflow...……更多
2024-11-11 13:31:00团队,智能,空间,视频,模态,模型
...的提示进行匿名回答,并投票选出他们更喜欢的回答。在数据分析、编程和数学等推理能力较强的类别中,o1-preview 的受欢迎程度远远高于 GPT-4o。然而,o1-preview 在某些自然语言任务上并不受欢迎,这表明它并不适合所有用例。...……更多
2024-09-13 16:42:00推理,模型,极限,突破,学习,模型

...个例子,在 Kaggle 数据科学竞赛中(如图 1 所示),数据科学家需要遵循一个结构化的工作流程:收集、清理、预处理和标准化数据,创建数据加载器以实现高效管理,生成关键评估指标,以及开发自定义模型。然后,这些见解...……更多
2024-11-09 09:53:00华为,结构化,推理,思维,结构,智能
...智能研究所汇聚了数十名智能科学与机器人领域顶尖青年科学家,依托鹏城云脑、中国算力网等自主可控 AI 基础设施,致力于打造多智能体协同与仿真训练平台、云端协同具身多模态大模型等通用基础平台,赋能工业互联网、...……更多
2024-07-29 09:39:00中大,文献,调研,深度,实验室,实验

...变人类与科学文献互动的方式。最近一段时间,有关 AI 科学家的研究越来越多。大语言模型(LLM)有望帮助科学家检索、综合和总结文献,提升人们的工作效率,但在研究工作中使用仍然有很多限制。对于科研来说,事实性至...……更多
2024-09-13 13:33:00博士后,模型,科研,博士,检索,能力

...工程师简化了上述所有复杂环节。它的目标不是取代数据科学家或工程师,而是与人类合作并处理所有繁重任务。在人与 AI 合作的工作环境中,人们仅用几个小时就能完成一周的工作。听起来有点像今年 3 月在 AI 社区爆火的首...……更多
2024-11-19 09:48:00机器,大师,工程师,工程,学习,学习

...证明,模型的自我提升可以摆脱对人类监督的依赖。
Meta科学家Yann LeCun也转发了这篇研究,并亲自下场玩起了双关梗——Meta提出的Meta-Judge,FAIR能否实现fair?研究不重要,重要的是Meta FAIR这一波曝光率拉满了。元奖励(Meta-Rewar...……更多
2024-08-01 09:40:00三角,进化,模型,奖励,训练,迭代

...于基础编程和高级编程问题;DS-1000中超过95%数据集中于数据分析和机器学习,且仅对Python语言进行评测;xCodeEval虽覆盖多项任务,但基本局限于高级编程和数学领域;McEval和MDEval扩展了支持的编程语言,但应用领域仍局限于基...……更多
2024-12-06 09:50:00豆包,基准,字节,模型,编程,代码

...型及格!北大联合北京通用人工智能研究院提出了一个新基准数据集:LooGLE,专门用于测试和评估大语言模型(LLMs)长上下文理解能力。该数据集既能够评估LLMs对长文本的处理和检索能力,又可以评估其对文本长程依赖的建模...……更多
2024-08-08 09:39:00基准,北大,生成,模型,文本,评估

随着语言模型的能力越来越强,现有的这些评估基准实在有点小儿科了,有些任务的性能都甩了人类一截。通用人工智能(AGI)的一个重要特点是模型具有处理人类水平任务的泛化能力,而依赖于人工数据集的传统基准测试并...……更多
2023-05-13 21:28:00微软,基准,专为,团队,人类,全新

...动评分器 ( FLAMe-RM 和 FLAMe-Opt-RM)。在12个自动评分器评估基准中的8个基准上,FLAMe及其变体的自动评分性能优于用专有数据训练的GPT-4o、Gemini-1.5-Pro等模型。- 计算高效的多任务训练:引入了一种计算更为高效的方法,使用创新...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...现。OpenAI发布的一项匿名人类偏好评估显示,o1-preview在数据分析、编码和数学等推理密集型类别中,比GPT-4o更受欢迎,但在某些自然语言任务中,o1-preview并不是首选。这表明它并不适合所有用例,GPT-4o在文本生成方面仍保持优...……更多
2024-09-13 16:44:00复旦,相关性,概率,推理,模型,教授

...元导读】最近,Latent Space发布的播客节目中请来了Meta的AI科学家Thomas Scialom。他在节目中揭秘了Llama 3.1的一些研发思路,并透露了后续Llama 4的更新方向。刚刚发布的开源「巨无霸」Llama 3.1虽然自带论文,但依旧激起了广大网友强...……更多
2024-07-29 09:33:00科学家,训练,科学,模型,训练,基准

新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。近日,淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,具有“中文、多样性、高质量、静态、易于评估”五...……更多
2024-11-22 09:51:00豆包,中文,真实性,评估,模型,中文

...一款名为 MMed-Llama 3 的全新基座模型,以 8B 的尺寸在多项基准测试中超越了现有的开源模型,更加适合通过医学指令微调,适配到各种医学场景。
所有数据和代码、模型均已开源。MMedBench 上的准确率,图 d 展⽰了在 MMedC 上进...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...代表,蚂蚁集团机器智能部总经理、蚂蚁安全实验室首席科学家王维强在会议发言中说。他进一步解释,可通过制定行业标准与指南,为开发和部署生成式人工智能系统的开发者和机构提供清晰指导;投入研发并开放保障生成式...……更多
2024-04-25 04:00:00基准,评估,测试,安全,全球,人工智能

...Anna Veronika Dorogush,她毕业于莫斯科国立大学,曾在Yandex数据分析学院学习了数据分析,并在Google和Microsoft担任过软件工程师,此后她在Yandex担任机器学习系统负责人。6.FlutterFlow获得由Google Ventures领投的2550万美元……更多
2024-01-29 09:20:00首席,科学家,芯片,创业,科学,模型

全新大语言模型越狱攻击基准与评估体系来了。来自香港科技大学(Guangzhou)USAIL研究团队,从攻击者和防御者的角度探讨了什么因素会影响大模型的安全。提出攻击分析系统性框架JailTrackBench。JailTrackBench研究重点分析了不同...……更多
2024-11-01 09:29:00模型,基准,攻击,影响,安全,研究

...where to judge)。最后,我们归纳了评估 LLM 作为评判者的基准数据集,并强调了关键挑战和有希望的方向,旨在提供有价值的见解并启发这一有希望的研究领域的未来研究。论文链接:https://arxiv.org/abs/2411.16594
网站链接:https://llm...……更多
2024-12-04 09:49:00范式,模型,基准,偏见,数据,评估

...性消息——结果没多久,Reflection 70B就被打假了:公布的基准测试结果和他们的独立测试之间存在显著差异。无论是AI研究者,还是第三方评估者,都无法复现Matt Shumer所声称的结果。根据Artificial Analysis的数据,Reflection 70B在基准...……更多
2024-10-08 09:47:00神坛,光速,团队,世界,模型,基准

...离 7 月 23 日 Llama 3.1 发布才刚刚过去 2 个月。Meta 首席 AI 科学家 Yann LeCun 也欢快地表达了自己的喜悦:「乖宝宝羊驼!」Meta 也借此机会重申了他们一贯的主张:「通过开源人工智能,我们才能确保这些创新能够反映和造福于其...……更多
2024-09-27 13:42:00推理,可在,图像,运行,版本,支持
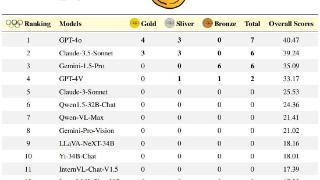
...知识型推理、数学推理、编程任务及视觉推理等任务上设立新行业基准而引发广泛讨论:Claude-3.5-Sonnet 已经取代OpenAI的GPT4o成为世界上”最聪明的AI“(Most Intelligent AI)了吗?回答这个问题的挑战在于我们首先需要一个足够挑战...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力
更多关于科技的资讯:

2月20日下午,华为召开鸿蒙智行尊界技术发布会,由华为常务董事、终端BG董事长、智能汽车解决方案BU董事长余承东主持。发布会上
2025-02-20 18:30:00

2月18日,爱奇艺(NASDAQ:IQ)发布截至2024年12月31日未经审计的第四季度和全年财报。全年总收入292亿元人民币
2025-02-20 18:42:00

中新经纬2月20日电 (张芷菡)近段时间以来,茶饮咖啡品牌掀起做“副业”的热潮,继茶颜悦色与蜜雪冰城开起“小卖部”,近日
2025-02-20 19:08:00

鲁网2月20日讯(记者 李晓晨)近日,随着国产动画电影《哪吒2》的热映,其精湛的画面制作和深刻的文化内涵再次赢得了观众的广泛赞誉
2025-02-20 19:14:00

2月20日,备受瞩目的iPhone16e正式发布,这款定位“性价比旗舰”的新机起售价4499元,成为A18芯片阵营中最亲民的机型
2025-02-20 19:21:00

在实际冻干过程中,常常由于处方或冻干工艺设计不合理而出现各种各样的问题,今天欣谕冻干厂家简单介绍了药品冻干过程各关键环节的控制方法
2025-02-20 19:36:00

江西手机报萍乡讯(习佳婕) 春启新岁,复工正当时。连日来,安源区各工业企业已奏响奋进交响曲,处处奔涌着实干争先的春潮。走进安源工业园
2025-02-20 19:39:00

保险向普惠靠拢是时代之需,国家金融监督管理总局在《关于推进普惠保险高质量发展的指导意见》中提到,未来五年,要基本建成高质量的普惠保险发展体系
2025-02-20 20:13:00

在AI技术持续发展并逐步深入生活的今天,Aifeex公司自主研发的Takwin计算系统,以其卓越的性能和高效的计算能力
2025-02-20 20:26:00

中国青岛,2月20日,海尔集团公司(海尔集团)旗下Cartech Holding Company(卡泰驰控股)与中国平安旗下Yun Chen Capital Cayman(云辰资本)达成协议
2025-02-20 20:28:00
北京时间2月20日(美东时间2月20日),哔哩哔哩(NASDAQ: BILI,HKEX:9626;以下简称“B站”)公布了截至2024年12月31日的第四季度和全年未经审计的财务报告
2025-02-20 20:28:00

自国产动画电影《哪吒之魔童闹海》(以下简称《哪吒2》)上映以来,其票房与衍生经济效应持续升温,不仅刷新全球动画电影票房纪录
2025-02-20 21:16:00

“直播电商是近年来最重要的电商业态创新方向,也是网络零售交易增量的主要来源,促进消费和就业效应明显。”中国国际电子商务中心研究院院长李鸣涛表示
2025-02-20 22:01:00

齐鲁晚报·齐鲁壹点 赵波 通讯员 李春颖2月19日,山东港口2025年度科技创新大会在青岛召开,正式发布《山东港口人工智能(大模型)总体建设规划》(以下简称《规划》)
2025-02-20 22:35:00