- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

IT之家 8 月 26 日消息,云知声于 23 日宣布推出山海多模态大模型。通过整合跨模态信息,山海多模态大模型能够接收文本、音频、图像等多种形式作为输入,并实时生成文本、音频和图像的任意组合输出。▲云知声山海助手微...……更多
2024-08-27 09:38:00模态,山海,实时,生成,模型,图像

...单,微软公司获得了一项新的专利,通过深度学习构建多模态3D面部模型,可以创建非常逼真的虚拟肖像。这项专利全称为《多模态三维面部建模和跟踪,生成富有表现力的虚拟肖像》,该系统涉及处理器和存储系统,处理器负...……更多
2024-04-24 12:03:00模态,微软,面部,模型,专利,面部
网达软件:公司“视联网数字化智能平台”不涉及多模态模型 【网达软件:公司“视联网数字化智能平台”不涉及多模态模型】财联社12月8日电,网达软件发布异动公告,近日市场对于AI视频生成、多模态模型等相关概念较为...……更多
2023-12-08 20:40:00网达,模态,模型,数字,智能,平台

...行业大模型成果发布暨供需对接活动”上,“月球科学多模态专业大模型V2.0”正式发布,并将全面赋能“数字月球云平台”,加速月球科研与工程应用智慧化进程。“月球科学多模态专业大模型V2.0”发布现场。本次发布的V2.0版...……更多
2025-08-30 04:58:00月球,模态,模型,数字,科学,专业

文|武静静编辑|邓咏仪36氪获悉,多模态大模型公司「若愚科技」完成超5000万天使轮融资,本轮融资由东方精工领投,昆仲跟投,源合资本担任独家融资顾问。公司称,资金将主要用于产品研发,业务拓展以及团队搭建等方...……更多
2024-03-21 05:19:00机器人,融资,大脑,模型,机器,天使

【新智元导读】Mini-Monkey 是一个轻量级的多模态大型语言模型,通过采用多尺度自适应切分策略(MSAC)和尺度压缩机制(SCM),有效缓解了传统图像切分策略带来的锯齿效应,提升了模型在高分辨率图像处理和文档理解任务的...……更多
2024-08-13 09:42:00模态,华南,专治,后遗症,理工,分辨率
...据交易所(以下简称“深数所”)发布了500个垂直行业多模态算料集,按照大模型应用的不同阶段(训练、推理、调优),有的放矢地提供数据源,让国产大模型厂商“寻数有路”。此次深数所发布的首批500个人工智能大模型高...……更多
2024-04-13 01:58:00模态,行业,数据,模型,模态,人工智能

...、拓宽「天工SkyMusic」的能力边界,让模型具备更强的多模态情感理解与表达能力,为用户带来更优质的AI音乐体验。最后,我们将很快给出「天工SkyMusic」音乐创作Prompt指南,并提供更多的AI音乐Demo与使用技巧,与用户一同探索...……更多
2024-04-03 11:35:00天工,颠覆,模型,体验,音乐,天工
...板苏州科达:公司的KD-GPT大模型相对于谷歌Gemini的通用多模态大模型在服务对象上存在明显区别 【五连板苏州科达:公司的KD-GPT大模型相对于谷歌Gemini的通用多模态大模型在服务对象上存在明显区别】财联社12月13日电,苏州科...……更多
2023-12-13 17:47:00科达,模型,模态,苏州,对象,服务

北大等出品,首个多模态版o1开源模型来了——代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型...……更多
2024-11-20 09:42:00模态,推理,北大,视觉,模型,推理

...开源大模型DeepSeek走红,AI社区开发者也开始探讨,在多模态领域能否出现这样强大的模型。有着多模态领域深厚积累的阶跃星辰选择为开源贡献自己的力量,首次进行了模型开源。在大会期间,阶跃星辰与吉利联合宣布将双方...……更多
2025-02-22 16:36:00时来,模态,星辰,模型,时刻,领域

...音乐理解和生成结合在一起的想法比较新颖,论文也是多模态大模型领域的先期工作之一。并且,除了大模型本身,我们提出的针对模型训练的数据集制作流程和整理的数据集,对学术界也具有较大价值。”腾讯 ARC Lab 刘山松研...……更多
2024-04-09 10:25:00模态,音乐,科学家,生成,模型,创作
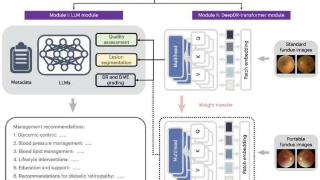
...构建了全球首个面向糖尿病诊疗的视觉-大语言模型的多模态集成智能系统 DeepDR-LLM,成果于 2024 年 7 月 19 日在 Nature Medicine 发表(题为 Integrated image-based deep learning and language models for primary diabetes care)……更多
2024-07-26 09:27:00糖尿,模态,诊疗,糖尿病,模型,团队

...展示AI时代云上创新的潮流科技。喜马拉雅珠峰AI音频多模态大模型亮相云栖大会,在“人工智能+”主题馆吸引众多市民驻足围观体验。AI(人工智能)已经在深刻影响着我们的生活,也影响和改变着内容创作行业。作为在线音...……更多
2024-09-21 09:50:00喜马拉雅,创作者,模型,创作,音频,内容
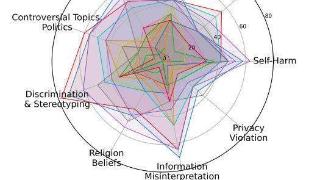
...论文指出,包括GPT-4V、GPT-4o和Gemini1.5在内的大部分主流多模态AI模型,处理用户的多模态输入(例如一起输入图片和文本内容)之后,输出结果并不安全。这项研究标题为《跨模态安全调整》(Cross-ModalitySafetyAlignment),提出了...……更多
2024-06-26 03:07:00模态,研究人员,隐患,模型,人员,安全

新智元报道编辑:LRST【新智元导读】现有多模态大模型在对齐不同模态时面临幻觉和细粒度感知不足等问题,传统偏好学习方法依赖可能不适配的外源数据,存在成本和质量问题。Calibrated Self-Rewarding(CSR)框架通过自我增强学...……更多
2024-06-21 09:21:00模态,美国,瓶颈,顶尖,模型,团队

...qizhixin.com随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现...……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本
...内瓦1月18日电 (记者 曾焱) 世界卫生组织18日发布的多模态大模型治理相关新指南说,人工智能在医疗卫生领域应用前景广阔,但同时也要防范其中可能出现的诸如“自动化偏见”导致的过度依赖等风险。作为一项快速发展的...……更多
2024-01-20 00:19:00人工智能,人工,前景,领域,医疗,智能

...候选选项、引入纯视觉输入设置)更严格地评估模型的多模态理解能力;模型在新基准上的性能下降明显,表明MMMU-Pro能有效避免模型依赖捷径和猜测策略的情况。多模态大型语言模型(MLLMs)在各个排行榜上展现的性能不断提...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本

...暨第一批人工智能应用场景发布大会上,新网银行的“多模态深度神经网络风控模型体系”入选“10项首批代表性创新产品”,彰显了新网银行在推动人工智能与金融深度融合方面的成果和贡献。活动现场。新网银行供图本次论...……更多
2024-10-30 16:25:00新网,模态,神经网络,代表性,深度,模型
蔚来 NOMI GPT 端云多模态大模型正式上线,并同步对搭载Banyan·榕智能系统的车型陆续开启推送。据悉,NOMI GPT是为NOMI打造的端云多模态大模型,基于自研的端云融合架构,拥有图像、音频、车身传感器等多模感知能力的NOMI可以...……更多
2024-04-12 13:09:00模态,模型,模态,多维度,多维,模型

...快科技7月5日消息,在2024世界人工智能大会上,支付宝多模态医疗大模型正式亮相,成为国内首批多模态医疗大模型之一。据悉,该医疗大模型的基石,源自蚂蚁集团自主研发的蚂蚁百灵大模型,这一先进平台不仅拥有“视听言...……更多
2024-07-05 16:17:00模态,模型,支付,视觉,医疗,支持

...里!公司回答表示:公司星汉大模型是以视觉为核心的多模态大模型。不仅能对视频图片中的目标、场景和事件等进分析分析理解,还能根据用户提示完成特定分析功能,同时也支持文本等其它模态数据的理解,支持人机交互等...……更多
2025-01-10 15:48:00大华,模态,星汉,模型,视觉,核心

...智能的上限仍然是当下最重要的事情。“我们始终认为多模态对AGI的实现非常重要,是实现AGI的必经之路。”对大模型的下一步发展,李璟表示,阶跃星辰主要会在两个方向发力。一是在预训练的基础上加上强化学习,提高模型...……更多
2025-05-17 12:05:00模型,按语,模态,之路,必经,星辰

...下旬推出 Grok-1.5 大语言模型之后,近日再次推出首个多模态模型 Grok-1.5 Vision。xAI 表示将于近期邀请早期测试者和现有的 Grok 用户测试 Grok-1.5 Vision(Grok-1.5V),不仅能理解文本,还能处理文档、图表、截图和照片中的内容。xAI ...……更多
2024-04-13 16:20:00马斯,马斯克,模态,模型,模态,模型

...中,视觉自监督大模型,可以实现4D Clip的自动标注;多模态互监督大模型,则可以完成通用障碍物的识别;3D重建大模型助力毫末做数据生成,用更低成本解决数据分布问题,提升感知效果;动态环境大模型则进一步使用重感知...……更多
2023-01-06 20:53:00火山,驾驶,引擎,建设,模型,驾驶

...来自 JHU, NYU, MIT, Harvard 等机构的研究团队开创了第一个多模态的 ToM 测试基准,发现现有的多模态模型和 LLM 都表现存在系统性缺陷,同时他们提出了一种有效的新方法。在刚结束的 ACL 2024 会议中,这篇论文获得杰出论文奖。论...……更多
2024-09-12 09:45:00模态,缺陷,测试,模态,模型,心智

...实现AGI(通用人工智能)的重要里程碑。券商建议关注多模态技术Sora视频一出,立刻震惊业界。360集团创始人、董事长周鸿祎2月16日在微博发文表示,这意味着AGI实现将从10年缩短到1年。其实,Sora出现之前,也有其他类似的AI...……更多
2024-02-19 08:10:00颠覆,布局,行业,视频,公司,模型

3月16日,在文心一言正式发布两周年后,百度发布了多模态大模型文心4.5和对标DeepSeek的文心X1。今日文心大模型4.5在百度智能云千帆大模型平台上线,输入价格为0.004元/千tokens;文心大模型X1输入价格0.002元/千tokens,为DeepSeek R1...……更多
2025-03-16 14:03:00模态,模型,文心,模型,哪吒,模态

...个面向不同细分领域(视频生成、音乐和同声传译)的多模态大模型,同时给之前已有的通用语言模型、文生图模型、语音模型来了一波大升级。这些模型共同构建起了火山引擎的「豆包全模态大模型家族」。家族新秀:豆包视...……更多
2024-09-30 09:51:00豆包,字节,生成,视频,模型,豆包
更多关于科技的资讯:
摘要:随着生成式人工智能技术在各行业的广泛应用,模型输出结果的不确定性问题日益受到关注。为提高模型在关键领域的可靠性,对输出不确定性进行量化分析成为重要方向
2025-12-04 06:17:00
12月3日从紫林醋业获悉,紫林醋业部分主导产品通过欧盟有机认证(EU Organic Certification),获准使用欧盟统一有机标识“欧洲叶标”(Euro-Leaf)
2025-12-04 07:31:00
中新经纬12月3日电 12月3日,豆包手机助手在官方微信号就“侵犯用户隐私”等问题进行回应,称不存在任何黑客行为。具体来看
2025-12-04 07:42:00

12月1日-3日,由中国互联网协会主办的2025“人工智能+”产业生态大会在北京举办。开幕式上,首届“AI领航杯”“人工智能+”应用与技能大赛总决赛举行了隆重的颁奖仪式
2025-12-04 07:47:00
近期,在“智绘星空胜算在天—太空数据中心建设工作推进会”上,北京拟在700—800公里晨昏轨道建设运营超GW(千兆瓦)级集中式大型数据中心系统
2025-12-03 09:42:00

承武当余韵,赴江城之约——小糖乐学以“传韵江城汇,小糖太极行”为引,再启太极文化与健康同行之旅。继武当山“问道太极”盛会圆满落幕
2025-12-03 13:40:00
杭州日报讯 产品还没走下生产线,就能在虚拟世界预知它未来十年会不会开裂、变形——这样的场景正在杭州成为现实。日前,工业科技企业浙江远算科技有限公司发布“AI质检数实融合验证平台”
2025-12-03 13:41:00

12月1日,曹操出行与越疆科技正式签署战略合作协议。双方将围绕Robotaxi(自动驾驶出租车)运营场景,共同探索机器人技术在车辆清洁
2025-12-03 13:41:00

从“智慧车间”到“工业大脑”,“江苏智造”通过数据驱动全流程变革,赋能产业链协同升级
近日,全国首批15家领航级智能工厂名单发布
2025-12-03 13:41:00

12月3日,杭州瞳行科技公司正式发布国内首款AI助盲眼镜。该眼镜基于通义千问Qwen-VL、OCR等系列模型打造,具有出行避障
2025-12-03 13:41:00
橙友“橙汁儿”向橙柿直通车反映:这几天收到了短信,是杭州市公共自行车公司发来的——“尊敬的用户,由于业务升级,您之前办理的绑卡租车功能即将在2025年12月底取消
2025-12-03 13:41:00
北京上班族李想称,健身私教课结束后,教练为索要好评,直接拿他手机代笔修改达3分钟。好评既影响消费者选择,也关联平台推流与服务者收益
2025-12-03 13:41:00
找“搭子” 聊技术 谈合作每日商报讯 一个多星期前,“魔搭社区”(杭州)开发者中心启用。这个中心是国内规模最大的模型开源社区“魔搭社区”的首个线下实体空间
2025-12-03 13:41:00