- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...始在一些权威评测中取得领先。今天,国内首款具备中文逻辑推理能力的 o1 模型来了,它便是由昆仑万维推出的「天工大模型 4.0」 o1 版(英文名:Skywork o1)。这也是近一个月来,该公司在大模型及相关应用上的第三次大动作...……更多
2024-11-28 10:00:00模型,逻辑推理,中文,推理,逻辑,国产

配图来自Canva可画随着人工智能技术的快速发展,大模型以其强大的数字处理能力和深度学习能力,不断与各领域交叉融合,逐步成为产业创新的关键抓手,和驱动新质生产力的关键引擎。据国家最新公布的数据显示,截至今年...……更多
2024-05-29 09:29:00模型,逻辑,背后,国产,竞争,模型

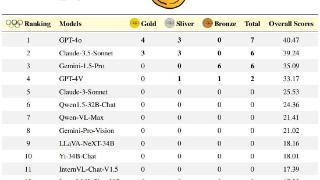
...一在今年5月的 OpenCampass 测试榜单中,TeleChat 系列模型的逻辑推理能力名列开源大模型榜单第一。作为新一代版本,TeleChat2-115B 在9月最新公布的 C-Eval 评测 Open Access 模型综合榜单中,以 86.9 分的成绩排名第一。其通用能力较 Tele……更多
2024-09-30 09:50:00万卡,重磅,模型,国产,训练,模型
...竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。其中360模型在四个评测数据集上达到第一,平均分为第三。在LongBench(多任务、中英双语、针对大语言模型长文本理解能力的评测基准)测试中,360选择其中...……更多
2024-04-14 01:04:00模型,训练,参数,模型,文本,评测
...势以外,CoE模型在其余11项指标上均优于GPT-4o,特别是「逻辑推理」、「多步推理」、「诗词赏析」这类比较具有中文特色的问题,CoE的领先优势更加明显。目前,360的「多模型协作」已经能打败并远远甩开GPT-4o,媲美o1-preview。...……更多
2024-09-21 09:50:00周鸿,前瞻,应用,模型,推理,协作

...存在一定的偏差。当前,大模型的发展具备了通用性,在逻辑推理能力上有显著提升,日趋接近人脑的特征。因此,在海淀区教委支持下,智源研究院联合与海淀区教师进修学校对齐学生测验方式,考察大模型与人类学生的学科...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测
...训练的深度推理大模型,升级后的星火X1在数学、代码、逻辑推理、文本生成、语言理解、知识问答等通用任务上效果显著提升,在模型参数比业界同类模型小一个数量级的情况下,整体效果对标OpenAI o1和DeepSeek R1,再次证明了...……更多
2025-04-22 16:50:00讯飞,星火,行业应用,司法,升级,医疗

...院工作过一段时间。在 ChatGPT 面世以后,他意识到针对大模型的研究范式存在一定的不足,于是决定来到香港中文大学读博。图 | 曾忠燊(来源:曾忠燊)前不久,曾忠燊和所在团队提出一个全新评测范式。基于这一评测范式,...……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...度30个二级维度。报告称SenseChat-Vision 5.5在基础能力-数理逻辑推理任务如图表推理、场景推理方面具备领先优势。榜单显示,在数理逻辑分析能力中,SenseChat-Vision 5.5超越国内外所有参评模型包括GPT-4o的最新版本,位列第一。Super...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力

...语言处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan3还突破“迭代式强化学习”...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

...。当发起对决后,辩论的双方各摆证据,展开你来我往的逻辑推理攻击,如果选择错误还会扣除血条,就和“逆转裁判”中的法庭辩论如出一辙。游戏共有三种结局,根据调查的过程、线索收集的完整度与最后判定的犯人,都将...……更多
2023-02-14 17:44:00侦探推理,侦探,推理,国产,冒险,推理
...“深数所”)发布了500个垂直行业多模态算料集,按照大模型应用的不同阶段(训练、推理、调优),有的放矢地提供数据源,让国产大模型厂商“寻数有路”。此次深数所发布的首批500个人工智能大模型高质量训练数据集,由...……更多
2024-04-13 01:58:00模态,行业,数据,模型,模态,人工智能

从创业狂潮到争相落地,国产大模型进入了新的竞争阶段。5月7日,零一万物官宣了一站式AI工作平台——万知。据官方介绍,万知可以帮助用户做会议纪要、周报、写作助手,还可以解读财报、论文等各类文件,也可以实现PPT...……更多
2024-05-07 18:33:00心智,中国,落地,模型,定位,国产

...方都是谁。模型辩论,主要靠的是信息理解、知识整合、逻辑推理、语言生成和对话能力。当然了,同时还能测复杂语境中信息的处理深度和迁移应变能力,反映其学习与推理的进步水平。浅玩了一下,有些议题还蛮有意思。比...……更多
2024-11-22 09:54:00指令,模型,国产,全球,模型,模态

...、多维度的综合性测评基准,由十大基础任务组成,包括逻辑推理、代码、语言理解、长文本、角色扮演等。本次报告选取了国内外具有代表性的32个大模型4月份的版本,通过多维度综合性测评,真实准确地反映了国内外大模型...……更多
2024-05-06 16:52:00腾讯,梯队,模型,腾讯,模型,能力
...加持的行业安全可信大模型,具备生成创作、多轮对话、逻辑推理等多项核心能力,通过海量通用数据与行业特有数据融合,更好的适应行业客户的业务需求,推动大模型在政企行业场景的精准落地。面向行业的安全可信行业专...……更多
2023-12-19 14:04:00海若,浪潮,模型,发展,行业,模型
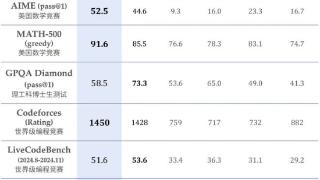
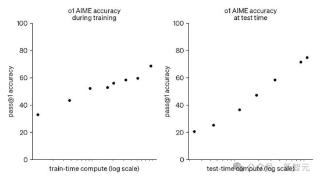
...了,这次又是重磅炸弹。昨晚,DeepSeek 上线了全新的推理模型 DeepSeek-R1-Lite-Preview,直接冲击 OpenAI o1 保持了两个多月的大模型霸主地位。在美国数学竞赛(AMC)中难度等级最高的 AIME 以及全球顶级编程竞赛(codeforces)等权威评...……更多
2024-11-22 09:50:00推理,性能,再次,重点,模型,推理
...总经理陈宁介绍,DeepEdge10是国内首创的国产14nm Chiplet大模型推理芯片,采用自主可控的国产工艺,内含国产RISC-V核,支持大模型推理部署。依托自研芯片DeepEdge10创新的D2D chiplet架构打造的X5000推理卡,已适配并可承载SAM CV大模型...……更多
2023-11-16 18:36:00云天,推理,芯片,模型,芯片,云天

...国数据-SW(09698.HK)涨超6%。消息面上,DeepSeek作为开源AI大模型,近期各大厂商纷纷宣布接入,直接引发市场对拉动算力、云服务等相关需求的预期。此外,华为计算官微给出了DeepSeek V3/R1及蒸馏模型昇腾一体机推荐配置,中国电信...……更多
2025-02-17 16:31:00大厂,李彦,港股,基建,催化,接入
...个只有8%。研究人员根据答案是否正确以及答案所包含的逻辑推理是否有效,对大语言模型的答案进行了分类。实验的第一个结果是,在每个测试重复十次的情况下,答案是不一致的。例如,在同一个测试中,有的模型十次中答...……更多
2024-06-12 18:15:00逻辑推理,推理,逻辑,模型,语言,模型

...、数字游戏等任务。这就是上海AI实验室版o1——强推理模型书生InternThinker,刚刚正式开放试用!新模型不仅在长思维能力方面有了很大提升,而且还能在推理过程中进行自我反思和纠正。先来一起看两个例子感受一下:比如官...……更多
2024-11-29 09:27:00数学题,上海,实验室,实验,数学,模型
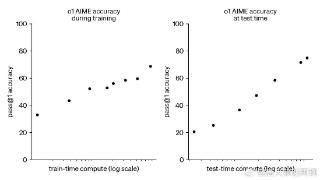
...二、社会评测与同行水平社会评测普遍认可o1 系列模型的逻辑推理能力优于 GPT-4o,但也有很多人提出了不同看法。差评XPIN邀请了理综三科的博士测评,物理评价较高,而生物、化学评价较低,综合认为o1在认知上达到硕士水平...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力

...包。遇到编程问题,就会召唤代码能力较强的DeepSeek。以逻辑推理为主的问题,可能会让智谱来应对。当然界面中所展示的任务分类比较具有概括性,实际运行过程中AI助手还对任务进行了更细粒度的划分。另外,在选择模型的...……更多
2024-08-06 09:27:00作战,模型,指标,模型,助手,厂商
...解释:“过去,ChatGPT等大模型像文科生,不擅长理科和逻辑推理。而对人类智慧来说,最底层的智慧是逻辑,逻辑之上是数学,再上面是物理、化学等科学。”去年9月,OpenAI发布的o1推理大模型改变了“文科生”形象,它擅长...……更多
2025-01-29 21:29:00上海,下岗,模型,智能,开发,企业
...真正意义上的“政策+产业”共振。事件驱动 DeepSeek线上模型版本升级至V3.18月 21日 ,DeepSeek发 布 了DeepSeek—V3.1大模型。本次升级后的模型采用了混合推理架构,即一个模型同时支持思考模式与非思考模式,用户可以使用“深度...……更多
2025-08-27 09:14:00关键期,落地,关键,应用,国产,精度

...这样的数据训练出的大模型,在部分场景的确会让人感觉逻辑推理能力更强。”但他强调,“大模型的训练数据更应追求平衡性,弱智吧这样的数据的确会对逻辑推理能力有一定帮助,但在解决实际问题时,往往需要更广泛的覆...……更多
2024-04-15 17:00:00语料库,语料,中文,数据,数据,模型

...力平台训练的全民开放大模型。升级后的讯飞星火V3.5在逻辑推理、语言理解、文本生成、数学答题、代码、多模态等七大能力上均有提升。百川智能发布Baichuan 3大模型,更好理解中文1月29日,百川智能发布超千亿参数的大语言...……更多
2024-02-05 11:37:00硅谷,字节,接口,人类,苹果,模型

...看看DoT长啥样。大模型复杂推理新框架
如前所述,DoT将逻辑推理过程建模为在单个LLM内构建有向无环图(DAG)。其框架内部管理三个关键角色:提议者:生成命题或推理步骤,添加新节点。
批评者:评估命题,识别错误、不...……更多
2024-09-24 13:36:00维图,院士,逻辑,模型,一致,理论

...地依赖于训练数据中的模式进行预测。当需要进行真正的逻辑推理时,这些模型往往无法产生合理的结果,这一发现对人工智能的发展提供了重要的参考。虽然LLM在许多领域表现优异,但其推理能力仍有待改进。【本文结束】如...……更多
2024-10-13 14:15:00逻辑推理,新论,推理,缺陷,逻辑,模型
更多关于科技的资讯:

2025年11月16日,2025雷克沙杯高校电竞挑战赛全国总决赛于“电竞重镇”成都圆满收官。本届赛事由国际高端消费类存储品牌雷克沙主办
2025-11-19 08:26:00
厦门网讯(厦门日报记者 谢瑞真)新闻工作者普遍面临用眼过度、睡眠不足等问题,长时间用眼导致眼部健康问题频发。昨日,国内首份聚焦媒体从业者的眼健康报告——《厦门市新闻工作者眼健康白皮书》(以下简称“白皮书”)正式发布
2025-11-19 08:46:00

鲁网11月18日讯为积极践行“金融为民”服务理念,精准满足广大客户多元化财富管理需求,搭建专业高效的金融交流平台,近日
2025-11-19 09:27:00

原标题:政策东风助力产业发展 年轻团队研发“灵巧手” 产品销量一年增长五倍“具身智能”开辟青年创业新赛道11月17日,中国共产党北京市第十三届委员会第七次全体会议召开
2025-11-19 10:57:00
大皖新闻讯 11月19日,记者从合肥市召开的新闻发布会获悉,“十四五”以来,合肥市以科技创新引领产业创新,获批2个国家级制造业创新中心
2025-11-19 14:05:00

第17个“双十一”落幕,星图数据显示,本届大促综合电商平台销售额为1.619万亿元,同比增长12.3%;即时零售成为今年最大黑马
2025-11-19 14:28:00

11月19日,阿里千问App在公测三天后,迅速推出多项翻译能力升级。基于Qwen模型的多语言能力,千问App推出全新实时翻译功能
2025-11-19 14:55:00

摘要:2025年Pentawards全球获奖名单揭晓,深圳市柏星龙创意包装股份有限公司报送的五件作品从全球数千件参赛作品中突围
2025-11-19 16:37:00
中新经纬11月19日电 11月19日,工业和信息化部举行新闻发布会,介绍GB 6675《玩具安全》系列强制性国家标准修订情况
2025-11-19 16:58:00

大河网讯(记者 赵檬)11月18日,由共青团郑州市委联合市委金融办、市人社局等六部门推出的“商都新活力·青春小店成长计划”正式启动
2025-11-19 17:01:00
鲁网11月19日讯2025年11月1日至2025年11月30日,中国银行泰安分行开展“臻享新户礼遇,尽享美好生活”主题活动
2025-11-19 17:14:00

2025年11月8日窪田制药控股株式会社为应对全球日益严重的“近视”问题,作为眼科医疗解决方案公司,窪田制药控股株式会社(总部
2025-11-19 20:39:00

在数智化转型加速推进的今天,企业运维正面临前所未有的挑战。传统运维模式响应慢、协作难、效率低,难以支撑业务的快速发展;运维环节中的流程堵点与系统孤岛
2025-11-19 22:02:00
《燕赵都市报》即将推出的二次元专版“漫潮”,即日起正式启动专属OC(原创角色)形象设计征集活动,诚邀社会各界设计爱好者
2025-11-19 22:17:00