- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
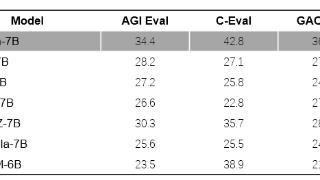
360智脑7b参数模型采用3.4万亿tokens训练
4月12日消息,360公司日前在GitHub上开源了360智脑7B(70亿参数模型)。360智脑大模型采用3.4万亿Tokens的语料库训练,以中文、英文、代码为主,开放4K、32K、360K三种不同文本长度。360表示,360K(约50万字)是当前国产开源模型文本长度最长的。

360表示,他们在OpenCompass的主流评测数据集上验证了模型性能,包括C-Eval、AGIEval、MMLU、CMMLU、HellaSwag、MATH、GSM8K、HumanEval、MBPP、BBH、LAMBADA,考察的能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。其中360模型在四个评测数据集上达到第一,平均分为第三。

在LongBench(多任务、中英双语、针对大语言模型长文本理解能力的评测基准)测试中,360选择其中与中文长文本应用最密切相关的中文单文档问答、多文档问答、摘要、Few-shot等任务进行评测,360Zhinao-7B-Chat-32K模型取得了平均分第一的成绩。

在英文大海捞针测试(NeedleInAHaystack,是将关键信息插入一段长文本的不同位置,再对该关键信息提问,从而测试大模型的长文本能力的一种方法)中,360Zhinao-7B-Chat-360K达到98%以上的准确率。360仿照SuperCLUE-200K测评基准构造了中文大海捞针测试,同样做到了98%以上的准确率。
除模型权重外,该模型的微调训练代码,推理代码等全套工具集也被一并开源,大模型相关开发者可做到“开箱即用”。
据IT之家此前报道,周鸿祎曾表示,前段时间大模型行业卷文本长度,100万字“很快将是标配”。“我们打算将这个能力开源,大家没必要重复造轮子,定为360K主要是为了讨个口彩。”他还自称“开源的信徒”,信奉开源的力量。
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2024-04-14 09:45:07
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址: