- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...始在一些权威评测中取得领先。今天,国内首款具备中文逻辑推理能力的 o1 模型来了,它便是由昆仑万维推出的「天工大模型 4.0」 o1 版(英文名:Skywork o1)。这也是近一个月来,该公司在大模型及相关应用上的第三次大动作...……更多
2024-11-28 10:00:00模型,逻辑推理,中文,推理,逻辑,国产

配图来自Canva可画随着人工智能技术的快速发展,大模型以其强大的数字处理能力和深度学习能力,不断与各领域交叉融合,逐步成为产业创新的关键抓手,和驱动新质生产力的关键引擎。据国家最新公布的数据显示,截至今年...……更多
2024-05-29 09:29:00模型,逻辑,背后,国产,竞争,模型

...一在今年5月的 OpenCampass 测试榜单中,TeleChat 系列模型的逻辑推理能力名列开源大模型榜单第一。作为新一代版本,TeleChat2-115B 在9月最新公布的 C-Eval 评测 Open Access 模型综合榜单中,以 86.9 分的成绩排名第一。其通用能力较 Tele……更多
2024-09-30 09:50:00万卡,重磅,模型,国产,训练,模型
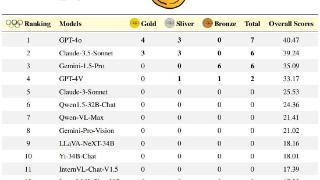
...竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。其中360模型在四个评测数据集上达到第一,平均分为第三。在LongBench(多任务、中英双语、针对大语言模型长文本理解能力的评测基准)测试中,360选择其中...……更多
2024-04-14 01:04:00模型,训练,参数,模型,文本,评测
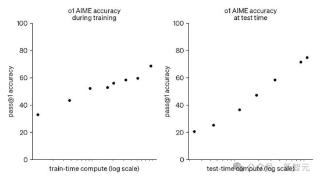
...势以外,CoE模型在其余11项指标上均优于GPT-4o,特别是「逻辑推理」、「多步推理」、「诗词赏析」这类比较具有中文特色的问题,CoE的领先优势更加明显。目前,360的「多模型协作」已经能打败并远远甩开GPT-4o,媲美o1-preview。...……更多
2024-09-21 09:50:00周鸿,前瞻,应用,模型,推理,协作

...存在一定的偏差。当前,大模型的发展具备了通用性,在逻辑推理能力上有显著提升,日趋接近人脑的特征。因此,在海淀区教委支持下,智源研究院联合与海淀区教师进修学校对齐学生测验方式,考察大模型与人类学生的学科...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测

...院工作过一段时间。在 ChatGPT 面世以后,他意识到针对大模型的研究范式存在一定的不足,于是决定来到香港中文大学读博。图 | 曾忠燊(来源:曾忠燊)前不久,曾忠燊和所在团队提出一个全新评测范式。基于这一评测范式,...……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...度30个二级维度。报告称SenseChat-Vision 5.5在基础能力-数理逻辑推理任务如图表推理、场景推理方面具备领先优势。榜单显示,在数理逻辑分析能力中,SenseChat-Vision 5.5超越国内外所有参评模型包括GPT-4o的最新版本,位列第一。Super...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力

...语言处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan3还突破“迭代式强化学习”...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川
...“深数所”)发布了500个垂直行业多模态算料集,按照大模型应用的不同阶段(训练、推理、调优),有的放矢地提供数据源,让国产大模型厂商“寻数有路”。此次深数所发布的首批500个人工智能大模型高质量训练数据集,由...……更多
2024-04-13 01:58:00模态,行业,数据,模型,模态,人工智能

从创业狂潮到争相落地,国产大模型进入了新的竞争阶段。5月7日,零一万物官宣了一站式AI工作平台——万知。据官方介绍,万知可以帮助用户做会议纪要、周报、写作助手,还可以解读财报、论文等各类文件,也可以实现PPT...……更多
2024-05-07 18:33:00心智,中国,落地,模型,定位,国产

...、多维度的综合性测评基准,由十大基础任务组成,包括逻辑推理、代码、语言理解、长文本、角色扮演等。本次报告选取了国内外具有代表性的32个大模型4月份的版本,通过多维度综合性测评,真实准确地反映了国内外大模型...……更多
2024-05-06 16:52:00腾讯,梯队,模型,腾讯,模型,能力

...方都是谁。模型辩论,主要靠的是信息理解、知识整合、逻辑推理、语言生成和对话能力。当然了,同时还能测复杂语境中信息的处理深度和迁移应变能力,反映其学习与推理的进步水平。浅玩了一下,有些议题还蛮有意思。比...……更多
2024-11-22 09:54:00指令,模型,国产,全球,模型,模态
...加持的行业安全可信大模型,具备生成创作、多轮对话、逻辑推理等多项核心能力,通过海量通用数据与行业特有数据融合,更好的适应行业客户的业务需求,推动大模型在政企行业场景的精准落地。面向行业的安全可信行业专...……更多
2023-12-19 14:04:00海若,浪潮,模型,发展,行业,模型
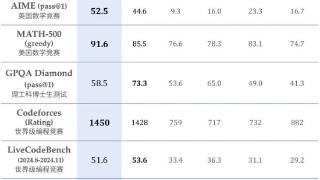
...了,这次又是重磅炸弹。昨晚,DeepSeek 上线了全新的推理模型 DeepSeek-R1-Lite-Preview,直接冲击 OpenAI o1 保持了两个多月的大模型霸主地位。在美国数学竞赛(AMC)中难度等级最高的 AIME 以及全球顶级编程竞赛(codeforces)等权威评...……更多
2024-11-22 09:50:00推理,性能,再次,重点,模型,推理
...总经理陈宁介绍,DeepEdge10是国内首创的国产14nm Chiplet大模型推理芯片,采用自主可控的国产工艺,内含国产RISC-V核,支持大模型推理部署。依托自研芯片DeepEdge10创新的D2D chiplet架构打造的X5000推理卡,已适配并可承载SAM CV大模型...……更多
2023-11-16 18:36:00云天,推理,芯片,模型,芯片,云天
...个只有8%。研究人员根据答案是否正确以及答案所包含的逻辑推理是否有效,对大语言模型的答案进行了分类。实验的第一个结果是,在每个测试重复十次的情况下,答案是不一致的。例如,在同一个测试中,有的模型十次中答...……更多
2024-06-12 18:15:00逻辑推理,推理,逻辑,模型,语言,模型

...、数字游戏等任务。这就是上海AI实验室版o1——强推理模型书生InternThinker,刚刚正式开放试用!新模型不仅在长思维能力方面有了很大提升,而且还能在推理过程中进行自我反思和纠正。先来一起看两个例子感受一下:比如官...……更多
2024-11-29 09:27:00数学题,上海,实验室,实验,数学,模型
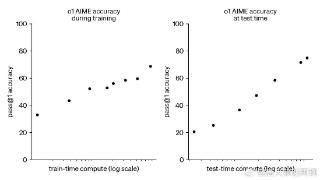
...二、社会评测与同行水平社会评测普遍认可o1 系列模型的逻辑推理能力优于 GPT-4o,但也有很多人提出了不同看法。差评XPIN邀请了理综三科的博士测评,物理评价较高,而生物、化学评价较低,综合认为o1在认知上达到硕士水平...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力

...看看DoT长啥样。大模型复杂推理新框架
如前所述,DoT将逻辑推理过程建模为在单个LLM内构建有向无环图(DAG)。其框架内部管理三个关键角色:提议者:生成命题或推理步骤,添加新节点。
批评者:评估命题,识别错误、不...……更多
2024-09-24 13:36:00维图,院士,逻辑,模型,一致,理论

...包。遇到编程问题,就会召唤代码能力较强的DeepSeek。以逻辑推理为主的问题,可能会让智谱来应对。当然界面中所展示的任务分类比较具有概括性,实际运行过程中AI助手还对任务进行了更细粒度的划分。另外,在选择模型的...……更多
2024-08-06 09:27:00作战,模型,指标,模型,助手,厂商

...这样的数据训练出的大模型,在部分场景的确会让人感觉逻辑推理能力更强。”但他强调,“大模型的训练数据更应追求平衡性,弱智吧这样的数据的确会对逻辑推理能力有一定帮助,但在解决实际问题时,往往需要更广泛的覆...……更多
2024-04-15 17:00:00语料库,语料,中文,数据,数据,模型

...力平台训练的全民开放大模型。升级后的讯飞星火V3.5在逻辑推理、语言理解、文本生成、数学答题、代码、多模态等七大能力上均有提升。百川智能发布Baichuan 3大模型,更好理解中文1月29日,百川智能发布超千亿参数的大语言...……更多
2024-02-05 11:37:00硅谷,字节,接口,人类,苹果,模型

...地依赖于训练数据中的模式进行预测。当需要进行真正的逻辑推理时,这些模型往往无法产生合理的结果,这一发现对人工智能的发展提供了重要的参考。虽然LLM在许多领域表现优异,但其推理能力仍有待改进。【本文结束】如...……更多
2024-10-13 14:15:00逻辑推理,新论,推理,缺陷,逻辑,模型

...为单位数,提升最多的是代码能力,仅有提升9%,其次是逻辑推理(8%),文本生成、知识问答、多模态能力则均只有7%。此前科大讯飞在8月15日发布星火V2.0时,七大能力大幅度提升,其中语言理解能力提升78%,文本生成、知识...……更多
2023-10-24 16:15:00跌停,讯飞,市值,股价,蒸发,讯飞

...引入思想链(CoT,Chain of Thought)的概念,提高了大语言模型(LLM,large language models)在复杂推理任务上的性能,例如算术推理、常识推理和符号推理等。图 | 金明宇(来源:金明宇)CoT 的原理是通过提供推理过程的示例,来教...……更多
2024-03-15 10:41:00罗格,罗格斯,推理,模型,团队,概念

...通常被设定了几个高频关键词,但一旦遇到稍难或者带些逻辑推理的问题时便无计可施。这是横亘在过去企业数字化最普遍同时也是最棘手的问题。一般来说,以往的智能客服的聪明程度往往取决于它背后有多少人工,你标记的...……更多
2023-11-21 18:29:00模型,国产,时刻,智能,模型,共创

...,尽管这些模型在处理自然语言方面表现卓越,但在复杂逻辑推理任务中,人类和语言模型都会受到语义内容合理性和可信度的影响,表现出类似的错误倾向。研究背景人类在推理过程中存在两种系统:“直觉系统”和“理性系...……更多
2024-08-19 13:49:00局限性,推理,人类,任务,研究,模型

...下,夸克大模型具备较好的语义理解、知识掌握与应用、逻辑推理能力,整体水平达到行业一流水平。另外,在最新的百亿参数测试集中,夸克同样在法律、医疗、问答等多个领域中排名第一,夸克大模型在不同参数量级的对比...……更多
2023-11-24 13:53:00夸克,模型,量级,榜首,评测,性能
更多关于科技的资讯:

原标题 | 小心!高铁车厢的电源插座,真的有点儿伤手机元旦一过,大学生的寒假和打工人的春节都不远了,一年一度的春运又要来了
2025-01-18 09:50:00
央媒看太原中国的消费品以旧换新政策在2025年继续实施。近日,中国国际电视台以《中国“以旧换新”政策继续提振消费活力》为题
2025-01-18 07:35:00

快科技1月18日消息,日前,吉利官方宣布,银河L6 EM-i正式开启预售,新车共推出5款车型,预售价区间为9.28-11
2025-01-18 07:57:00
河北日报讯(记者米彦泽)作为制造业大省,河北如何以数字技术赋能制造业高质量发展?1月14日,河北省政府办公厅印发《河北省数字技术赋能制造业高质量发展实施方案》提出
2025-01-18 07:58:00

初冬到春末,如果你到南方的一些菜市场转转,会发现有一种蔬菜特别鲜嫩,绿油油的,十分诱人,它就是西洋菜。北方人可能第一次听过这种菜
2025-01-18 08:27:00


快科技1月18日消息,龙芯中科公布了业绩,预计2024 年年度实现营业收入5.06亿元左右,与上年同期基本持平;预计实现归属于母公司所有者的净利润为-6
2025-01-18 08:57:00

快科技1月18日消息,据报道,此前因极越汽车原地解散,在职员工维权一事也迎来圆满结局。两名原极越汽车员工向媒体透露,1月17日已经收到工资和“N+1”补偿
2025-01-18 08:57:00

本文转自:人民网-江苏频道人民网记者 马晓波南京市建邺区产业科技创新大会暨河西中央科创区建设启动仪式。人民网记者 马晓波摄1月17日
2025-01-18 09:04:00
本文转自:人民网-北京频道人民网北京1月18日电 (记者李博)日前,2025北京数据交易成果报告会举行。会上集中发布了北京国际大数据交易所系列成果
2025-01-18 09:18:00

快科技1月18日消息,据央视新闻报道,“一男子造谣新能源车彻底进不了海南被行拘”一事,迎来最新进展。海口市公安局副局长廖绪德表示
2025-01-18 09:27:00
南报网讯(记者李都)近日,位于南京江北新区的全国高校区域技术转移转化中心南京生物医药分中心传来好消息,东南大学顾忠泽教授团队的“器官芯片”项目拿到了江苏银行1000万元的授信支持
2025-01-18 09:33:00
本文转自:人民网-湖南频道人民网长沙1月18日电 (记者吴茜薇)无人机配送快递、植保无人机下田“干活”、无人机应急救援……如今
2025-01-18 09:43:00
本文转自:人民网人民网北京1月18日电 近日,中国五矿在京召开科技创新大会,正式发布了20项重大科技创新成果和13项“揭榜挂帅”重大攻关任务需求
2025-01-18 09:42:00

这一代PC平台上,AMD、NVIDIA无论是处理器还是显卡,都停留在4nm级别,Intel的酷睿Ultra 200S系列虽然升级为3nm
2025-01-17 23:57:00