- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

本文转自:科技日报又一通用模型发布SAM是如何做到“分割一切”的视觉中国供图SAM是一类处理图像分割任务的通用模型。与以往只能处理某种特定类型图片的图像分割模型不同,SAM可以处理所有类型的图像。相比于以往的图...……更多
2023-04-17 01:26:00模型,图像,杨戈,数据,物体,提示

...凌晨,OpenAI再次扔出一枚深水炸弹,发布了首个文生视频模型Sora。据介绍,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。目前官网上已经更新了48个视频demo,在这...……更多
2024-02-16 18:44:00文生,奥尔,奥尔特曼,特曼,模型,提示

...。而这些视频全都是通过OpenAI2月15日发布的最新视频生成模型Sora制作的,用户震惊之余,也给予了Sora高度评价,将其描述为“绝无仅有”和“游戏规则改变者”。图片来源:X平台Sora采用了OpenAI文生图模型DALL-E3背后的强大技术...……更多
2024-02-17 21:07:00颠覆,核心,优势,报告,影视,行业

...被打破——OpenAI又出王炸,发布了可以生成60秒视频的AI模型Sora。OpenAI官宣Sora。同样在2月16日发布的谷歌最新多模态模型Gemini Pro 1.5,则被Sora迅速夺走了关注度。网友为Gemini和Sora制作的梗图。根据OpenAI官方发布的推文和技术报...……更多
2024-02-18 06:20:00生成,一口,空降,画质,模型,一口气

OpenAI周四发布了首个视频生成模型Sora,并展示了几段效果炸裂的演示视频。一位X用户分享了Sora生成的一名女子在东京街头漫步的视频,并评论称:“OpenAI今天宣布了Sora,它使用混合扩散和变压器模型架构生成长达1分钟的视频...……更多
2024-02-16 22:16:00马斯,马斯克,生成,模型,人类,视频

商汤发布开源社区最大最强多模态多任务通用大模型“书生2.5” 3月14日,商汤科技发布多模态多任务通用大模型“书生(INTERN)2.5”,在多模态多任务处理能力方面实现多项全新突破,其卓越的图文跨模态开放任务处理能力可...……更多
2023-03-15 13:30:00商汤,模态,书生,模型,任务,社区

...DetCon和ReLICv2。
除此之外,Odin方法不仅可以应用在ResNet模型中,还可以应用到更复杂的模型中,如SwimTransformer。在数据上,Odin框架学习的优势很明显,那在可视化的图像中,Odin的优势在何处体现了呢?将使用Odin生成的分割图...……更多
2023-01-31 13:58:00物体,研究,物体,图像,目标,网络

...DeepETPicker优选简化标签来替代真实标签,并采用更高效的模型架构、更丰富的数据增强技术和重叠分区策略来提升小训练集时模型的性能;为提高颗粒定位的速度,DeepETPicker采用图形处理器(GPU)加速的平均池化-非极大值抑制后处...……更多
2024-03-12 18:50:00大分,大分子,人工智能,中国,人工,定位

...凌晨,OpenAI再次扔出一枚深水炸弹,发布了首个文生视频模型Sora。据介绍,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。目前官网上已经更新了48个视频demo,在这...……更多
2024-02-16 18:20:00文生,模型,网友,工作,视频,模型

...模方法逐渐成为实现复杂问题的关键手段之一。高斯混合模型(GaussianMixtureModel,简称GMM)作为一种经典的概率建模技术,已经被广泛地应用于数据挖掘、模式识别、图像处理等领域。本文将介绍什么是高斯混合模型,它的基本...……更多
2023-10-23 03:37:00高斯,概率,混合,模型,应用,高斯

...岗”。根据各帖子发布者透露,这些AI照片都出自同一个模型,Chilloutmix。
多个模型融合进化,照片级AI诞生ChilloutMix,二月初出现在模型分享社区CivitAI(不少爱好者称之为c站)。不到两周时间,下载数量超过5万。简单来说,...……更多
2023-02-15 15:50:00网恋,真假,诈骗,网友,美女,模型

...况,这一举动引起了业界的广泛关注。然而,在视觉语言模型的角逐中,谷歌也不甘示弱。
近日,Google Research、Google DeepMind 和 Google Cloud 共同推出了一个更小、更快、更强大的视觉语言模型(VLM)——PaLI-3,该模型与相似的体...……更多
2023-10-17 16:31:00更快,模型,视觉,语言,训练,模型

AI视觉领域迎来新模型“炸场”,图像识别门槛大幅降低。据财联社报道,Meta上周三发布了一个人工智能模型,可以从图像中挑选出单个对象,以及一个图像注释数据集。该模型名为Segment Anything Model(SAM),Meta官方表示这是有...……更多
2023-04-17 10:44:00上市公司,视觉,时刻,规模,市场,公司

...染、创造逼真视觉效果的关键组件,负责将二维或三维的模型、纹理、光照等数据,转化为人们肉眼可见的二维图像。渲染引擎的工作原理基于计算机图形学和视觉感知理论。它首先接收来自应用程序的几何数据(如顶点坐标/...……更多
2024-06-28 13:06:00一文,引擎,引擎,图像,二维,纹理

...美全息(NASDAQ:WIMI)构建基于深度迁移学习的图像分类融合模型,提高图像分类的准确性和效率深度学习在计算机视觉领域得到越来越广泛的应用,尤其是在图像分类任务上。然而,由于数据集的限制和模型的复杂性,深度学习模...……更多
2023-10-23 16:02:00图像,分类,全息,深度,模型,准确性

...风格或纹理应用于文字和短语。Midjourney:Midjourney 的 V.5 模型在图像生成领域是一个重要的里程碑,它展示了在效率、连贯性和高分辨率方面的显著改进。最新的 alpha 版本,Midjourney V.6,引入了额外的增强功能,如更精准的提示...……更多
2023-12-29 05:02:00之年,人工智能,人工,智能,生成,人工智能

...构成威胁,Arm 和台积电将获胜。”有网友说到苹果在大模型发展上的状况。也有网友认为,苹果在大模型上的发力将为其在未来的手机市场竞争中带来优势。他们认为,开源模型加上移动设备的本地数据,即本地化的原生 LLM,...……更多
2023-12-26 14:06:00模型,生态,模态,零碎,苹果,模型

...想要达成通用人工智能 AGI 的终极目标,首先要达成的是模型要能完成人类所能轻松做到的任务。为了做到这一点,大模型开发的关键指导之一便是如何让机器像人类一样思考和推理。诸如注意力机制和思维链(Chain-of-Thought)等...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务

...赢家!一篇是Rich Human Feedback for Text-to-Image Generation,受大模型中的RLHF技术启发,团队用人类反馈来改进Stable Diffusion等文生图模型。这项研究来自UCSD、谷歌等,共同一作华南农业大学校友Youwei Liang、清华校友……更多
2024-06-21 09:21:00华南,清华,农大,获奖,校友,生成

...on CPU、骁龙8 Gen3等在内的王炸产品,后有联系拿出能跑大模型的个人PC。还有谷歌20亿追投Anthropic,并曝光多模态模型Gemini和工具Stubbs,将为用户更多便捷和创新的应用开发方式。Meta公布第三季度财报,实现23%的营收增长,是公...……更多
2023-10-30 15:31:00高通,三代,硅谷,模型,个人,模型
本文转自:中国科学报南开大学等让人工智能模型训练提速10倍以上本报讯(通讯员高雨桐 记者陈彬)南开大学、南开国际先进研究院(深圳福田)教授程明明团队发布了一项国际联合研究成果MDT,与人工智能文字生成视频大...……更多
2024-04-03 07:20:00人工智能,提速,人工,模型,训练,智能

...有各自的技术优势,但也存在一定的不足,如创建完一个模型后,还需要专业软件对模型进行后处理,以及对于扫描光源环境的匹配度,不能做到控制自如等。国内全栈式3D数字化解决方案提供商积木易搭推出了一款基于非接触...……更多
2023-02-02 20:46:00三维,非接触式,非接触,优势,结构,技术

...。他在自然语言处理领域取得了显著成果,特别是在语言模型和对话系统方面。Zhu的工作使得机器能够更自然地与人类进行交互,提高了智能助手的性能和用户体验。RichardSutton,强化学习之父、阿尔伯塔大学教授。他对强化学...……更多
2024-03-24 08:39:00人工智能,美国,院士,科学院,人工,智能

...香港电影修复计划”中,技术人员就曾首次将AIGC视觉大模型引入到影片修复,对大模型进行了生成质量和效率等方面的算法优化。如今随着Sora等大模型在视觉领域的发展,视觉大模型不仅运用在视频生成、修改、融合和延伸等...……更多
2024-04-22 20:30:00卖身契,喜剧,魅力,电影,电影,火山
...,并基于该标注数据提取不同颜色空间的特征训练决策树模型。为了保证结果的鲁棒性,作者使用5张不同情况下的图像,包括晴天、阴影、光反射、雨天等,从图像中选取135000个像素进行训练,经过消除噪声等步骤后生成的掩...……更多
2023-12-02 09:02:00视觉,机器,计算机,产业,农业,应用
...步介绍,Akool的主要自研架构包括用于数字虚拟人的扩散模型和3维NerF结构的生成模型框架、基于能量的扩散模型框架。吕家俊告诉36氪,用这些自研框架开发的图片视频应用,具有生成结果质量高,清晰度高,多样性好等特点。...……更多
2023-05-30 08:11:00电商,物料,高质量,图像,文字,帮助

◎当地时间2月15日,OpenAI发布了最新的视频生成模型Sora。出色的视频制作能力瞬间“点燃”科技圈。英伟达人工智能研究院首席研究科学家JimFan直言,这是视频生成领域的GPT-3时刻。360集团创始人、董事长周鸿祎则称,随着Sora...……更多
2024-02-17 21:03:00核心,优势,报告,技术,日本,视频

...AI工具的更多信息,IT之家整理如下。官方介绍称,EmuEdit模型仅用文字指令就可以准确编辑图像,而通过分解文字转视频(Text-to-Video,T2V)的生成过程,开发团队公布了一种名为EmuVideo的方法,可以改善最终生成视频的品质和多...……更多
2023-11-20 11:38:00图像编辑,图像,工具,生成,图像,模型

...,腾讯和清华大学、香港科技大学联合推出全新图生视频模型“Follow-Your-Click”,目前已经上架GitHub(代码四月公开),同时还发表了一篇研究论文(IT之家附DOI:2403.08268)。这款图生视频模型主要功能包括局部动画生成和多对象...……更多
2024-03-16 02:23:00清华大学,腾讯,清华,模型,全新,联合

...,OpenAI再投一颗“深水炸弹”,毫无预兆发布的文生视频模型Sora,让AI圈又一次“一夜变天”。一是时长,二是逼真程度,Sora实现了两个老大难问题的同时解决,以至于外界毫不吝啬地将其形容为“颠覆性”的存在。360创始人...……更多
2024-02-19 00:15:00冲击波,冲击,文生,视频,模型,北京
更多关于科技的资讯:
连日来,百度旗下的萝卜快跑在武汉迅速扩张引来各界关注。百度港股股价连续两日大涨,资本市场也刮起了无人驾驶风,一众企业站上了风口浪尖
2024-07-12 00:05:00
7月11日,媒体援引知情人士消息称,苹果告诉供应商和合作伙伴,苹果公司计划在今年下半年出货至少9000万部iPhone 16设备
2024-07-12 01:08:00
本报讯(记者 张恒新)7月8日,毕节市“5G+网络安全靶场”发布会在毕节市工业职业技术学院举行。发布会上开展了网络安全攻防演练等活动
2024-07-12 06:03:00
本报讯(四川日报全媒体记者 王密)近日,主打“复古”“通勤”的某单车品牌西南首店在成都城南亮相。该门店销售人员介绍,伴随着成都的“骑行热”
2024-07-12 06:09:00
□四川日报全媒体记者 罗海韵 陈云鸽全国首部AIGC生成式连续性叙事科幻短剧集《三星堆:未来启示录》7月8日上线在抖音平台与观众见面
2024-07-12 06:09:00
本文转自:人民日报防晒衣如何更防晒?(经济新方位·身边的创新)——产业链上下游协同,从需求中找市场本报记者 王崟欣防晒衣
2024-07-12 06:30:00
本文转自:环球时报据报道,自动驾驶出行服务平台萝卜快跑(Apollo Go)目前在武汉的辐射面积3000多平方公里,触达人口超770万
2024-07-12 06:52:00
起步、转弯、列队……杭州西湖区飞步科技总部,一块巨大的屏幕实时展示着宁波舟山港码头的忙碌景象——梅山港区的无人驾驶集卡(集装箱卡车)车队井然有序地运作
2024-07-12 07:34:00

据说苹果将其四棱变焦镜头带到了iPhone16Pro和iPhone16ProMax,但在谈到规格时,据说这两款旗舰都配备了据报道将保留的摄像头与iPhone15ProMax相比没有变化
2024-07-11 22:18:00
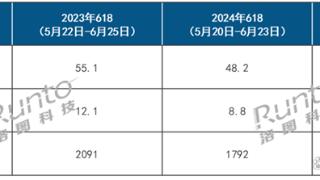
一转眼,上半年已过完,对于智能投影机市场来说,“中考”以失败而告终。对于下半年来说,“双11”和“双12”以及年底旺季能否让智能投影机市场迎来翻身仗
2024-07-11 22:18:00

苹果早在2017年就发布了iPhoneX,这标志着iPhone自2007年首次推出以来的十年,该设备在全屏设计和FaceID方面向前迈出了一大步
2024-07-11 22:18:00

苹果的iPhone15Pro和iPhone15ProMax最初计划使用触觉反馈按钮,而不是我们在商业机型上看到的常规按钮
2024-07-11 22:19:00

“性能梦想机”真我GT6已经官宣,Redmi的性能魔王,马上也要来了。小米高层和合作方,已经在为RedmiK70至尊版频频预热
2024-07-11 22:19:00

高跟踩踏照样没事!7月2日,OPPO发布耐用战神——OPPOA3,起售价为1599元(8+256G)。OPPOA3还有12+256G
2024-07-11 22:19:00
