- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...。OpenAI表示,新模型在物理、化学和生物等学科的挑战性基准测试中,表现超过人类专家。在国际数学奥林匹克(IMO)资格考试中,新模型得分超83%,远高于GPT-4o的13%。在Codeforces编程竞赛中,o1模型的成绩达到了前89%,而GPT-4o仅...……更多
2024-09-13 16:44:00复旦,相关性,概率,推理,模型,教授

...性思考,并根据环境反馈调整推理过程。QwQ-32B 在一系列基准测试中进行了评估,测试了数学推理、编程能力和通用能力。其中,在测试数学能力的AIME24评测集上,以及评估代码能力的LiveCodeBench中,千问QwQ-32B表现与DeepSeek-R1相当...……更多
2025-03-06 07:42:00阿里,推理,模型,参数,全新,能力
...”和“朝鲜”。结果在节目播出后,不少中国网友还有懂中文的外国网友都被这家法国媒体如此低级下作的手法给恶心到了。“记者难道以为欧洲没有人懂中文了么?你的翻译跟他们说的完全不同。用这种谣言的方式编造新闻,...……更多
2025-03-04 23:42:00国恩,大车,分子,法国,中国,新疆
...天机器人“巴德”(Bard)的首次公开演示中犯了令人尴尬的事实性错误。这些人工智能工具应用如此广泛——出错的机会如此之多——引发了人们的兴趣、争论、焦虑和兴奋。“这是人类首次真正地与电脑对话,”美国研究机构和...……更多
2023-12-30 07:56:00人工智能,人工,对话,智能,人工智能,生成

...型有依靠自身无法解决的“幻觉”问题,导致了准确性和事实性无法保证。所以对它的使用需要有所限定,在对可靠性和真实性要求不高的情况下非常有用。针对大模型也不擅长做数学计算,王文广说:“我的建议是,可以通过...……更多
2023-12-21 18:02:00腾讯,风向,模型,业界,应用,专家

...AI幻觉、防止被AI欺骗?我们的心得是,要始终对AI生成的事实性描述保持警惕。可以使用搜索引擎核查出处,一般而言,若出处为权威机构,信息就更可靠。也可以使用多个AI联网搜索,交叉印证和检查某个AI生成的内容。 现在A...……更多
2025-04-02 21:37:00死亡率,数据,数据,幻觉,信息,生成
...实则与用户输入不一致(忠实性幻觉)或者不符合事实(事实性幻觉)的内容。正因如此,我们应保持谨慎态度,结合实际情况进行人工核实和判断,确保建议的准确性和适用性。在享受人工智能带来的各种便利服务的同时,不...……更多
2025-03-31 10:44:00算法,误区,人工智能,人工,智能,投资

...量低于 Llama 3.1 的 4050 亿,但两者性能接近。并且在多个基准测试中与 GPT-4o、Anthropic 的 Claude 3.5 Sonnet 媲美。今年 2 月,Mistral AI 推出了最初的 Large 模型,其上下文窗口包含 32,000 个 token,新版模型在此……更多
2024-07-26 09:36:00模型,基准,多语,测试,性能,生成

...越重要。百融云创参加的这场“考试”名叫检索增强生成基准测评,这是对大模型处理“幻觉问题”的能力测评,也是对大模型生成内容准确性的测评。尽管大模型带来令人兴奋的技术进步,但“幻觉”一直是制约其发展的主要...……更多
2024-03-28 16:16:00精度,幻觉,模型,结果,模型,幻觉

...100多万专属评测数据集,评测结果客观性跻身国内外主流基准第一阵营。依托自研大模型评测智能体,支持评测数据自学习、用例自编排、执行自适应,同比评测周期缩短90%以上,已服务政府部委、重点央企,将为更多合作伙伴...……更多
2024-05-25 07:21:00潮起,模型,中国,中国移动,移动,模态
...力强项,比如,背靠今日头条和抖音的豆包,更擅长解答事实性、日常性的问题,也试图以轻松、有趣的互动体验作为差异化竞争点。相比之下,腾讯元宝可能会获得专业人士们的青睐,只不过这也有可能限制其在大众用户中的...……更多
2024-06-03 16:59:00腾讯,元宝,波澜,助手,腾讯,元宝

...-4V在奋力追平GPT-4V的同时,LLaVa-1.6也展现出强大的零样本中文能力。LLaVa-1.6不需要额外训练便具备杰出的中文理解和运用能力,其在中文多模态场景下表现优异,使得用户不必学习复杂的“prompt”便可以轻松上手,这对于执行“...……更多
2024-02-10 21:04:00性能,模型,模态,训练,数据,卷上

...批社区成员单位共同发布了国内首个运维大语言模型评测基准OpsEval。中科院计算机网络信息中心副研究员裴昶华对OpsEval的社区定位、榜单结果解读以及后续规划进行了分享。目前OpsEval已经拥有近一万七千道多场景评测题目,评...……更多
2023-12-20 13:45:00挑战赛,决赛,成功,国际,模型,南开大学
...会(CCL2024)挑战赛两项冠军:TeleAI 在 CCL2024 大会上获得中文空间语义理解评测和古文历史事件类型抽取评测两项第一名。其中,在古文历史事件类型抽取评测任务挑战赛中,更是在所有子任务均取得第一名的情况下获得了综合...……更多
2024-09-30 09:50:00万卡,重磅,模型,国产,训练,模型

本文转自:新华网过去的一个多月中,汽车之家《新能源突破计划》基于深度的用户洞察,拆解消费者对新能源车的需求和痛点,站在用户角度进行评测,以实车对撞、拆解分析、电池包浸水、智能辅助驾驶实际道路测试等实...……更多
2024-01-07 19:44:00新能源,基准,突破,测试,安全,之家
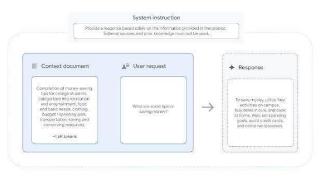
...eepMind 团队于 12 月 17 日发布博文,宣布推出 FACTS Grounding 基准测试,评估大型语言模型(LLMs)根据给定材料是否准确作答,并避免“幻觉”(即捏造信息)的能力,从而提升 LLMs 的事实准确性,增强用户信任度,并拓展其应用...……更多
2024-12-19 09:32:00照妖镜,基准,幻觉,模型,语言,示例
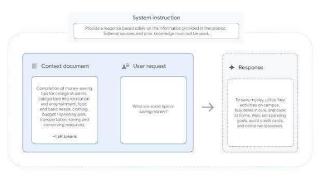
...eepMind 团队于 12 月 17 日发布博文,宣布推出 FACTS Grounding 基准测试,评估大型语言模型(LLMs)根据给定材料是否准确作答,并避免“幻觉”(即捏造信息)的能力,从而提升 LLMs 的事实准确性,增强用户信任度,并拓展其应用...……更多
2024-12-19 09:32:00照妖镜,基准,幻觉,模型,语言,示例

...旨在建立大模型标准符合性名录,是基于官方大模型测试基准的权威评测,被业内称为AI大模型“国标”。受此消息影响,12月25日三六零强势涨停。但26日受大盘整体弱势影响,该股开盘短暂震荡。AI大模型高速发展随着ChatGPT应...……更多
2023-12-26 14:16:00人工智能,国标,人工,模型,结果,智能

...早了1700多年。还有人声称张衡的地动仪能预测地震。但事实上,关于张衡候风地动仪的记载,仅仅只有史书上的196个字。其中描述地动仪内部结构的内容更是只有“中有都柱,傍行八道,施关发机”这12个意义隐晦的字。张衡候...……更多
2024-06-07 17:52:00张衡,地动仪,教科书,教科,地动仪,张衡

...显著超越世界领先技术,在国际权威的通用语言理解评估基准GLUE上,得分首次突破90分,获得全球第一。在2020年的全球最大语义评测SemEval2020上,ERNIE摘得5项世界冠军,该技术也被全球顶级科技商业杂志《麻省理工科技评论》官...……更多
2023-02-07 22:57:00时能,评分,国产,全球,语义,全球

...The Information发布的评测报告,AMD的Instinct MI300X GPU在AI推理基准测试中的表现与NVIDIA的H100 GPU相当,显示出AMD在高性能AI计算领域的进步。这份评测报告由MLCommons提供数据,在测试中,AMD的MI300X GPU以及NVIDIA的……更多
2024-09-05 11:09:00逊色,模型,测试,评测报告,戈麦斯,领域
...大学等联合发布了大模型评测体系3.0,暨“方升”大模型基准测试体系。据介绍,测试指标重点强化行业和场景导向的能力考查,提出了自适应动态测试方法,测试数据超过百万条,并首次推出面向行业、通用、应用、安全的评...……更多
2023-12-26 17:41:00信通,人工智能,中国,人工,伙伴,智能

...繁抑制思考会导致死循环训出模型后,团队选用3个推理基准测试,把s1-32B和OpenAI o1系列、DeepSeek-R1系列、阿里通义Qwen2.5系列/QWQ、昆仑万维Sky系列、Gemini 2.0 Flash Thinking实验版等多个模型进行对比。3个推理基准测试如下:AIME24……更多
2025-02-07 15:14:00推理,模型,成本,模型,团队,推理

...,依托搜索平台,夸克大模型拥有高质量的各类数据,在中文语境下,模型能力处在行业领先水平。在教育、医疗等垂直领域中,夸克在对话、解题上的能力取得了新的突破,是国产自研大模型的优秀代表之一。同时,在安全性...……更多
2023-11-24 13:53:00夸克,模型,量级,榜首,评测,性能

...要好。
最后,与开源模型一起,Mistral还贡献了一个开源基准测试MM-MT-Bench,用于在实际场景中评估视觉语言模型。技术细节当前的多模态大模型基本上都是:模态编码器 + 投影模块 + 大语言模型主干。如果需要多模态输出,后...……更多
2024-11-20 09:43:00模态,竞技场,竞技,报告,技术,模态

...日新·商量”又拿了金牌!今日,中文多模态大模型测评基准SuperCLUE-V发布10月榜单:商汤日日新·商量多模态大模型(SenseChat-Vision5.5)凭借多个任务上的出色表现,总得分位列国内大模型第一梯队,智夺金牌。商量多模态大模型...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力

...性消息——结果没多久,Reflection 70B就被打假了:公布的基准测试结果和他们的独立测试之间存在显著差异。无论是AI研究者,还是第三方评估者,都无法复现Matt Shumer所声称的结果。根据Artificial Analysis的数据,Reflection 70B在基准...……更多
2024-10-08 09:47:00神坛,光速,团队,世界,模型,基准

...架构。以下两张表总结了 MMCL 方法的详细属性。数据集和基准大多数 MMCL 数据集是从最初为非连续学习任务设计的知名数据集中改编而来的,研究人员通常会利用多个数据集或将单个数据集划分为多个子集,以模拟 MMCL 环境中的...……更多
2024-11-14 09:46:00模态,清华,中文,联合,学习,模态
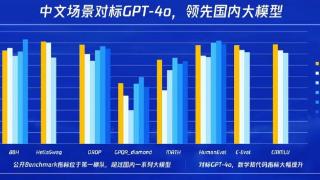
...升100%,推理成本降低50%,解码速度提升20%,效果在多个基准测试上对标GPT-4o,第三方测评居国内第一。在腾讯全球数字生态大会上,腾讯公司副总裁、云与智慧产业事业群COO兼腾讯云总裁邱跃鹏宣布,腾讯混元Turbo在腾讯云上线...……更多
2024-09-05 17:29:00腾讯,新一代,模型,定价,性能,腾讯

...这样的情境下,由于历史元素在电子中的介入程度较低,事实性的文化人物创作空间较小,任何对其进行的改编或创意性加工都可能放大对历史的偏离,从而导致“歪曲历史”的争议,造成文化误解。结构介入是指电子游戏在叙...……更多
2023-11-25 06:06:00之间,体验,文化,文化,电子游戏,电子
更多关于科技的资讯:
摘要:随着生成式人工智能技术在各行业的广泛应用,模型输出结果的不确定性问题日益受到关注。为提高模型在关键领域的可靠性,对输出不确定性进行量化分析成为重要方向
2025-12-04 06:17:00
12月3日从紫林醋业获悉,紫林醋业部分主导产品通过欧盟有机认证(EU Organic Certification),获准使用欧盟统一有机标识“欧洲叶标”(Euro-Leaf)
2025-12-04 07:31:00
中新经纬12月3日电 12月3日,豆包手机助手在官方微信号就“侵犯用户隐私”等问题进行回应,称不存在任何黑客行为。具体来看
2025-12-04 07:42:00

12月1日-3日,由中国互联网协会主办的2025“人工智能+”产业生态大会在北京举办。开幕式上,首届“AI领航杯”“人工智能+”应用与技能大赛总决赛举行了隆重的颁奖仪式
2025-12-04 07:47:00
近期,在“智绘星空胜算在天—太空数据中心建设工作推进会”上,北京拟在700—800公里晨昏轨道建设运营超GW(千兆瓦)级集中式大型数据中心系统
2025-12-03 09:42:00

承武当余韵,赴江城之约——小糖乐学以“传韵江城汇,小糖太极行”为引,再启太极文化与健康同行之旅。继武当山“问道太极”盛会圆满落幕
2025-12-03 13:40:00
杭州日报讯 产品还没走下生产线,就能在虚拟世界预知它未来十年会不会开裂、变形——这样的场景正在杭州成为现实。日前,工业科技企业浙江远算科技有限公司发布“AI质检数实融合验证平台”
2025-12-03 13:41:00

12月1日,曹操出行与越疆科技正式签署战略合作协议。双方将围绕Robotaxi(自动驾驶出租车)运营场景,共同探索机器人技术在车辆清洁
2025-12-03 13:41:00

从“智慧车间”到“工业大脑”,“江苏智造”通过数据驱动全流程变革,赋能产业链协同升级
近日,全国首批15家领航级智能工厂名单发布
2025-12-03 13:41:00

12月3日,杭州瞳行科技公司正式发布国内首款AI助盲眼镜。该眼镜基于通义千问Qwen-VL、OCR等系列模型打造,具有出行避障
2025-12-03 13:41:00
橙友“橙汁儿”向橙柿直通车反映:这几天收到了短信,是杭州市公共自行车公司发来的——“尊敬的用户,由于业务升级,您之前办理的绑卡租车功能即将在2025年12月底取消
2025-12-03 13:41:00
北京上班族李想称,健身私教课结束后,教练为索要好评,直接拿他手机代笔修改达3分钟。好评既影响消费者选择,也关联平台推流与服务者收益
2025-12-03 13:41:00
找“搭子” 聊技术 谈合作每日商报讯 一个多星期前,“魔搭社区”(杭州)开发者中心启用。这个中心是国内规模最大的模型开源社区“魔搭社区”的首个线下实体空间
2025-12-03 13:41:00