- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...含34B和6B两个版本。据HuggingFace英文开源社区平台和C-Eval中文评测的最新榜单,Yi-34B预训练模型取得了多项SOTA国际最佳性能指标认可,成为全球开源大模型“双料冠军”。零一万物创始人及CEO李开复博士表示:“零一万物坚定进军...……更多
2023-11-06 15:25:00阿里,万物,模型,评测,冠军,全球

...外,他还谈到人工智能计算机设计的三大平衡性原则、AI基准设计四大目标以及如何通过并行方法加速大规模预训练模型。为了完整体现郑纬民院士的分享及思考,在不改变原意的基础上,量子位对他的演讲内容进行了编辑整理...……更多
2023-01-11 05:00:00清华,院士,高性能,人工智能,模型,智能

...U、GAOKAO和AGI-Eval中,Baichuan3都展现了出色的能力,尤其在中文任务上更是超越了GPT-4。而在数学和代码专项评测如MATH、HumanEval和MBPP中同样表现出色,证明了Baichuan3在自然语言处理和代码生成领域的强大实力。不仅如此,其在对...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

...型五虎? 权威测评机构SuperCLUE此前发布了《中文大模型基准测评4月报告》,云从科技自主研发的从容大模型凭借其在多个领域的出色表现,赢得了行业内外的广泛关注,不仅成功晋升至SuperCLUE模型象限的【领导者象限】,更以...……更多
2024-08-08 17:45:00五虎,领航,模型,智能,科技,智能

...位于澳大利亚,再检索澳大利亚的多数党。查询仍然围绕事实性问题,但答案并没有明确地出现在任何某一个文本段落中,而是需要通过常识推理、结合多个事实来得出结论,所需的信息可能分散在多个段落中。
主要难点1. 适...……更多
2024-11-22 09:54:00银弹,数据,姿势,难度,解决方案,方案
...案件审理,有力推动了西北五省(区)税务行政处罚裁量基准统一,防范税收执法风险,做到案结事了。 ……更多
2024-02-28 05:02:00案件,西安,特派,农产,案件,税务

...能治理展开,安全组主要开展大模型安全、合规等研究及基准测试。今年6月,中国信通院依托该委员会发起“人工智能安全守护计划”,包括建立威胁信息共享机制、开展AIGC真实内容来源可信工作、建立AI保险机制等。
一、成...……更多
2024-07-25 09:26:00安全,信通,模型,评测,委员会,委员

...,一个用于评估多模态模型对长达一小时视频理解能力的基准数据集,包含多种任务。通过与现有模型对比,揭示当前模型在长视频理解上与人类水平的差距。2009年,李飞飞团队在CVPR上首次对外展示了图像识别数据集ImageNet,...……更多
2024-11-11 13:31:00团队,智能,空间,视频,模态,模型

...,但在研究工作中使用仍然有很多限制。对于科研来说,事实性至关重要,而大模型会产生幻觉,有时会自信地陈述没有任何现有来源或证据的信息。另外,科学需要极其注重细节,而大模型在面对具有挑战性的推理问题时可能...……更多
2024-09-13 13:33:00博士后,模型,科研,博士,检索,能力

【新智元导读】Meta全新发布的基准Multi-IF涵盖八种语言、4501个三轮对话任务,全面揭示了当前LLM在复杂多轮、多语言场景中的挑战。所有模型在多轮对话中表现显著衰减,表现最佳的o1-preview模型在三轮对话的准确率从87.7%下降...……更多
2024-11-26 09:51:00多语,大比,基准,指令,任务,语言

...望利用智能工具提升生产力,放大人类记者在新闻深度和事实核查等方面的独特优势,发展解释性报道和建设性新闻,进而巩固行业边界。(三)智能化信息分发:从个性化走向定制化人工智能应用于平台型媒体,以场景化、个...……更多
2024-06-13 10:23:00传播业,人工智能,人工,生成,风险,传播

...有更好的性能和更快的推理速度;
此外,Memory3 提高了事实性并减轻了幻觉,并能够快速适应专业任务。方法介绍记忆电路理论有助于确定哪些知识可以存储为显式记忆,以及哪种模型架构适合读取和写入显式记忆。研究者将...……更多
2024-07-11 09:33:00维南,领衔,院士,新作,模型,存储

...最快抵达成功的方式。xAI在首页展示了Grok-1和其他模型的基准测试对比连“中国AI教父”李开复也没躲过捷径的诱惑。这位互联网的多年从业者,创新工场的掌舵人,同样不愿意错过风口。他在2023年3月宣布组建自己的大语言模...……更多
2023-12-20 00:10:00王者,抄袭,模型,万物,公司,数据

...所分化。Michael Mignano:的确。近来每周都有新的模型发布基准测试结果,声称自己比其他所有模型都更出色,然后一周后又有另一家公司做出类似主张。这种现象几乎让人感觉,所有模型都在朝着同一个方向收敛,我们正经历这...……更多
2024-03-02 13:37:00硅谷,洞察,模型,顶级,需求,用户
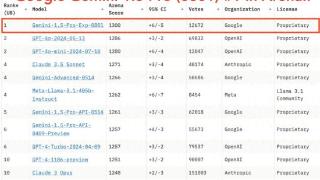
...比GPT-4o胜出54%,比Claude 3.5 Sonnet胜出59%。
在多语言能力基准测试中,它在中文、日语、德语、俄语均排名第一。但是,在Coding、Hard Prompt Arena中,它还是打不过Claude 3.5 Sonnet、GPT-4o、Llama 405B等对手。这一……更多
2024-08-05 09:36:00一口,模型,一口气,模型,竞技场,竞技

...些伪造的内容看似合理通顺地编织在一起、但其实不符合事实的现象,比如一些模型曾经煞有介事地讲述“林黛玉三打白骨精”的故事。作为人工智能发展中的一个缺陷,机器“幻觉”的潜在危害引发了研究人员和大众的担忧。...……更多
2023-12-30 19:00:00人工智能,美国,幻觉,人工,智能,美国

...强的应用价值。
《报告》显示,由于国内大模型厂商在中文数据语料上更加丰富,因此国内头部大模型在回答专业领域的基础知识问询时,对国内情况更加了解,回答的表现也比国外大模型更加出色。“在知识问答方面,大模...……更多
2023-10-10 17:56:00模型,业务,模型,报告,应用,能力

...,越来越多的用户对其早期版本的印象并不良好,仍存在事实性错误内容、信息过于陈旧等问题。尽管Gemini确实改进了Bard技术能力,但与ChatGPT-4相比,用户体验提升不大,因此其实际表现受到质疑。宾夕法尼亚大学沃顿商学院...……更多
2023-12-08 22:02:00剪辑,演示,模型,宣传,焦点,媒体

...排名第二。上海人工智能实验室在榜单发布同时表示:“中文场景下国内的模型更具优势,中文闭源大模型接近GPT-4 Turbo的水平。”OpenCompass 2.0全面量化模型在知识、语言、理解、推理和考试等五大能力维度的表现,客观中立地...……更多
2024-02-04 14:00:00司南,基座,前列,新一代,模型,评测
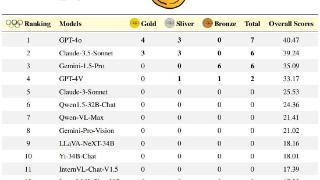
...理、数学推理、编程任务及视觉推理等任务上设立新行业基准而引发广泛讨论:Claude-3.5-Sonnet 已经取代OpenAI的GPT4o成为世界上”最聪明的AI“(Most Intelligent AI)了吗?回答这个问题的挑战在于我们首先需要一个足够挑战的智力测...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...司的官方演示却上演了类似谷歌Bard出糗的一幕,犯下了事实性错误。从技术角度看,“AI幻觉”(即AI编造语句通顺但事实逻辑错误的答案)仍是业界的一大难题。SearchGPT的发布彰显出OpenAI向搜索引擎扩张的野心,不过伟大的愿...……更多
2024-07-31 09:59:00演示,搜索,成本,搜索,错误,用户

...革。其下一代模型在技术上可能解决目前ChatGPT中存在的事实性以及推理能力的缺陷,实现更精细的语义理解、多模态(文本、图像、语音、视频等)输入和输出,具备更强的个性化能力。”“人工智能的发展会更多瞄向通用人...……更多
2024-06-05 18:36:00清华,模型,教授,性能,方法,模型
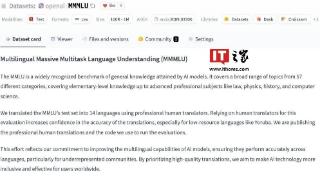
...其他语言。MMMLU数据集核心涵盖范围广MMMLU数据集是同类基准中最广泛的基准之一,涵盖了从高中问题到高级专业和学术知识的多种任务。研究人员和开发人员在利用MMMLU数据集过程中,可以调用不同难度的问题,测试大预言模型...……更多
2024-09-24 22:07:00多语,大规,大规模,任务,语言,语言

...是一个多维度上细致评测模型和人类意图对齐水平的评测基准,。最新版本的山海大模型在AlignBench上得分为6.55分,达到了GPT4水平的86%,处于国内领先水平。
医疗增强大模型能力不断增强,遥遥领先行业水平2023年6月,山海大...……更多
2024-02-04 11:00:00山海,征程,模型,山海,应用,技术

...投喂”的训练语料。在B端,企业通常拥有大量、私有的事实性知识,很多知识还是企业核心资产。通用大模型无法对上述知识数据“抓取”分析,就会导致事实性偏差、胡说八道急剧上升。具体到采购评标场景,不同采购人、...……更多
2024-09-29 11:45:00证据,模型,决策,驱动,采购,专家

...AI应用场景的契合度。这一点,也是全球唯一的AI/ML存储基准测试——MLPerf所关注的本质。MLPerf存储基准测试面向AI/ML用户的痛点,即存储和计算的平衡及两者的有效利用。然而测试中存储架构的多样与存算节点的非标准化,导致...……更多
2024-11-08 09:46:00浪潮信息,痛点,浪潮,百业,落地,存储

...
支持多种开、闭源对齐评估:支持了 30 多个多模态评测基准,包括如 MMBench、VideoMME 等多模态理解评测,以及如 FID、HPSv2 等多模态生成评测训练框架北大对齐小组设计了高度模块化、扩展性以及简单易用的对齐训练框架,支持...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据
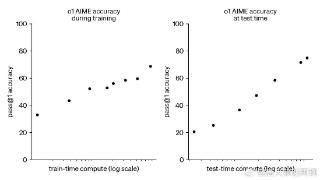
...列美国前500名学生之列,并且在物理、生物和化学问题的基准测试(GPQA)中超过了人类博士水平的准确度。OpenAI团队上下对o1模型充满了信心,OpenAI的CEO 山姆·奥特曼在社交媒体上表示:“需要耐心等待的时刻结束了!”、“这...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力

...智能算力基础设施产品的研发,2021年在业界率先推出了中文AI巨量模型“源1.0”,参数规模达2457亿,落地南京智算中心。此次发布的“源2.0”较前一版本实现了能力的全面提升。 ……更多
2023-11-28 07:46:00浪潮信息,浪潮,模型,参数,基础,信息

...3D、视频等更多模态,今年8月在SuperCLUE-V多模态理解评测基准总榜中排名第一。文生图方面,今年5月,腾讯混元全面开源业界首个中文原生DiT架构文生图大模型,评测结果国内领先。还有今天宣布开源的文/图生3D模型,单张图30...……更多
2024-11-06 09:41:00模型,腾讯,全家,生成,同时,语言
更多关于科技的资讯:

第十四届中国创新创业大赛——首届具身智能专业赛成果在厦发布。厦门网讯(文/厦门日报记者 吴晓菁 通讯员 高菲 康潇潇 图/厦门日报记者 卢剑豪)昨日的厦门国际会议中心酒店
2025-09-26 08:38:00
具身智能孵化加速器在厦正式揭牌第十四届中国创新创业大赛首届具身智能专业赛昨日发布成果东南网9月26日讯(海峡导报记者 黄奕琳)昨日
2025-09-26 10:17:00

日前,2025年农业机械检测实验室间比对活动在山东潍坊举行。该活动由中国农业机械化协会主办、农机鉴定检测分会承办、潍柴雷沃智慧农业协助开展
2025-09-26 07:05:00

560余家企业携4.8万余个岗位来东大揽才“AI+”岗位热度不减,实战经验是核心指标□南京日报/紫金山新闻记者何洁 实习生黄佳琪杨久久9月25日
2025-09-26 07:41:00
9月24日,“青春华章・向西而歌”网络大思政课活动上,西安交通大学微电子学院集成电路工程专业博士研究生魏上杰介绍,集成电路是“国之重器”的“心脏”
2025-09-25 09:44:00

企查查APP显示,近日,杜建英持股的杭州芸台文化创意有限公司被吊销,原因是公司成立后无正当理由超过6个月未开业,或者开业后自行停业连续6个月以上
2025-09-25 11:20:00

9月25日,雷军发文:这5年,小米一路摸爬滚打、跌宕起伏,依然启动了造车、芯片和高端化……没什么好犹豫的,五十来岁,正是闯的年纪
2025-09-25 11:20:00

赤水河畔,国内首台高温复合型仿生压曲机稳定运转,物联网实时优化发酵参数……这场酿酒的“数字革命”,也是贵州习酒公司以全链数智革新推动产业跃迁的生动缩影
2025-09-25 11:57:00

在人工智能技术日臻成熟的2025年,AI已是深度融入职场生态的“数字同事”,在AI辅助下的2025年职场迎来了哪些变化
2025-09-25 13:30:00
国庆前夕,房山区物美超市“胖改店”、居然之家房山店、瑞莱广场分别于9月26日、27日、28日开业,进一步丰富了房山区消费场景
2025-09-25 13:38:00

企查查APP显示,近日,负责OPPO项目的杭州逗酷软件科技有限公司发生工商变更,新增山子高科旗下浙江山子超影科技有限公司为股东
2025-09-25 16:25:00