- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
...个只有8%。研究人员根据答案是否正确以及答案所包含的逻辑推理是否有效,对大语言模型的答案进行了分类。实验的第一个结果是,在每个测试重复十次的情况下,答案是不一致的。例如,在同一个测试中,有的模型十次中答...……更多
2024-06-12 18:15:00逻辑推理,推理,逻辑,模型,语言,模型

...,尽管这些模型在处理自然语言方面表现卓越,但在复杂逻辑推理任务中,人类和语言模型都会受到语义内容合理性和可信度的影响,表现出类似的错误倾向。研究背景人类在推理过程中存在两种系统:“直觉系统”和“理性系...……更多
2024-08-19 13:49:00局限性,推理,人类,任务,研究,模型

...看看DoT长啥样。大模型复杂推理新框架
如前所述,DoT将逻辑推理过程建模为在单个LLM内构建有向无环图(DAG)。其框架内部管理三个关键角色:提议者:生成命题或推理步骤,添加新节点。
批评者:评估命题,识别错误、不...……更多
2024-09-24 13:36:00维图,院士,逻辑,模型,一致,理论

...读理解和问答等任务中取得了极高的性能,但这些模型在逻辑推理方面的性能仍然十分滞后。去年5月「思维链」(ChainofThought,CoT)横空出世,有研究人员发现,只需要在prompt中加入「Let'sthinkstepbystep」就能让GPT-3的推理性能大幅...……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标
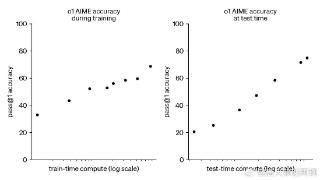
...二、社会评测与同行水平社会评测普遍认可o1 系列模型的逻辑推理能力优于 GPT-4o,但也有很多人提出了不同看法。差评XPIN邀请了理综三科的博士测评,物理评价较高,而生物、化学评价较低,综合认为o1在认知上达到硕士水平...……更多
2024-09-18 15:01:00逻辑推理,重磅,推理,逻辑,模型,能力
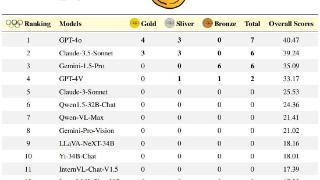
...竞赛不仅是对人类(碳基智能)思维敏捷性、知识掌握和逻辑推理的极限挑战,更是AI(“硅基智能”)锻炼的绝佳练兵场,是衡量AI与“超级智能”距离的重要标尺。OlympicArena——一个真正意义上的AI奥运竞技场。在这里,AI不...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

...概念,提高了大语言模型(LLM,large language models)在复杂推理任务上的性能,例如算术推理、常识推理和符号推理等。图 | 金明宇(来源:金明宇)CoT 的原理是通过提供推理过程的示例,来教会模型处理推理,详细说明导致最...……更多
2024-03-15 10:41:00罗格,罗格斯,推理,模型,团队,概念

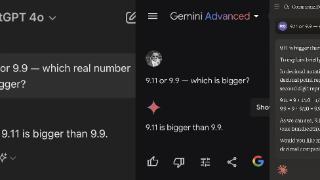
...地,也一定要对时间、数字和逻辑敏感,无论让它做多跳推理,还是逻辑规则数字计算,而这些恰好是大语言模型所不擅长的,包括前一段时间热议的 9.9 和 9.12 比大小的例子。基于此,我们认为在垂直领域落地的时候,大语言...……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型

...地依赖于训练数据中的模式进行预测。当需要进行真正的逻辑推理时,这些模型往往无法产生合理的结果,这一发现对人工智能的发展提供了重要的参考。虽然LLM在许多领域表现优异,但其推理能力仍有待改进。【本文结束】如...……更多
2024-10-13 14:15:00逻辑推理,新论,推理,缺陷,逻辑,模型

...度30个二级维度。报告称SenseChat-Vision 5.5在基础能力-数理逻辑推理任务如图表推理、场景推理方面具备领先优势。榜单显示,在数理逻辑分析能力中,SenseChat-Vision 5.5超越国内外所有参评模型包括GPT-4o的最新版本,位列第一。Super...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力

...一代“天工2.0”MoE大模型,“天工3.0”在模型语义理解、逻辑推理、以及通用性、泛化性、不确定性知识、学习能力等领域拥有惊人的性能提升,其模型技术知识能力提升超过20%,数学/推理/代码/文创能力提升超过30%。同时,“...……更多
2024-04-01 19:56:00万维,昆仑,模型,将于,同步,参数
...训练的深度推理大模型,升级后的星火X1在数学、代码、逻辑推理、文本生成、语言理解、知识问答等通用任务上效果显著提升,在模型参数比业界同类模型小一个数量级的情况下,整体效果对标OpenAI o1和DeepSeek R1,再次证明了...……更多
2025-04-22 16:50:00讯飞,星火,行业应用,司法,升级,医疗

...语言处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan3还突破“迭代式强化学习”...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

...始在一些权威评测中取得领先。今天,国内首款具备中文逻辑推理能力的 o1 模型来了,它便是由昆仑万维推出的「天工大模型 4.0」 o1 版(英文名:Skywork o1)。这也是近一个月来,该公司在大模型及相关应用上的第三次大动作...……更多
2024-11-28 10:00:00模型,逻辑推理,中文,推理,逻辑,国产
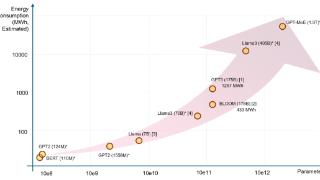
大模型预训练“缩放定律”定律失效?模型推理成“解药”,英伟达一家独大格局要变天?“缩放定律”指导下,AI大模型预训练目前遭遇瓶颈。据路透12日报道,硅谷主要AI实验室的新模型训练计划目前普遍进展不顺,新模型...……更多
2024-11-13 14:09:00英伟,争论,逻辑,意味,根本,策略

...还擅长超长文处理。通过大规模强化学习,并结合数学、逻辑推理、科学和代码等理科难题的专项优化,混元T1正式版进一步提升了推理能力。在体现推理模型基础能力的常见benchmark上,如大语言模型评估增强数据集MMLU-PRO中,...……更多
2025-03-22 00:29:00腾讯,深度,模型,推理,腾讯,模型

...规划和遵循非言语指令,参与多种形式的推理,包括形式逻辑推理、关于世界的因果推理和科学推理(见图 1b)。研究表明,尽管失去了语言能力,一些患有严重失语症的人仍然能够进行所有测试形式的思考和推理,他们在各种...……更多
2024-06-25 09:45:00推理,模型,思维,语言,社区,语言
...解释:“过去,ChatGPT等大模型像文科生,不擅长理科和逻辑推理。而对人类智慧来说,最底层的智慧是逻辑,逻辑之上是数学,再上面是物理、化学等科学。”去年9月,OpenAI发布的o1推理大模型改变了“文科生”形象,它擅长...……更多
2025-01-29 21:29:00上海,下岗,模型,智能,开发,企业

...M) 是如何解数学题的?是通过模板记忆,还是真的学会了推理思维?模型的心算过程是怎样的?能学会怎样的推理技能?与人类相同,还是超越了人类?只学一种类型的数学题,是会对通用智能的发展产生帮助?LLM 为什么会犯...……更多
2024-08-06 09:27:00推理,模型,内心,人类,世界,模型
...AI)系统在编码、战略规划和机器人科学三个领域执行复杂推理任务。聊天生成预训练转换器(ChatGPT)和“克劳德3-奥普斯”(Claude 3 Opus)等大语言模型(LLM),根据人类输入“提示词”处理和生成文本。研究人员说,过去18个月,这些技...……更多
2024-06-12 18:15:00推理,架构,混合,人类,能力,语言
...模型的短板,此前行业也多次讨论过大模型的数学和复杂推理能力较差,即便是目前最好的大模型GPT-4也仍然有很大进步空间。最近的一次,第一财经曾在6月报道过,根据司南评测体系OpenCompass的高考全卷测试,包括GPT-4在内,7...……更多
2024-07-17 11:56:00实测,模型,模型,数学,小数,问题

...23 年 2 月。当时,已经有一些研究团队开始使用大模型做逻辑推理和数学推理。赵子龙和合作者也认为这个方向很有前景。他表示让自己印象最深的例子就是 OpenAI 网站上的一道数学推理的题: Simplify tan100 + 4sin100。根据 OpenAI 自...……更多
2024-03-13 10:26:00数学,数学题,科学家,模型,辅导,课程
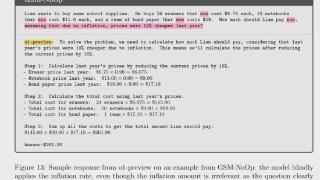
...降。我们假设这种下降是因为当前的 LLM 无法进行真正的逻辑推理;相反,它们试图复制在训练数据中观察到的推理步骤。」这一结论得到了 Keras 之父 François Chollet 和美国心理学家、认知科学家 Gary Marcus 的转发,他们一直对 AI ...……更多
2024-10-14 09:55:00数学题,推理,废话,苹果,数学,小学

...力一直是大模型的痛点,理科领域需要高度的抽象思维和逻辑推理能力,并且要求非常精准的答案,作为计算机科学和信息技术领域的重要工具,代码能力被视作衡量大模型智慧的关键维度。事实上,在过去一年国产大模型如火...……更多
2024-04-12 15:11:00商汤,办公,补强,金山,办公软件,理科

...读、科研的解决方案,其通用能力覆盖了专业考试、有限推理、翻译、解决数学问题,甚至还能写代码。已有的研究考察了大模型在科研领域的表现,但基准数据集大多属于「回顾性质」的,比如MMLU、PubMedQA和MedMCQA,主要以问...……更多
2024-12-09 09:50:00暴虐,准确率,模型,高达,完了,科研

...一定启示。日前,相关论文以《大型语言模型评价中的元推理革命》(MR-GSM8K: A Meta-Reasoning Revolution in Large Language Model Evaluation)为题发在 arXiv,曾忠燊是第一作者,香港中文大学教授贾佳亚担任通讯作者 [1]。图……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...编程、数字游戏等任务。这就是上海AI实验室版o1——强推理模型书生InternThinker,刚刚正式开放试用!新模型不仅在长思维能力方面有了很大提升,而且还能在推理过程中进行自我反思和纠正。先来一起看两个例子感受一下:比...……更多
2024-11-29 09:27:00数学题,上海,实验室,实验,数学,模型

【新智元导读】TS-Reasoner是一个创新的多步推理框架,结合了大型语言模型的上下文学习和推理能力,通过程序化多步推理、模块化设计、自定义模块生成和多领域数据集评估,有效提高了复杂时间序列任务的推理能力和准确性...……更多
2024-10-29 09:55:00推理,时间序列,序列,框架,难题,突破

...后向问题中生成后向推理。在涵盖常识推理、数学推理和逻辑推理的 12 个数据集上进行的实验表明,这一方法比学生模型的零样本性能平均提高了 13.53%,比 SOTA 知识提炼基线提高了 6.84%。此外,这一方法还展示了样本效率——...……更多
2024-12-10 09:53:00模型,语言基础,清华,定律,密度,团队

...“秋季发布”(9月至11月)要更早。上述报道称,专注于推理能力的人工智能“草莓”发布前后还有一些亟待解决的问题,但看似“仓促上马”似乎说明OpenAI感受到了大语言模型驱动产品领域的激烈竞争压力,希望通过近几个月...……更多
2024-09-11 09:55:00人工智能,推理,草莓,人工,模型,突破
更多关于科技的资讯:
厦门网讯(厦门日报记者 房舒)“你是温峥嵘,那我是谁?”近日,演员温峥嵘怒斥AI(人工智能)仿冒者的言论冲上热搜,揭开了AI技术被滥用的冰山一角
2025-11-23 08:11:00

鲁网11月23日讯(记者 张佳伟 实习生 寇晓菊)1天内完成立项、2天完成图纸审查、1个月实现场地平整、1年建成开园投产——广日电梯济南数字化产业园以“广日速度”刷新行业纪录
2025-11-23 15:19:00

大皖新闻讯 11月22日,第十届安徽省全屋智能设计集成职业技能竞赛总决赛在合肥落幕。本届竞赛由安徽省商务厅、安徽省总工会
2025-11-23 17:06:00
日前,山东摩享乐实业有限公司以17万台共享设备覆盖全国、10亿元级的市场投入,成为共享服务领域的“中华品牌”和标杆典范
2025-11-23 10:34:00
鲁网11月21日讯为回馈客户,赋能业务高质量发展,近日,河东农商银行桃源支行联合辖内某药业集团举办“金冬时节·健康相伴”客户养生见面会
2025-11-22 09:34:00

11月22日消息,蚂蚁灵光上线4天下载量突破100万,冲上App Store中国区免费榜第六。灵光首个百万下载速度超过ChatGPT
2025-11-22 14:13:00

知识带货热度不减,越来越多作家走进直播间推荐新书、好书。11月20日,知名历史作家梅毅(网名“赫连勃勃大王”)携新作《天命无常
2025-11-22 15:35:00

北京齐绘未来教育科技有限公司近日正式推出“快上岸”微信小程序,以多项具备自主知识产权的AI系统为核心,为大学生提供精准
2025-11-22 15:36:00

“在过去,去一次现场要带一大堆终端,以应对现场不同设备的接入。现在,只需一部手机和一箱基础工具就行。”来自广州南沙示范区运维工作人员的分享
2025-11-22 15:37:00
河北新闻网讯(李力芳)2025年7月份以来,河北建工省安装六分公司浙江八亿时空项目创新引入平台吊装系统、蜘蛛吊、电动遥控坦克等专业技术装备
2025-11-22 18:08:00
11月21日从太钢获悉,太钢近期硅钢产品订单在欧洲高端市场实现成功落地。此次出口的硅钢产品首次实现大卷重(15-17吨)和高牌号超宽规格(1250mm)供货
2025-11-22 18:20:00

荆楚网(湖北日报网)讯(记者唐天琪 通讯员王蕾、蓝静)11月20日,以“储能大时代,长时新蓝海”为主题的中国新型储能产业创新联盟2025年度大会在武汉召开
2025-11-22 19:06:00

2025年11月22日,百胜中国旗下必胜客在海南三亚举行中国第4000家门店的开业庆典。这一里程碑意味着必胜客在中国的布局进入新阶段
2025-11-22 22:32:00
从乡村直播间的农特产品,到城市商场的促销热潮,再到物流行业的高效运转……记者从太原市税务局获悉,随着“双11”将下半年消费市场带入旺季
2025-11-21 08:12:00