- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
...20日消息,上海人工智能实验室19日公布了首个AI高考全卷评测结果。据介绍,2024年全国高考甫一结束,该实验室旗下司南评测体系OpenCompass选取6个开源模型及GPT-4o进行高考“语数外”全卷能力测试。评测采用全国新课标I卷,参...……更多
2024-06-20 10:19:00评测结果,人工智能,上海,人工,实验室,评测
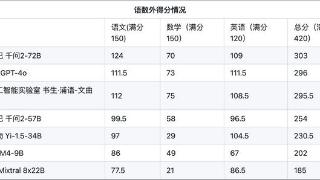
...能力测试。6月19日, OpenCompass发布了首个大模型高考全卷评测结果。语数外三科加起来的满分为420分,此次高考测试结果显示,阿里通义千问2-72B排名第一,为303分,OpenAI的GPT-4o排名第二,得分296分,上海人工智能实验室的书生...……更多
2024-06-24 09:22:00评测结果,最高分,评测,数学,高考,结果

6月19日,上海人工智能实验室发布首个AI高考全卷评测结果,月初开源的阿里通义千问大模型Qwen2-72B排名第一,在语数外三科420分的满分中获得303分,OpenAI的GPT-4o和上海人工智能实验室的书生·浦语2.0文曲星(InternLM2-20B-WQX)排...……更多
2024-06-20 11:10:00评测结果,全都,评测,数学,高考,结果

...方公众号,在12月22日的全国信息技术标准化技术委员会人工智能分委会全体会议期间,国内首个官方“大模型标准符合性评测”结果公布,腾讯混元大模型、阿里通义千问等大模型成为首批通过评测的四款国产大模型的其中之...……更多
2023-12-23 15:09:00符合性,模型,评测,标准,官方,模型

...140余个开源和商业闭源的语言及多模态大模型全方位能力评测结果。本次智源评测,分别从主观、客观两个维度考察了语言模型的简单理解、知识运用、推理能力、数学能力、代码能力、任务解决、安全与价值观七大能力;针对...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测
...技术生态、产业生态和开放性等多个维度进行评估,确保评测结果客观真实。此次评测结果将形成针对特定应用场景的综合报告和产品推荐目录,为政府、企业和研究机构建设智算中心提供芯片选型的重要参考和决策依据。在评...……更多
2023-10-23 15:02:00芯片,评测,国产,芯片,评测,人工智能
...考语、数、外全卷能力测试。据OpenCompass于6月19日发布的评测结果,大模型的语文、英语考试水平还不错,但数学都不及格,最高分只有75分(满分150分)。参加OpenCompass此次高考测试的大模型,分别是来自阿里巴巴、零一万物、...……更多
2024-06-26 07:26:00考生,模型,高考,模型,评测,高考
...平台 OpenCompass 的多模态评测领域中取得重大进展。最新评测结果显示,云从科技的从容大模型在该体系中的平均得分为 65.5,这一成绩使得从容大模型跻身全球前三,超越了谷歌的 Gemini-1.5-Pro 和 GPT-4v,仅次于 GPT-4o(69.9)和 Clau...……更多
2024-06-29 09:36:00模态,从容,模型,能力,全球,模态

...或者联系报道。本文的主要作者来自上海交通大学和上海人工智能实验室智慧医疗联合团队,共同第一作者为上海交通大学博士生邱芃铖和吴超逸,共同通讯作者为上海交通大学人工智能学院王延峰教授和谢伟迪副教授,这是该...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...代替学生去高考,会怎么样?欸,还真的有人试了。上海人工智能实验室近日公布了司南评测体系OpenCompass选取开源大模型测试今年高考的全国新课标I卷“语数外”的结果,为了确保“闭卷”考试,大模型的开源时间早于高考,...……更多
2024-06-26 22:29:00试卷,成绩,高考,结果,全国,模型

...先行者。早在2017年,微医便携手浙江大学合作建设睿医人工智能研究中心,以推动医疗健康领域人工智能技术的研发应用。如今,微医控股已将睿医研究成果规模化应用于数字健共体等场景。截至目前,微医控股已有微医医疗...……更多
2025-03-04 10:34:00模型,冠军,竞争,医疗,模型,医疗
...台OpenCompass的多模态评测领域中也取得了重大进展。最新评测结果显示,从容大模型在该体系中的平均得分为65.5,这一成绩使其跻身全球前三,超越了谷歌的Gemini-1.5-Pro和GPT-4v,仅次于GPT-4o(69.9)和Claude3.5-Sonnet(67.9)。在国内...……更多
2024-08-09 15:00:00模型,梯队,中国,从容,科技,模型

...了多任务、多模态的通用视觉评测基准,可以提供权威的评测结果,推动基于统一标准的公平和准确评测,加快通用视觉模型的产业化应用步伐。通过开源社区的建设,OpenGVLab帮助开发者显著降低通用视觉模型的开发门槛,用更...……更多
2023-03-15 13:30:00商汤,模态,书生,模型,任务,社区

...特定需求的模型。目前 o1-preview 模型表现最为全面,但是评测结果展示了许多其他模型在特定垂直领域的强有力的表现(具体详见论文和榜单)。最后,欢迎广大研究者使用我们的评测集进行实验和研究。淘天集团算法技术 - 未...……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型

...数字取证、异常检测技术的关注,到最近3年又扩展到了人工智能、深度学习和隐私保护的相关的技术上。“随着人工智能的发展,我们已经很重视相关的安全问题,比如像人工智能算法可能会在对抗攻击的情况下被误导。”清...……更多
2023-11-09 23:33:00越来,越来越,智能,安全,技术,人工智能

...型自我学习和迭代能力还不足,计算效率还不高。不管是人工智能整体发展,还是大模型具体“升级”,业内人士适逢人工智能时代,看到的希望重重,遇到的挑战也重重。另外,在罗璇看来,人工智能的未来总体方向是通用的...……更多
2024-04-15 22:01:00文科生,文科,业内人士,模型,业内,人士

...型的步伐。 此外,在综合评测权威平台OpenCompass公布的评测结果显示,云从科技的从容大模型在该体系中的平均得分为65.5,这一成绩使得从容大模型跻身全球前三,超越了谷歌的Gemini-1.5-Pro和GPT-4v,仅次于GPT-4o(69.9)和Claude3.5-...……更多
2024-08-08 17:45:00五虎,领航,模型,智能,科技,智能

...目由北京大学对齐小组开发并进行长期维护,团队专注于人工智能系统的安全交互与价值对齐,指导老师为北京大学人工智能研究院杨耀东助理教授。核心成员包括吉嘉铭、周嘉懿、邱天异、陈博远、王恺乐、洪东海、楼翰涛、...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

...及百川模型。本次测试提供了一个有趣的视角来观察当前人工智能大模型的发展状况。偏见测试结果得分以绝对值形式呈现,旨在凸显不同大语言模型在性别视角下处理问题的偏见程度,也揭示了它们在不同领域的优势和不足。...……更多
2024-01-04 13:54:00偏见,人工智能,情商,智商,人工,模型

本文转自:新华网作为人工智能领域最重要的突破性进展之一,大模型正日益成为推动全球科技进步和经济增长的强劲动力。11月23日,在由中关村科金与中国信息通信研究院人工智能研究中心、人工智能关键技术和应用评测工...……更多
2023-11-24 09:56:00中关,中关村,人工智能,人工,模型,新品

...的AI大模型能否完美“适配”保险行业?10月10日发布的《人工智能大模型保险行业应用评测报告》(以下简称《报告》)便揭晓了答案。根据《报告》,10个主流大模型在知识问答领域表现普遍较好,在智能核保、智能理赔、话...……更多
2023-10-10 17:56:00模型,业务,模型,报告,应用,能力

...社区发展提供最佳技术支持,降低大模型商业门槛,推动人工智能技术落地千行百业,为人工智能生态建设添砖加瓦,携手开源社区探索未知世界、创造美好未来。两大模型 领先行业昆仑万维「天工」Skywork-13B系列包括两大模型...……更多
2023-10-30 15:35:00万维,昆仑,商用,高质量,模型,领先

...情况,并启动了AI安全守护计划,发布了三大类别的安全评测结果。AIIA安全治理委员会成立于2023年12月底,经过半年运营,现有治理组、安全组两个工作组,近百家单位加入,主任单位由中国信通院牵头,副主任单位包括多家知...……更多
2024-07-25 09:26:00安全,信通,模型,评测,委员会,委员

...0+项评测指标、200+项评测场景、100多万专属评测数据集,评测结果客观性跻身国内外主流基准第一阵营。依托自研大模型评测智能体,支持评测数据自学习、用例自编排、执行自适应,同比评测周期缩短90%以上,已服务政府部委...……更多
2024-05-25 07:21:00潮起,模型,中国,中国移动,移动,模态

...大模型首批通过测试。测试结果称,上述四款模型符合《人工智能大规模预训练模型第2部分:评测指标与方法》语言大模型的相关技术要求,通用性、智能性等维度达到国家相关标准。该测试由工信部中国电子技术标准化研究...……更多
2023-12-26 14:16:00人工智能,国标,人工,模型,结果,智能

...回答,引发掌声不断。刘庆峰表示,认知大模型成为通用人工智能的曙光,科大讯飞有信心实现“智能涌现”。当前讯飞星火认知大模型已经在文本生成、知识问答、数学能力三大能力上已超ChatGPT。他进一步公布大模型年内三...……更多
2023-05-08 13:43:00讯飞,星火,模型,整体,讯飞,星火

...-上海频道人民网上海1月6日电(记者董志雯)近日,上海人工智能实验室成立国内首个医疗大模型应用检测验证中心,打通“训评用一体化”链路。记者了解到,上海市医疗大模型应用检测验证中心是国内首个面向医疗大模型应...……更多
2025-01-06 12:03:00上海,模型,验证,检测,医疗,应用

...一致时,就会推翻 “假设”,重新尝试新的假设。
人类评测结果人类在 VCR 任务下的水平如何呢?下图中展示了母语者或各语言的流利使用者在英 / 中两种语言的简单 / 困难设定下的准确度:如果考虑包含时间、地名、人名的...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务

...安全基准测试AI Safety Bench是中国信息通信研究院依托中国人工智能产业发展联盟(AIIA)安全治理委员会,联合17家单位发起的,秉持公平公正、产业应用和场景导向的原则,目标建立业内权威大模型安全中文基准测试体系。以提高...……更多
2024-04-10 20:16:00信通,基准,中国,模型,测试,报告

...玩笑说法,但实际上也是一种趋势。除此之外,他还谈到人工智能计算机设计的三大平衡性原则、AI基准设计四大目标以及如何通过并行方法加速大规模预训练模型。为了完整体现郑纬民院士的分享及思考,在不改变原意的基础...……更多
2023-01-11 05:00:00清华,院士,高性能,人工智能,模型,智能
更多关于科技的资讯:

《还珠格格》中的香妃有吸引蝴蝶的体质,影视剧中的解释是她天然有体香,蝴蝶被香味所吸引!不过现实可能并不是这样的,因为蝴蝶不一定会被花朵所吸引
2025-03-10 00:47:00


快科技3月10日消息,AMD RX 9070系列虽然不是旗舰,但成功狙击了RTX 5070系列,无论性能还是价格都丝毫不风
2025-03-10 01:17:00
本文转自:人民日报本报记者 王云杉 刘晓宇 沈靖然在武汉经开区,无人驾驶汽车平稳行驶在路上;在深圳北站,乘客可搭乘直升机飞往深圳各区……随着科技发展
2025-03-10 06:06:00
本文转自:人民日报王 博“可以买贵的,不能买贵了”“买的东西‘奇奇怪怪’,却又‘可可爱爱’”……有着自己消费逻辑的年轻人
2025-03-10 06:06:00

时间进入3月,一大波Ultra机型即将来临,但我却逆势用上了一款Pro机型,这就是vivo的X200 Pro。作为“大杯”机型
2025-03-10 06:47:00

快科技3月10日消息,在最新一期的小米汽车答网友问中,小米汽车表示,小米SU7 Ultra标配闭式双腔空气弹簧,可以实现底盘高度的多级
2025-03-10 07:17:00

快科技3月9日消息,据报道,中国电力建设集团有限公司牵头研发的国内首台可变径扩孔式竖井掘进机“逐梦号”在浙江永嘉抽水蓄能电站成功完成了358米深的排风竖井掘进任务
2025-03-10 07:17:00

快科技3月10日消息,今早,小岛秀夫新作《死亡搁浅2》在美国西南偏南电影节公布全新预告片,同时宣布PS5版《死亡搁浅2》将于3月17日10:00开启预售
2025-03-10 07:17:00

快科技3月10日消息,日前,一段两名男子站在桌上,向火锅内撒尿的视频引发关注。对此,海底捞官方回应称,已向多地公安报警
2025-03-10 07:17:00

快科技3月10日消息,不少国人对于“吉利数字”“幸运数字”的概念并不反感甚至会主动追逐,这就催生出手机靓号、“豹子车牌”等现象
2025-03-10 07:17:00

3月8日下午,太原日报小红书“年味儿——我的记录”有奖征集活动颁奖会在太原日报社举行。太原日报小红书账号自去年12月17日上线以来
2025-03-10 07:21:00
“宁工品推·十链百场千企”活动走进科远智慧“量身定制”推产品,供需对接拓市场南报网讯(记者徐宁)“这是我们基于国产化CPU
2025-03-10 07:31:00
