- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...研究人员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。训练一个扩散模型要多少钱?之前最便宜的方法(Wuerstchen)用了28400美元,而像Stable Diffusion这样的模型还要再贵一个数量级。大模型时代...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练

...统团队。他们探讨了深度学习中训练集大小、计算规模和模型精度之间的关系,并且通过大规模实证研究揭示了深度学习泛化误差和模型大小的缩放规律,还在图像和音频上进行了测试。只不过他们使用的是 LSTM,而不是Transforme...……更多
2024-11-28 09:57:00模型,训练,数据,大小,研究,误差
苹果最新杀入开源大模型战场,而且比其他公司更开放。推出7B模型,不仅效果与Llama 3 8B相当,而且一次性开源了全部训练过程和资源。要知道,不久前Nature杂志编辑Elizabeth Gibney还撰文批评:许多声称开源的AI模型,实际上在...……更多
2024-07-23 09:33:00苹果,一口,模型,一口气,训练,过程

...浪潮电子信息产业股份有限公司在京发布“源2.0”基础大模型,并宣布全面开源。“源2.0”包括102B(1026亿)、51B(518亿)、2B(21亿)三种参数规模的模型,在编程、推理、逻辑等方面展示出了先进的能力。基础大模型的关键能...……更多
2023-11-28 07:46:00浪潮信息,浪潮,模型,参数,基础,信息

...进行编码的样式参数。研究人员在六维N-body相空间上训练模型,将粒子速度预测为模型位移输出的时间导数,显著提高了训练效率和模型准确性。最终,模拟器在测试数据(训练期间未见过的各种宇宙学和红移)上实现了良好的...……更多
2024-09-20 13:34:00暗物质,仿真,宇宙,突破,结构,粒子

10月30日,昆仑万维宣布开源百亿级大语言模型「天工」Skywork-13B系列,并配套开源了600GB、150B Tokens的超大高质量开源中文数据集。昆仑万维「天工」Skywork-13B系列目前包括130亿参数的两大模型:Skywork-13B-Base模型、Skywork-13B-Mat……更多
2023-10-30 15:35:00万维,昆仑,商用,高质量,模型,领先

...斯·哈萨比斯在谷歌官网联名发文,官宣了最新多模态大模型Gemini 1.0(双子星)版本正式上线。这个上线时间早于外界猜测的明年1月,保密程度很高,仅有少数媒体提前猜出。Gemini 1.0是谷歌筹备了一年之久的GPT4真正竞品,也是...……更多
2023-12-07 10:31:00强悍,模型,模态,模型,训练,能力

...为刘家铭博士,研究方向为面向开放世界的多模态具身大模型与持续性学习技术。本工作第二作者为刘梦真,研究方向为视觉基础模型与机器人操纵。指导老师为仉尚航,北京大学计算机学院研究员、博士生导师、博雅青年学者...……更多
2024-06-21 09:52:00机器,模态,人多,机器人,推理,北大

12月22日,国内首个官方“大模型标准符合性评测”结果公布,百度文心一言、腾讯混元大模型、360智脑、阿里云通义千问四款国产大模型首批通过测试。测试结果称,上述四款模型符合《人工智能大规模预训练模型第2部分:评...……更多
2023-12-26 14:16:00人工智能,国标,人工,模型,结果,智能

视频生成模型虽然可以生成一些看似符合常识的视频,但被证实目前还无法理解物理规律!自从 Sora 横空出世,业界便掀起了一场「视频生成模型到底懂不懂物理规律」的争论。图灵奖得主 Yann LeCun 明确表示,基于文本提示生...……更多
2024-11-09 09:59:00模型,豆包,系统性,字节,规律,团队

...会已拉开帷幕,微软在本次活动中发布了旗下最小的语言模型Phi-2,共有27亿参数,相比较此前版本有明显提升。注:微软于今年6月发布Phi-1,只有13亿代码,适用于QA问答、聊天格式和代码等等场景。该模型完全基于高质量数据...……更多
2023-11-17 14:00:00微软,旗下,模型,语言,模型,微软
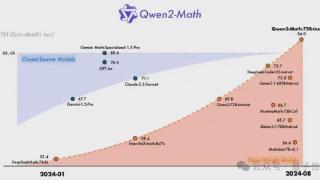
最强数学大模型,现在易主!阿里千问大模型团队发布的Qwen2-Math,不仅超越了Llama 3.1-405B,也战胜了GPT-4o、Claude 3.5等一系列闭源模型。而且还会解决竞赛级试题,在GPT-4只能做对一道的AIME 24中,Qwen2-Math答对的题目数量达到了两...……更多
2024-08-10 09:45:00模型,阿里,成绩,数学,模型,数据
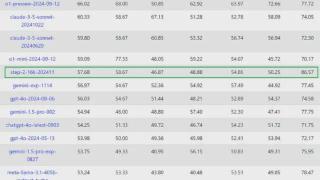
What???一直低调行事的国内初创公司,旗下模型悄悄地跃升成国内第一、世界第五(仅排在o1系列和Claude 3.5之后)!而且是前十名中的唯一一家国产公司。(该榜上国产第二名是阿里开源的qwen2.5-72b-instruct,总榜第13)。而且...……更多
2024-11-22 09:54:00指令,模型,国产,全球,模型,模态

...日(11 月 26 日)发布博文,宣布推出 SmolVLM AI 视觉语言模型(VLM),仅有 20 亿参数,用于设备端推理,凭借其极低的内存占用在同类模型中脱颖而出。官方表示 SmolVLM AI 模型的优点在于体积小、速度快、内存高效,并且完全开...……更多
2024-11-28 09:47:00推理,模型,参数,模型,吞吐量,吞吐

长时间交通状况预测,可以用大模型实现了。香港大学联合华南理工大学和百度,推出了长时间城市交通预测模型——OpenCity。而且泛化能力极强,可有效应用于广泛的交通预测场景。为了解决传统交通预测模型泛化性及长期预...……更多
2024-09-02 13:34:00路况,样本,模型,交通,交通,模型

...赵晨阳,卡内基梅隆大学硕士生贾雪莹。虽然大规模语言模型(LLM)在许多自然语言处理任务中表现优异,但在具体任务中的效果却不尽如人意。为了提升模型在特定自然语言任务上的表现,现有的方法主要依赖于高质量的人工...……更多
2024-08-02 09:40:00清华,性能,任务,数据,学习,生成

...算集群规模,才能一路突破围追堵截,进一步促进国产大模型产业生态繁荣。作为中立、安全的云计算服务厂商,优刻得持续发力人工智能智算领域,与国内主流AI芯片厂商深度合作,共同搭建的「国产千卡智算集群」现已上线...……更多
2024-06-27 19:01:00集群,落地,模型,国产,训练,支持

Mamba 架构的大模型又一次向 Transformer 发起了挑战。Mamba 架构模型这次终于要「站」起来了?自 2023 年 12 月首次推出以来,Mamba 便成为了 Transformer 的强有力竞争对手。此后,采用 Mamba 架构的模型不断出现,比如 Mistral 发布的首...……更多
2024-08-14 09:39:00力大,架构,模型,模型,架构,训练

...越人类专家。在性能跃升之外,更重要的是,它揭示了大模型进化范式的转变:通过更多的强化学习(训练时计算)和更多的推理(Test-Time 计算),模型可以获得更强大的性能。这又一次让我们想起 Richard Sutton 在《The Bitter Lesso...……更多
2024-10-21 09:55:00英伟,霸主,推理,模型,地位,时代

...为什么不使用MoE架构?后训练与RLHF流程是如何进行的?模型评估是如何进行的?我们什么时候可以见到Llama 4?Meta是否会发展agent?恰逢Llama 3.1刚刚发布,Meta科学家就现身播客节目Latent Space,秉持着开源分享的精神,对以上问题...……更多
2024-07-29 09:33:00科学家,训练,科学,模型,训练,基准
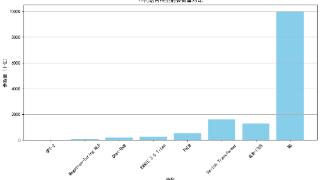
大模型的发展已经进入了万亿级参数时代。DeepMind 联合创始人穆斯塔法・苏莱曼(Mustafa Suleyman)预测, 仅在未来三年内,大模型规模以惊人的速度继续扩张,将增长 1000 倍。一方面,模型的参数量与其能够处理和学习的复杂性...……更多
2024-06-24 09:42:00新宠,模型,正在,模型,参数,训练

只要改一行代码,就能让大模型训练效率提升至1.47倍。拥有得州大学奥斯汀分校背景四名华人学者,提出了大模型训练优化器Cautious Optimizers。在提速的同时,Cautious能够保证训练效果不出现损失,而且语言和视觉模型都适用。...……更多
2024-11-28 09:58:00训练,模型,团队,速度,代码,华人

...et系列的原班人马推出了新一代架构:BitNet a4.8,为1 bit大模型启用了4位激活值,支持3 bit KV cache,效率再突破。量化到1 bit的LLM还能再突破?这次,他们对激活值下手了!近日,BitNet系列的原班人马推出了新一代架构:BitNet a4.8...……更多
2024-12-06 09:55:00架构,激活,新一代,模型,突破,激活

首个开源的ChatGPT低成本复现流程来了!预训练、奖励模型训练、强化学习训练,一次性打通。最小demo训练流程仅需1.62GB显存,随便一张消费级显卡都能满足了。单卡模型容量最多提升10.3倍。相比原生PyTorch,单机训练速度最高...……更多
2023-02-15 15:47:00流程,成本,模型,训练,内存,参数
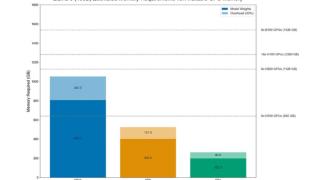
...顶配,405B版本拥有4050亿个参数,是迄今为止最大的开源模型之一。昨夜凌晨,META突发Llama 3.1-405B评测数据的泄漏事件,有网友预计可能还会同时发布一个Llama 3.1-70B版本,因为“(模型提前泄露)是META的老传统了,去年的Llama模...……更多
2024-07-23 17:11:00模型,时刻,模型,数据,开发,人员

...爆全球AI浪潮以来,AI圈子已经迅速走过了造出了通用大模型的第一道关卡,如今最关键的问题在于——如何让大模型高效地在实际应用场景中落地?百川智能的最新实践是:用大模型+增强技术,可以大大提升企业应用大模型的...……更多
2023-12-21 15:32:00百川,外挂,模型,成本,硬盘,智能

近年来,扩散模型(Diffusion Models)已成为生成模型领域的研究前沿,它们在图像生成、视频生成、分子设计、音频生成等众多领域展现出强大的能力。然而,生成符合特定条件(如标签、属性或能量分布)的样本,通常需要为...……更多
2024-12-06 09:52:00生成,训练,分类,生成,样本,指导

文 | 周鑫雨编辑 | 邓咏仪当大模型加速应用落地,运行成本就成为各厂商的现实考量。将模型做小,成为现实市场需求下的趋势。但模型的Scaling Law(规模定律)已指出,参数规模是决定模型性能的最关键因素。如何用更小的参...……更多
2024-02-03 16:03:00适配,推理,模型,主流,成本,智能

...段中,通常小规模算力就可以满足需求。此阶段主要是对模型的可行性、架构设计的合理性以及算法的有效性进行初步验证,此时模型规模相对较小,参数数量和复杂度都处于较低水平。例如,在构建一个简单的文本分类预演模...……更多
2025-04-24 18:00:00思路,阶段,交通,项目,模型,交通
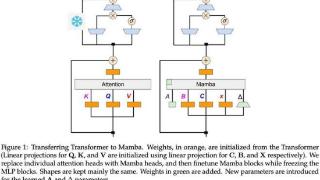
...功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。...……更多
2024-09-03 09:59:00线性,新作,混合,作者,模型,线性
更多关于科技的资讯:

吉林省音乐厅12月31日即将惊艳亮相,这是一座音质效果优秀的专业音乐殿堂,凭借过硬的声学品质,足以跻身国内外同等规模的顶级音乐厅行列
2025-12-14 10:39:00

在人口老龄化加速与“银发经济”蓬勃发展的时代背景下,湖南银行推出养老金融品牌“福享幸福+”,以“金融+健康+生活”为核心定位
2025-12-13 16:46:00

大皖新闻讯 日前,第四届创业安徽大赛决赛在合肥举办,来自国内外的21个创新创业项目获奖,分享270万元奖金。其中,10个优质项目还现场签署协议
2025-12-13 19:14:00
杭州日报讯 12月12日,第十届中国设计智造大奖(Design Intelligence Award,下文简称“DIA”)颁奖盛典在中国美术学院良渚校区举行
2025-12-14 07:04:00
在全球制造业加速迈向智能化与数字化的今天,构建高效、可靠且面向未来的自动化系统,已成为企业提升核心竞争力、应对市场不确定性的战略基石
2025-12-13 22:48:00

为精准把握潮玩产业蓬勃发展的时代脉搏,助力广州建设具有全球影响力的潮玩产业高地,12月11日,由广州市投资发展委员会办公室主办
2025-12-13 16:43:00
12日晚,第十届中国设计智造大奖(DIA)颁奖盛典在中国美术学院良渚校区举行。第十届中国设计智造大奖征集自2024年12月12日启动
2025-12-13 07:36:00

小程序“了不起的甲骨文”,展示甲骨文“其”的不同字形。(本组图/小程序截图)甲骨拓本甲骨文“门”字
甲骨文摹本甲骨文“马”字扫码看视频
厦门网讯 (厦门日报教育工作室首席专家 佘峥 通讯员 王志鹏)你只需往电脑上传一张甲骨图片
2025-12-12 08:28:00
厦门网讯(厦门日报记者 曾嫣艳 通讯员 曾焕滨)昨日,厦门临空经济片区场景创新平台推广暨供需对接与企业路演活动在翔安创新实验室举办
2025-12-12 08:28:00

在短剧行业从 “流量争夺” 转向 “品质与流程双竞争” 的关键阶段,如何在有限周期内平衡效率、成本与成片质量,成为所有制作机构必须破解的难题
2025-12-12 08:29:00

儿童戏剧,是投射在少年儿童心灵舞台上的第一束光。人物造型,作为这束光中最具象、最绚烂的色彩,不仅定义角色的灵魂,更深刻影响着儿童认知世界的方式与审美情感的塑造
2025-12-12 08:29:00

在近期举办的2025世界中文大会上,教育企业星禾星穗多维度参与,展现了其在“中文+专业/职业”领域的系统思考与实践成果
2025-12-12 08:30:00

元启创新的人形机器人正在打拳。(元启创新 供图)厦门网讯 (厦门日报记者 吴晓菁) “灵犀,灵犀,表演一段佛山醒狮。”昨日
2025-12-12 08:59:00

2025年12月9日下午,一场聚焦数字文化出海与青年文化交流的“共建数字丝绸之路”研讨会在上海举行。中国传媒大学经济与管理学院教授方英
2025-12-12 09:00:00
AI 眼镜似乎成了AI具身智能行业中最“靓”的仔,无论是苹果、谷歌这些大厂,还是国内的科技巨头,纷纷下场。本周二,谷歌在The Android Show活动上宣布
2025-12-12 09:10:00