- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...的能力和效用。”风向在转变,小模型正在成为 AI 界的新宠。尽管参数规模较小,却在成本、性能和实用性方面具备优势 —— 占内存小、反应速度快、可以本地化运行。不久前,微软研究院推出了新一代小型语言模型系列 Phi-3...……更多
2024-06-24 09:42:00新宠,模型,正在,模型,参数,训练

...巨头微软或正在研发参数达5000亿的全新AI(人工智能)大模型,将正面叫板谷歌和OpenAI。当地时间5月6日,据外媒报道,微软正在研发一款名为MAI-1的最新AI大模型,其规模远超出微软此前推出的一些开源模型,在性能上或能与谷...……更多
2024-05-07 14:33:00微软,模型,参数,竞争,微软,模型

...武静静编辑|邓咏仪放弃造车后的苹果,正在加速入局大模型战争。当地时间3月15日,苹果就披露了两个关键大模型动作。其中一个值得关注的是苹果的收购事件。彭博社报道称,苹果已经收购了一家加拿大AI初创公司DarwinAI。...……更多
2024-03-16 18:14:00模型,苹果,参数,焦点,分析,公司

...城实验室主任高文发表演讲,分享了鹏城实验室在打造大模型平台上的进展。他表示,大模型训练首先需要一个平台。“现在要想训练一个大模型,需要有几千块卡,甚至上万块卡。”他介绍到,鹏城实验室在2020年就搭建了这...……更多
2024-06-05 13:00:00高文,院士,实验室,模型,训练,实验

端侧大模型正在成为手机行业创新的新增量。文|《中国企业家》记者 赵东山编辑|李薇头图来源|视觉中国人均年薪100万,什么样的行业具备如此优渥的待遇?答案是AI大模型。这是vivo副总裁周围接受《中国企业家》等媒体...……更多
2023-12-06 11:40:00年薪,模型,厂商,手机,模型,手机

...球科技公司Yandex推出了YaFSDP,这是一种用于训练大型语言模型(LLM)的开源方法。据介绍,YaFSDP是目前在大型语言模型训练中增强图形处理器(GPU)通信并减少内存使用量的公开可用的最有效工具,与FSDP相比,根据架构和参数数量...……更多
2024-06-18 16:13:00处理器,图形,模型,高达,训练,语言

首个开源的ChatGPT低成本复现流程来了!预训练、奖励模型训练、强化学习训练,一次性打通。最小demo训练流程仅需1.62GB显存,随便一张消费级显卡都能满足了。单卡模型容量最多提升10.3倍。相比原生PyTorch,单机训练速度最高...……更多
2023-02-15 15:47:00流程,成本,模型,训练,内存,参数

出品 | 搜狐科技作者 | 梁昌均编辑 | 杨锦一口气开源8款模型,阿里通义又上新!4月29日一大早,阿里开源发布Qwen3,包括两款MoE(混合专家架构)模型,其中具备2350亿参数规模的Qwen3-235B-A22B,在对比测试中成为目前最强大的开...……更多
2025-04-29 16:17:00模型,阿里,话语权,中国,话语,全球

Transformer大模型尺寸变化,正在重走CNN的老路!看到大家都被LLaMA 3.1吸引了注意力,贾扬清发出如此感慨。拿大模型尺寸的发展,和CNN的发展作对比,就能发现一个明显的趋势和现象:在ImageNet时代,研究人员和技术从业者见证...……更多
2024-08-02 09:47:00特斯,马斯,马斯克,扬清,特斯拉,老路

迎着技术风口,2024年将是AI大模型应用的浪潮年。业界认为,大模型将对金融业产生长远的、深刻的影响。1月28日,针对大模型在各业务场景的应用成效、对大模型算力的开发和提升,多机构向北京商报记者透露了自研大模型...……更多
2024-01-29 21:36:00模型,之路,金融业,落地,观察,训练

2024年,全球主流企业加快推出MoE大模型,1-5月发布千亿以上大模型均采用MoE优化架构,且数量超过近三年总和。MoE大模型架构凭借平衡大模型训推成本和计算效率等优势,更适合处理大规模数据和复杂任务,已成谷歌、OpenAI、...……更多
2024-11-04 16:00:00研究方向,模型,现状,方向,趋势,研究

...为什么不使用MoE架构?后训练与RLHF流程是如何进行的?模型评估是如何进行的?我们什么时候可以见到Llama 4?Meta是否会发展agent?恰逢Llama 3.1刚刚发布,Meta科学家就现身播客节目Latent Space,秉持着开源分享的精神,对以上问题...……更多
2024-07-29 09:33:00科学家,训练,科学,模型,训练,基准

...文称,该公司目前正在训练一款全新的完全自动驾驶(FSD)模型,可能在下个月底准备好向公众发布。 马斯克表示:“新的FSD模型参数量扩大了约10倍,并对视频压缩损耗方面做出显著改进。如果测试顺利,预计下月底向用户推送...……更多
2025-08-06 21:35:00特斯,马斯,马斯克,特斯拉,模型,训练

为了保持公司在AI(人工智能)开源大模型领域的地位,社交巨头Meta推出了旗下最新开源模型。当地时间4月18日,Meta在官网上宣布公布了旗下最新大模型Llama 3。目前,Llama 3已经开放了80亿(8B)和700亿(70B)两个小参数版本,...……更多
2024-04-19 15:58:00分水,分水岭,模型,参数,社区,模型

...家坚持开源的社交巨头,又默默放出了最新一代的开源大模型Llama3。美当地时间4月18日,Meta在官网上发布了两款开源大模型,参数分别达到80亿和700亿,是目前同体量下性能最好的开源模型。马斯克对此评价称“还不错”。Meta...……更多
2024-04-20 11:00:00马斯,马斯克,李彦,模型,评价,模型
...略合作关系,华为云以及昇腾算力产品线同样能为公司大模型的研发提供算力支持,公司目前正在积极与华为对接,展开大模型产品与应用的软硬件解决方案的研发。公司大模型相关产品的研发从规划之初一直采用自主可控的路...……更多
2023-10-18 15:02:00佳都,华为,训练,主流,参数,科技

...上一代WSE-2的两倍,可用于训练业内一些最大的人工智能模型。在近日的Hot Chips 2024大会上,Cerebras Systems详细介绍了这款芯片在AI推理方面的性能。根据官方资料显示,WSE-3依然是采用了一整张12英寸晶圆来制作,基于台积电5nm制...……更多
2024-09-02 13:36:00晶圆,芯片,生成,模型,性能,参数

...开的彻彻底底。这不,Meta一连放出三篇技术文章,从大模型适配方法出发,介绍了:如何使用特定领域数据微调LLM,如何确定微调适配自己的用例,以及如何管理良好训练数据集的经验法则。接下来,直接进入正题。适配大模...……更多
2024-08-27 12:03:00小白,长文,千字,基础,指南,训练

...算力需求大爆发的转折之年,如今随着国内两批超20个大模型获得审批、种类多样的大模型相关应用显现,企业对私有化部署的需求也水涨船高。面向这一行业趋势,2023年世界互联网大会乌镇峰会上,国内云端RISC-V大芯片创企希...……更多
2023-11-15 15:41:00模型,一体机,推理,快车,芯片,一体

...算集群规模,才能一路突破围追堵截,进一步促进国产大模型产业生态繁荣。作为中立、安全的云计算服务厂商,优刻得持续发力人工智能智算领域,与国内主流AI芯片厂商深度合作,共同搭建的「国产千卡智算集群」现已上线...……更多
2024-06-27 19:01:00集群,落地,模型,国产,训练,支持

...态连续学习的最新进展连续学习(CL)旨在增强机器学习模型的能力,使其能够不断从新数据中学习,而无需进行所有旧数据的重新训练。连续学习的主要挑战是灾难性遗忘:当任务按顺序训练时,新的任务训练会严重干扰之前...……更多
2024-11-14 09:46:00模态,清华,中文,联合,学习,模态

...发展的道路上,科技巨头们曾经竞相开发规模庞大的语言模型,但如今出现了一种新趋势:小型语言模型(SLM)正逐渐崭露头角,挑战着过去“越大越好”的观念。视觉中国当地时间8月21日,微软和英伟达相继发布了最新的小型...……更多
2024-08-26 14:17:00模型,英伟,微软,模型,训练,性能

【新智元导读】小模型时代来了?OpenAI带着GPT-4o mini首次入局小模型战场,Mistral AI、HuggingFace本周接连发布了小模型。如今,苹果也发布了70亿参数小模型DCLM,性能碾压Mistral-7B。小模型的战场,打起来了!继GPT-4o mini、Mistral Ne……更多
2024-07-22 09:41:00血战,强势,模型,苹果,模型,数据

快科技6月14日消息,摩尔线程与全学科教育AI大模型“师者AI”联合宣布,双方已完成大模型训练测试。师者AI基于摩尔线程夸娥(KUAE)千卡智算集群,完成了其70亿参数大模型的高强度训练测试。整个训练过程用时一周,训练...……更多
2024-06-14 11:37:00摩尔,师者,集群,线程,模型,训练
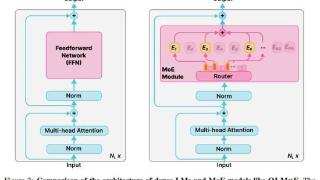
... checkpoint、训练日志和训练数据都已经开源。尽管大语言模型 (LM) 在各种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建...……更多
2024-09-06 10:01:00推理,模型,成本,参数,模型,训练
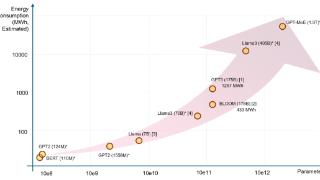
大模型预训练“缩放定律”定律失效?模型推理成“解药”,英伟达一家独大格局要变天?“缩放定律”指导下,AI大模型预训练目前遭遇瓶颈。据路透12日报道,硅谷主要AI实验室的新模型训练计划目前普遍进展不顺,新模型...……更多
2024-11-13 14:09:00英伟,争论,逻辑,意味,根本,策略

...准设计四大目标以及如何通过并行方法加速大规模预训练模型。为了完整体现郑纬民院士的分享及思考,在不改变原意的基础上,量子位对他的演讲内容进行了编辑整理。关于MEET 智能未来大会:MEET大会是由量子位主办的智能科...……更多
2023-01-11 05:00:00清华,院士,高性能,人工智能,模型,智能

...对话可以通过语音识别技术被录入到病例系统中,随后大模型AI推理技术辅助进行智能总结和诊断,医生们撰写病例的效率显著提高。AI推理的应用不仅节省了时间,也保护了患者隐私;在法院、律所等业务场景中,律师通过大...……更多
2024-07-11 16:45:00正在,时代,模型,推理,英特,英特尔

元象XVERSE发布中国最大MoE开源模型:XVERSE-MoE-A36B,该模型总参数255B,激活参数36B,达到100B模型性能的「跨级」跃升。同时训练时间减少30%,推理性能提升100%,使每token成本大幅下降。在多个权威评测中,元象MoE效果大幅超越多...……更多
2024-09-18 13:36:00中国,商用,模型,参数,模型,专家

12月22日,国内首个官方“大模型标准符合性评测”结果公布,百度文心一言、腾讯混元大模型、360智脑、阿里云通义千问四款国产大模型首批通过测试。测试结果称,上述四款模型符合《人工智能大规模预训练模型第2部分:评...……更多
2023-12-26 14:16:00人工智能,国标,人工,模型,结果,智能
更多关于科技的资讯:
近日,上城区发布第四批“人工智能+”机会场景清单,25个场景聚焦产业升级、金融服务、智慧教育、智能医疗等重点领域。据悉
2025-12-13 08:06:00

“甩一甩”就能测温的水银体温计,即将在2026年1月1日全面禁产的政策下退出历史舞台。这则消息引发的全网热议,恰是怀旧情感与环保理性
2025-12-13 08:16:00
厦门网讯(厦门日报记者 应洁)昨日,“新质设计——红点产品设计大奖·中国获奖作品精选展”在红点厦门设计博物馆开展,来自70多家中国企业的百余件“红点奖”获奖作品呈现出国际一流设计的“中国力量”
2025-12-13 08:39:00

厦门网讯(厦门日报记者 翁华鸿 通讯员 张晶晶 王艳红)12日,第六届中国人工智能大赛配套论坛在厦门成功举办。论坛以“融新汇智
2025-12-13 08:39:00
中新经纬12月13日电 据“网信中国”微信号13日消息,2025年12月2日,中央网信办提出并归口的《数据安全技术 电子产品信息清除技术要求》强制性国家标准由国家市场监督管理总局
2025-12-13 10:42:00

大皖新闻讯 12月13日,大皖新闻记者从中国科学技术大学获悉,该校郭光灿院士团队在磁力系统研究中取得新进展。该团队董春华教授研究组通过磁振子与高频声子相互作用
2025-12-13 14:35:00

猫砂是猫用品购买频率最高的产品,其潜力被外界看好。不过,因行业门槛低,这两年入局者多、竞争加剧,猫砂利润像纸一样薄,最低仅1%
2025-12-13 14:56:00

2025年,是新中式珠宝赛道蓬勃发展的一年,也是沁珠宝以文化为帆、品质为桨,实现跨越式发展的关键之年。在刚刚过去的2025年11月
2025-12-13 16:41:00

2025年12月10日,由复旦大学管理学院与鲸鸿动能联合举办的“技术驱动的商业创新:从生态支撑到全球竞逐”主题的案例课堂暨鲸鸿动能案例入库仪式
2025-12-13 16:42:00

河北新闻网讯(刘英、刘岩)12月6日,百洋医药高端制造产业化基地在临空经济区(廊坊)高端智能制造港正式启用投产,将承担全球领先脑肿瘤精准放疗设备ZAP-X火星舟放射外科机器人的生产供应任务
2025-12-13 17:52:00
开栏语 深圳,一座将创新刻入基因的城市。无数海归人才,正是这基因中最活跃的段落。作为改革开放的窗口与先锋,她以澎湃的活力与无限的机遇
2025-12-14 11:22:00
日前,第七届浙江国际智慧交通产业博览会在杭州盛大开幕。开幕式上,多项重磅政策与创新成果集中亮相,省交通运输厅、省科技厅共同发布《交通科技创新合作协议》
2025-12-14 11:39:00

当前,长时储能技术已成为破解新能源波动性难题、打造全天候绿电系统的核心支撑,而AIDC等高能耗行业也亟需依托长时储能的优势破解能源困局
2025-12-14 12:45:00