- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...所有测试的类o1模型都存在显著的思维不足问题。模型的准确率与思维不足之间的关系在不同数据集上表现各异。在MATH500-Hard和GPQA Diamond数据集上,性能更优的DeepSeek-R1-671B模型在取得更高准确率的同时,其UT得分也更高,表明错...……更多
2025-02-04 19:41:00弱点,模型,推理,答案,思路,准确率

...)两部分作为上下文信息,模型能还原出被遮住的文字的准确率。蓝色框内表示仅包含图像中的文字(TEI)的作为上下文信息,并不包含图像(VI),模型能还原出的遮住文字的准确率。
结果表明:绝大多数模型目前都不能胜...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务
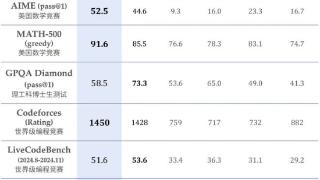
...的推理过程。如上图中的红色实线所示,模型所能达到的准确率与所给定的推理长度呈正相关。且相比于传统的多次采样 + 投票(Majority Voting),模型思维链长度增加展现出了更高的效率。最惊艳的是,发布即上线:所有用户均...……更多
2024-11-22 09:50:00推理,性能,再次,重点,模型,推理

...今最强的基础模型o1。其中,强化微调版的o1 mini,在Top-1准确率上直接跃升180%达到了31%,远超o1的25%。
对此,奥特曼激动地表示:「这项工作效果出奇得好,是我2024年最大的惊喜之一!非常期待大家会用它去构建什么。」目前...……更多
2024-12-09 09:53:00奥特,奥特曼,字节,直播,惊喜,模型
...重要线索,如果模型拥有更长的“思考时间”,它的解题准确率就会显著提高。为什么“长”如此关键?胡倞成解释,Transformer 计算深度有限,只能做有限步的计算,复杂问题如果不能拆分,就超出了模型的处理能力。只有当模...……更多
2025-05-27 10:23:00里来,能力,模型,训练,推理,能力

...步验证成效,可使得专科辅助诊断和复杂病历内涵质控的准确率均达90%。发布会上,科大讯飞还宣布将在今年上半年正式发布基于讯飞星火X1的医疗大模型升级版,确保其深层次诊断推理效果和质控能力业界领先。02 讯飞星火4.0 ...……更多
2025-01-15 15:07:00讯飞,华为,难关,模型,训练,全国

...编程语言。特别在MMLU上,其预训练版本更是达到了84.0%的准确率。消息一出,Mistral AI联创兼首席科学家第一时间转发,直接cue Llama 3.1 405B的那种:Perplexity CEO Aravind Srinivas也开麦了:开源追赶闭源的趋势很明显,未来闭源模型只..……更多
2024-07-26 09:39:00模型,参数,模型,基准,问题,推理

...。在 MATH 数据集上,Q * 帮助 DeepSeek-Math-7b 提升至 55.4% 的准确率,超越了 Gemini Ultra。Q * 算法论文地址:https://arxiv.org/abs/2406.14283可以看出,昆仑万维的技术已经达到了业界的领先水平,在竞争激烈的生成式 ……更多
2024-11-28 10:00:00模型,逻辑推理,中文,推理,逻辑,国产

...问题,OmniSearch的表现显著优于GPT-4V结合启发式mRAG方法,准确率提升了近88%。
多模态知识需求:OmniSearch能够有效地结合图像和文本进行检索,其在需要额外视觉知识的复杂问题上的表现远超现有模型,准确率提高了35%以上。
...……更多
2024-12-05 09:45:00模态,拆解,阿里,检索,过程,智能
...表示,借助多模态的思考能力,VLM-R1将显著提升图像识别准确率,并生成相应的解决方案,“目前版本还处于1.0阶段,仍需更多实验来完善。” ……更多
2025-02-26 07:07:00杭州,推理,模型,视觉,又是,全球

...绩直接惨不忍睹,表现最好的Command R(simple)只有22.47%的准确率。——要知道,这考试瞎蒙也能得25分(四选一)。
当然,这也说明人家不是瞎蒙的,确实动脑子了。视觉上的长上下文另一篇研究来自UCSB,考察的是视觉大模型...……更多
2024-07-23 17:12:00正确率,长上,下文,模型,只是,能力

...:在教育领域,如果 GPT4 在小学级别的数学题目上的评测准确率只有四成,那么我们难免会对 GPT4 的实用性产生怀疑。在咨询领域,大模型的应用场景高度依赖于对不同方案的推演、整体步骤的拆分、解析等能力。而当今大模型...……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队
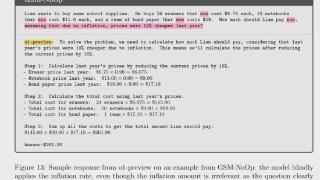
...据集之间,模型存在显著的性能波动,以及与原始 GSM8K 准确率相当的性能下降。这种差异表明,大型语言模型所采用的推理过程可能不是形式化的,因此容易受到某些变化的影响。一个可能的解释是这些模型主要专注于分布内...……更多
2024-10-14 09:55:00数学题,推理,废话,苹果,数学,小学

...调模型。经过测试,人类在该基准上可以达到至少82.1%的准确率,但Claude 3.5 Sonnet和GPT-4o等顶流模型的成绩却远远落后于人类,分别只有64.7%和59.9%。
目前全部数据已经上传至HuggingFace仓库。仓库地址:https://huggingface.co/da……更多
2024-08-08 16:23:00模态,领衔,基准,推理,视觉,能力

...推理问题。刚刚发布时,人类在HellaSwag上能达到超过95%的准确率,SOTA分数却始终难以超过48%。但这种情况并没有持续很久。各个维度的分数持续猛涨,2023年3月,GPT-4在HellaSwag上的各项得分就逼近,甚至超过了人类水平。
https://...……更多
2024-07-01 08:58:00菲尔,得主,难题,经典,农夫,模型

...T4-8k、GPT3.5-turbo-6k、LlamaIndex这种商业模型,平均只有40%的准确率。而像开源模型表现就更不理想了…ChatGLM2-6B、LongLLaMa-3B、RWKV-4-14B-pile、LLaMA-7B-32K平均只有10%的准确率。目前该论文已被ACL 2024接……更多
2024-08-08 09:39:00基准,北大,生成,模型,文本,评估

...的正确率高于原正确率(图4)
正确率提升与自我评估的准确率高度相关(图4(c):),甚至呈线性关系(图5(a))。
采用不同的评价方式效果依次提升:仅使用对/错评价 < 自然语言评价 < 包含 CoT 的对/错评价。这是因为 C...……更多
2024-11-19 09:48:00推理,北大,团队,解释,能力,理论

...引入思想链(CoT,Chain of Thought)的概念,提高了大语言模型(LLM,large language models)在复杂推理任务上的性能,例如算术推理、常识推理和符号推理等。图 | 金明宇(来源:金明宇)CoT 的原理是通过提供推理过程的示例,来教...……更多
2024-03-15 10:41:00罗格,罗格斯,推理,模型,团队,概念

...多学科多模态理解和推理(MMMU)基准测试中取得了69.1%的准确率。不过,基准测试结果是否真的能反映模型对多样化主题的深入理解,仍然有争议,或者说模型是否只是利用了统计模式,而非依靠理解和推理的情况下就能得出正...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本

...来总结评论。实验及结果表 1 显示了每种方法的精确匹配准确率和执行时间。如表所示,在选定的 BIRD (一个数据集,用于测试 LMs 的文本到 sql 的能力)查询类型中,研究者发现手写 TAG(hand-written TAG)基线始终能达到 40% 或更...……更多
2024-09-10 13:38:00自然语言,表格,生成,自然,语言,数据库

...小模型来验证、监督,GPT-4大模型的输出,从而提升输出准确率以及可控性。PVG技术概念早在2021年8月的一篇论文中就被提出来,OpenAI也正是受此灵感启发。这是一种基于博弈论的训练方法,通过模拟证明者和验证者之间的互动...……更多
2024-07-18 09:47:00最新技术,难题,研究,技术,模型,小数

...非凡实力。在软件基准测试SWE-bench Verified中,o3以71.7%的准确率傲视群雄,较其前辈o1模型性能提升超20%。在编程竞技领域,o3于Codeforces竞赛中的评分高达2727分,直逼OpenAI内部顶尖程序员的水平。更令人瞩目的是,在AIME数学竞赛...……更多
2025-02-07 10:14:00透明度,推理,模型,思维,过程,升级

...。根据结果,二者差异显著,其中,前者正确解决问题的准确率是 13.4%,而 o1 的准确率则能够达到 83.3%。这种推理能力的重要意义在于,有望在更广泛的领域应用,例如,药物发现、材料科学、编程、高等数学和物理等。o1 实...……更多
2024-09-20 13:33:00模型,推理,思维,原理,核心,模型

...能让GPT-3的推理性能大幅提升,比如在MultiArith中就将推理准确率从之前的17.7%一下提升到了78.7%但诸如CoT和SelectionInference等方法都是以前向(forwarddirection)的方式从公理(axioms)中搜索证明过程(proof)以推导出最终结论(c……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标

...T-4o mini 仅 37.6 分,ChatGLM3-6B 和 Qwen2.5-1.5B 仅 11.2 和 11.1 的准确率。基于中文 SimpleQA,我们对现有 LLM 的事实性能力进行了全面的评估。并维护一个全面的 leaderboard 榜单。同时我们也在评测集上实验分析了推理 s……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型

...AI 原生 App “支小宝” 采用这套框架,在政务问答场景的准确率提升到了 91%,医疗问答垂直的指标解读准确率可达 90% 以上。梁磊还透露,KAG 框架会进一步向社区开放,并在开源框架 OpenSPG (https://github.com/OpenSPG/openspg) 中原生支..……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型

...法在推理过程中的性能。y 轴表示 MATH500 数据集上的测试准确率,而 x 轴显示生成预算(每个问题的平均标记数),反映了每个问题的计算消耗或标记使用情况。该图表明,随着生成预算的增加,最佳 N 选择和束搜索方法的性能...……更多
2024-10-15 09:56:00框架,团队,联合,模型,过程,步骤

...增强),对比Lean-CoT和Lean-STaR的表现。仅用专家迭代时,准确率就达到了43.0%,低于Lean-STaR (45.5%)。这表明Lean-STaR的性能提升不仅仅来自于专家迭代的使用,思维增强也有不可忽略的效果。问题类型与难度MiniF2F-test中的问题有多个...……更多
2024-08-10 09:47:00顶新,成数,清华,模型,训练,高手

...一组新的 101 个 LitQA2 问题。PaperQA2 在原始 147 个问题上的准确率与后一组 101 个问题的准确率没有显著差异,这表明在第一阶段的优化已经很好地推广到了新的 LitQA2 问题(下表 2)。
PaperQA2 性能分析研究者尝试改变 PaperQA2 的参...……更多
2024-09-13 13:33:00博士后,模型,科研,博士,检索,能力
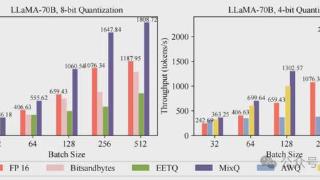
...合精度量化的LlaMA模型在MMLU 20个领域上的数据集进行推理准确率测试表明,采用8bit混合精度量化后的准确率下降不到0.1%:△图6 混合精度量化分类准确率不过,此前已有的混合精度量化的系统的性能普遍不高,主要瓶颈在针对...……更多
2024-10-22 09:57:00推理,清华,吞吐,精度,混合,模型
更多关于科技的资讯:

齐鲁晚报•齐鲁壹点 高雅洁 李潇10月22日,“数智文旅 媒动山海”城市文旅品牌建设交流会在青岛举行。复旦大学旅游学系教授
2025-10-22 20:32:00
10月21日小店政务发布信息,小店区审批局积极推进“开办便利店一件事”集成服务改革,通过流程再造、帮办代办服务、市场需求调研等
2025-10-22 18:56:00
10月22日从中北高新区获悉,该区企业山西天成半导体材料有限公司继今年成功研制12英寸导电型碳化硅单晶材料后,依托自主研发设备再度攻克12英寸高纯半绝缘碳化硅单晶材料技术难关
2025-10-22 18:56:00


近日,美国斯坦福大学联合爱思唯尔数据库(Elsevier Data Repository)发布了《全球前2%顶尖科学家榜单(World's Top 2% Scientists)》
2025-10-22 19:23:00

大河网讯 预计年均省电超千万元,年产能将达到3GWh的规模……富士康旗下储能品牌“富储科能”近日在郑州航空港举行富士康储能量产暨新品发布会
2025-10-22 19:27:00

华为鸿蒙6.0系统正式版于今日(10月22日)发布,Mate 80系列预计将首发搭载。鸿蒙6.0系统以更好看、更好用、更智能
2025-10-22 15:56:00

肖航接受人民日报海外网采访“通过建立深度本地化的运营与服务团队,我们的MAXHUB已成功在全球超过140个国家和地区提供服务
2025-10-22 14:05:00
中国消费名品全国行(河北站)“清河羊绒”供需对接活动举办供需双向奔赴 品牌加速出圈10月21日,中国消费名品全国行(河北站)“清河羊绒”供需对接活动在邢台市清河县举办
2025-10-22 08:10:00

9月26日拍摄的雄安图书馆。9月27日,雄安图书馆少儿阅览区,图书管理员带着小读者通过智能书架挑选图书。拍摄者:齐劲青 中建八局(北京)建设投资有限公司市场部业务经理拍摄时间
2025-10-22 08:19:00

10月15日,以“同心湾区,论道未来”为主题的2025粤港澳大湾区人工智能技术发展论坛在珠海美高梅华府酒店隆重举行。本次论坛由珠海市委统一战线工作部指导
2025-10-22 08:30:00

近日,由中国生产力促进中心协会联合全国各级生产力促进中心、行业协会及专业机构共同发起的2024年度“中国好技术”评选正式落下帷幕
2025-10-22 08:30:00

厦门网讯(厦门日报记者 林露虹 通讯员 管轩 雷飏) 走进厦门软件园,你会发现“人工智能 +”的创新应用图景正徐徐展开
2025-10-22 08:57:00

日前,《全国中老年艺术等级考评规范》团体标准深圳秘书处在十方融海梨花教育办公区正式挂牌。当前,我国人口老龄化程度持续加深
2025-10-22 09:05:00