- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
DeepSeek/o3的弱点找到了!三心二意 明明对了又改错了

DeepSeek和o1/o3一类推理大模型持续带来震撼之际,有人开始研究他们的弱点了。
最新研究揭示:
在遇到高难度问题时,推理大模型可能像“三心二意的学生”一样频繁切换解题思路,却因缺乏深入探索而失败——这种现象被研究者称为Underthinking(欠思考)。

研究团队来自腾讯AI实验室、苏州大学和上海交通大学,主要研究对象是开源的DeepSeek-R1和Qwen QwQ系列模型。

通过分析AI的错误答案,他们发现当前的推理大模型经常在思考早期就走上了正确的路线,但倾向于“浅尝辄止”,很快开始探索别的思路,导致后续生成的数千个tokens对解题毫无贡献。
这种“无效努力”不仅浪费计算资源,还显著降低了答案的正确率。
“三心二意”是罪魁祸首
这一现象在解决数学竞赛题等更为复杂任务时尤为明显。
为了系统分析,团队在三个具有挑战性的测试集MATH500、GPQA Diamond和AIME2024上,对类o1模型QwQ-32B-Preview、DeepSeek-R1-671B等进行了实验。
下图比较了正确和错误回答中的token使用量和思维切换次数。平均来看,类o1模型在错误回答中比正确回答多消耗了225%的token,原因是思维切换频率增加了418%。

为了深入分析这一现象,研究团队开发了一套评估框架,用于判断被放弃的推理路径是否实际上足以推导出正确答案。
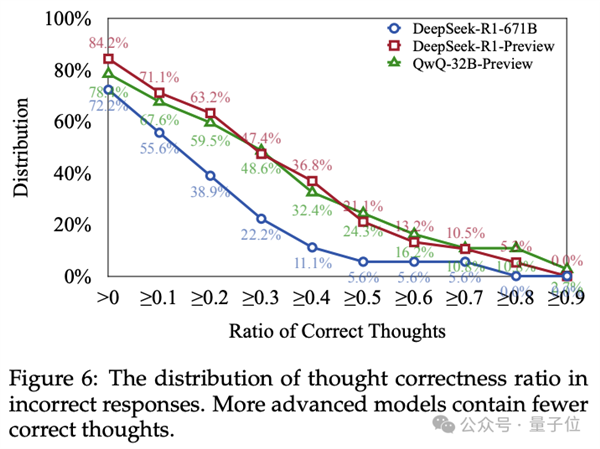
结果观察到,许多模型在回答开头阶段的思路是正确的,但并未继续深入完成推理。

超过70%的错误回答中至少包含一个正确的思路。此外,在超过50%的错误回答中,有10%以上的思路是正确的。
如下图所示的例子,例如,Thought 1通过识别给定方程类似于以(0,0)和(20,11)为中心的椭圆方程,启动了正确的解释。
将两个表达式设为相等,是寻找满足这两个方程的公共点(x, y)的有效方法。
然而,模型并未专注于深入探索这一合理思路,使用进一步的代数操作和优化技术进行分析,而是频繁切换思路,额外消耗了约7270个token,却依然未能得出正确答案。
最终,它得出一个缺乏扩展COT过程支持的猜测答案。

基于这些观察,研究人员提出了一个用于量化Underthinking程度的指标(Underthinking Metric)。

这个指标通过测量错误答案中的token使用效率来评估推理效率,计算从回答开始到第一个正确思路出现所需的token数量与总token数量的比值。
实验结果表明,所有测试的类o1模型都存在显著的思维不足问题。模型的准确率与思维不足之间的关系在不同数据集上表现各异。
在MATH500-Hard和GPQA Diamond数据集上,性能更优的DeepSeek-R1-671B模型在取得更高准确率的同时,其UT得分也更高,表明错误回答中存在更多思维不足。
这意味着,尽管模型整体能力更强,但在不确定时可能生成更长但效率较低的推理过程,可能是因为模型探索了多个错误的推理路径,却未能有效收敛到正确解答。
相反,在AIME2024测试集中,DeepSeek-R1-671B模型不仅取得了更高的准确率,还表现出较低的UT得分,反映出较少的思维不足和更高的token效率。
这表明模型在该任务中,即使未得出正确答案,其推理过程依然保持专注和高效,团队表示这可能是因为模型与 AIME2024所要求的问题类型和推理过程更好地对齐。

理解思维不足现象对于开发能够提供正确答案并具备有效推理过程的模型至关重要。
如何让AI学会“一心一意”
如何让模型像优秀学生一样“沉下心来钻研”?
研究者借鉴了人类考试策略,提出了一种“思路切换惩罚机制” (Thought Switching Penalty,TIP)。
其原理类似于考试时给自己定规矩:“先专注当前方法,至少尝试10分钟再换思路。”
技术细节上,TIP会对触发思路切换的关键词施加惩罚,降低这些词在解码过程中的生成概率,迫使模型在当前路径上探索更久。
例如,当模型开始写“Alternatively, we can consider…”时,TIP会通过调整参数(惩罚强度α和持续时间β),抑制这种过早的切换倾向。

实验结果显示,加入TIP能让模型在数学测试上的准确率上升,同时UT Score下降,说明既减少了无效切换,又提高了答案质量。
例如在AIME2024数学竞赛测试上,加入TIP的QwQ-32B-Preview模型准确率从41.7%提升至45.8%,同时UT Score从72.4降至68.2。

并且这种“无痛升级”无需重新训练模型,仅需调整解码策略,展现了其实用价值。
One More Thing
UC Berkeley教授Alex Dimakis几乎同时分享了类似的观察,
对于DeepSeek-R1和所有推理模型,错误的答案更长,而正确的答案要短得多。
基于此,他们提出一个简单的解决办法,称为“简洁解码” (Laconic decoding)。
并行运行5次模型,从答案中选择tokens最少的。
初步实验结果表示,简洁解码在AIME2024测试上能提高6%-7%的准确率,比Consensus Decoding更好也更快。

论文地址:https://arxiv.org/abs/2501.18585
参考链接:
[1]https://x.com/tuzhaopeng/status/1885179412163027406
[2]https://x.com/AlexGDimakis/status/1885447830120362099
责任编辑:上方文Q
文章内容举报
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2025-02-04 20:45:07
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址: