- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...。强化学习是一种通过试错和奖励来学习最优策略的机器学习方法。在机器人路径规划中,强化学习算法可以通过与环境的交互来学习最优的行动策略。具体而言,机器人可以通过感知环境的状态,选择合适的动作,并根据环境...……更多
2023-12-26 02:30:00学习,学习方法,奖励,机器,策略,方法

...基于模型的方法和无模型的方法。1. 基于模型的安全强化学习方法:基于模型的安全强化学习方法通常依赖于对环境的建模,通过利用物理模型或近似模型进行推理和决策。这类方法通常具有较高的学习效率。例如,基于控制理...……更多
2024-10-09 09:51:00同济,学习方法,深度,理论,方法,应用

强化学习(Reinforcement Learning, RL)是一种机器学习的范式,主要关注的是在特定环境中,如何通过智能体与环境的交互来学习最优行为或策略,以最大化某种累积奖励。它与监督学习和无监督学习不同的是,强化学习不是从带标...……更多
2024-04-28 10:36:00波士顿大学,波士,尺度,算法,驾驶,金融

...张森,曾在悉尼大学从事博士后研究工作,现任TikTok机器学习工程师;詹忆冰,京东探索研究院算法科学家。本文的通讯作者是武汉大学计算机学院教授、博士生导师、国家特聘青年专家罗勇。第一作者为张子屹,目前在武汉大...……更多
2024-10-26 09:48:00算法,奖励,理念,问题,技术,模型

...1 背后的技术到底是什么?OpenAI 技术报告中所强调的强化学习和推断阶段的 Scaling Law 如何实现?为了尝试回答这些问题,伦敦大学学院(UCL)、上海交通大学、利物浦大学、香港科技大学(广州)、西湖大学联合开源了首个类 o...……更多
2024-10-15 09:56:00框架,团队,联合,模型,过程,步骤

...
其中,RLHF 是一种广泛使用的方法,依赖于从人类反馈中学习强化策略。RLHF 的流程包括两个阶段:首先,通过人类偏好数据训练奖励模型(Reward Model, RM),然后使用该奖励模型指导策略模型(Policy Model)的强化学习优化。然而...……更多
2024-10-10 09:56:00框架,优势,统一,综合,模型,奖励

...据(演示和校正的数量)时,他们训练的策略远胜过模仿学习方法 —— 成功率平均超过 101%,周期时间平均快 1.8 倍。这是个具有重大意义的结果,因为其表明强化学习确实可以直接在现实世界中,使用实际可行的训练时间学会...……更多
2024-10-30 09:53:00机器人,机器,时刻,训练,两个,任务

...本或历史版本进行博弈而进行演化的方法,近年来在强化学习领域受到广泛重视。这篇综述首先梳理了自博弈的基本背景,包括多智能体强化学习框架和博弈论的基础知识。随后,提出了一个统一的自博弈算法框架,并在此框架...……更多
2024-09-10 13:38:00清华,北大,学习,算法,策略,训练

...模型,并且在所有实验中,它都是一个线性模型,具有可学习参数 w = {w_0, w_1, . . . , w_N },给定 N 个特征:内循环:拟合 RBR
RBR 拟合过程很简单:首先,使用内容和行为策略规则,并根据命题值确定排名。然后,优化 RBR 权重,...……更多
2024-11-07 09:54:00定律,机器人,模型,规则,机器,安全

...024x1280x3,手腕图像为480x640x3。
运动学数据不像其他模仿学习方法中常见的那样作为输入提供,这是因为由于dVRK的设计限制,运动学数据通常不一致。策略输出包括末端执行器(delta) 位置、(delta) 方向和双臂下颌角度。实验过程...……更多
2024-08-01 09:36:00斯坦,斯坦福,达芬奇,达芬,缝针,外科

如今,机器人学习最大的瓶颈是缺乏数据。与图片和文字相比,机器人的学习数据非常稀少。目前机器人学科的主流方向是通过扩大真实世界中的数据收集来尝试实现通用具身智能,但是和其他的基础模型,比如初版的 StableDiff...……更多
2024-11-19 09:50:00从未,现实,机器,训练,环境,数据
...释性。在模型建立和预测阶段,可以采用机器学习或深度学习方法,利用大规模数据来建立更精确的模型。
三、充分发挥传统统计学的优势:应对数据分析需求传统统计学方法在可解释性方面表现出色。它们能够帮助我们理解...……更多
2024-02-24 05:46:00统计学,变革,传统,统计,时代,数据

...采用标准零件和3D打印外壳,腿部有5个自由度,通过强化学习掌握了动画人物的行走姿态,动作灵巧流畅,还锻炼出跨越复杂地形的能力。在不久前的IEEE活动上,这个迪士尼机器人还跟杭州宇树科技的机器狗面对面炫技斗舞。...……更多
2024-08-02 09:39:00迪士尼,机器人,机器,机器人,机器,迪士尼

...上取得了显著提升,而背后的成功离不开后训练阶段强化学习训练和推理阶段思考计算量的增大。基于此,有人认为,新的扩展律 —— 后训练扩展律(Post-Training Scaling Laws) 已经出现,并可能引发社区对于算力分配、后训练能...……更多
2024-11-26 09:44:00模型,性能,训练,模型,训练,数据

...那些对你未来职业道路有直接影响的课程。2.采用有效的学习方法主动学习:通过提问、讨论和实验来深入理解课程内容,而不是被动地接受信息。分段学习:将复杂的任务分解成小块,每次专注于一个小部分,这样可以提高集...……更多
2024-11-27 15:54:00榕城,职高,专业课程,课程,学习,学生

...、整洁,减少干扰因素,如手机、电视等。3、尝试新的学习方法和技巧:不同的学科可能需要不同的学习方法。尝试使用不同的学习策略,如主动学习(通过提问、讨论和解决问题来学习)、间隔重复(通过定期回顾来巩固记忆)等...……更多
2024-09-04 15:54:00惠州市,高中,惠州,普通高中,高中生,瓶颈

...hatGPT低成本复现流程来了!预训练、奖励模型训练、强化学习训练,一次性打通。最小demo训练流程仅需 1.62GB 显存,随便一张消费级显卡都能满足了。单卡模型容量最多提升 10.3倍。相比原生PyTorch,单机训练速度最高可提升 7.73...……更多
2023-02-17 14:37:00流程,成本,模型,训练,内存,参数

...hatGPT低成本复现流程来了!预训练、奖励模型训练、强化学习训练,一次性打通。最小demo训练流程仅需1.62GB显存,随便一张消费级显卡都能满足了。单卡模型容量最多提升10.3倍。相比原生PyTorch,单机训练速度最高可提升7.73倍...……更多
2023-02-15 15:47:00流程,成本,模型,训练,内存,参数

...期:一、调整复习策略多样化复习方式:尝试使用不同的学习方法,如制作思维导图、进行小组讨论、利用在线资源等,以激发学习兴趣,提高复习效率。分阶段设定目标:将复习内容划分为小块,设定短期和长期目标,每完成...……更多
2024-11-27 17:33:00惠州,瓶颈,高三,复习,高考,学校

...凡解。任何适于解决这类问题的方法,我们都认为是强化学习方法。除了agent和环境的存在,强化学习系统中还有以下四个要素:策略(policy),定义正在学习的agent在指定时间的行为奖励信号(reward signal),定义强化学习问题...……更多
2024-08-10 13:48:00后腿,秘方,人类,奖励,模型,学习

1月2日消息,机器学习和人工智能已经在各行各业掀起了新的变革浪潮,其重点表现形式是各种大模型支撑的“智能体”(agent),指能自主活动的软件或者硬件实体。这些“智能体”可以和用户进行自然对话,并根据对话内容...……更多
2024-01-02 14:52:00人工智能,各行各业,浪潮,变革,人工,机器

...难的问题。于是,问题就来了:语言模型能否自我创建可学习的新任务,从而实现自我改进以更好地泛化用于人类偏好对齐?
为了提升语言模型的对齐能力,人们已经提出了许多偏好优化算法,但它们都默认使用固定的提示词...……更多
2024-11-06 09:44:00框架,人类,问题,提示,策略,模型
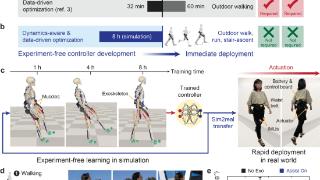
...lation”。该论文展示了一种在计算机仿真环境中通过强化学习来让机器人学习控制策略的新方法。通过这种“计算机仿真中的机器学习”(learning-in-simulation),研究展示了这种方法可以让机器人具备智能性,特别是能适合各种人的...……更多
2024-06-15 09:31:00外骨骼,重磅,颠覆,体力,多种,动作
...数据中的隐藏模式,从而更好地选择和构建特征,为机器学习模型提供更有信息量的输入。
概率统计是AI中不可或缺的一部分。它用于处理不确定性和随机性,帮助AI系统进行推理和决策。贝叶斯统计、马尔可夫链和隐马尔可夫...……更多
2024-01-27 03:05:00人工智能,统计学,人工,策略,统计,智能
...022年,日本科学家在机器人技术、计算机元件制造、机器学习等领域取得更多成果,为该国数字技术的进一步发展奠定了坚实的基础。在智能机器人方面,京都大学和名古屋大学研究人员从脊椎动物的进化中汲取灵感,开发出新...……更多
2023-01-05 01:46:00单芯片,仿生,数据传输,机器人,传输,技术开发

在学校的职高技校阶段,培养良好的学习习惯和自律能力不仅是学业成功的关键,更是个人成长与未来职业生涯中不可或缺的品质。这一阶段,学生们面临着从基础知识向专业技能转变的挑战,如何在这样的环境中塑造自我,...……更多
2024-09-04 14:06:00职高,技校,能力,学校,学习,学习
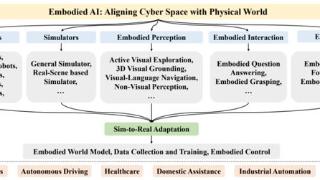
...模型的快速进展展示了在复杂环境中相较于传统深度强化学习方法更强的多样性、灵活性和泛化能力。最先进的视觉编码器预训练的视觉表示提供了对物体类别、姿态和几何形状的精确估计,使具身模型能够全面感知复杂和动态...……更多
2024-07-29 09:39:00中大,文献,调研,深度,实验室,实验
...,涌现了许多强大的工具和技术。其中,数据挖掘、机器学习和人工智能等技术起到了重要作用。例如,聚类分析、分类算法、关联规则挖掘等可以帮助我们发现数据背后的隐藏模式和规律。(四)大数据在国企思政工作中的应用...……更多
2023-11-04 04:58:00思政,思政工作,评估,策略,效果,数据

...。过度的延迟满足可能会让你感到沮丧和不满,但你可以学习如何在满足即时欲望和长期目标之间找到平衡。这可能需要一些时间和努力,但你会逐渐发现,这种能力将对你产生积极影响。3.随着AI的发展与普及,各种人工智能...……更多
2024-05-11 06:22:00教育,孩子,学习,奖励,家长,爸爸

...多媒体信息处理全国重点实验室两大平台,长期从事机器学习、多模态学习和具身智能方向的研究。本工作第一作者为刘家铭博士,研究方向为面向开放世界的多模态具身大模型与持续性学习技术。本工作第二作者为刘梦真,研...……更多
2024-06-21 09:52:00机器,模态,人多,机器人,推理,北大
更多关于科技的资讯:

快科技5月2日消息,索尼Xperia 1 VII跑分已现身Geekbench数据库,设备型号为XQ-FS54,型号符合索尼欧洲市场设备的命名规则
2025-05-02 13:37:00

如今游戏本市场有一个很普遍的情况,那就是绝大多数机型内部有两个内存插槽和两个硬盘插槽,不少购买16GB内存+512GB硬盘的朋友可能觉得不够用
2025-05-02 14:07:00

快科技5月2日消息,OPPO Reno 14系列将于5月中旬发布,Pro机型的跑分已经现身Geekbench数据显示,OPPO Reno14 Pro的CPU为1 Core@3
2025-05-02 14:07:00

快科技5月2日消息,近日Epic Games的CEO蒂姆·斯威尼在播客节目中透露,虚幻引擎6已经在筹备中,并且有望在未来两三年内推出测试版
2025-05-02 14:37:00

快科技5月2日消息,微软企业与操作系统安全副总裁David Weston近日警告称,日常使用管理员账户是个人PC面临的最大安全隐患
2025-05-02 15:37:00

快科技5月2日消息,博主“智慧芯片案内人”今天公布了W17(4-21至4-27)的手机品牌销量排名,小米和华为遥遥领先其他厂商
2025-05-02 15:37:00
东南网5月2日讯(福建日报记者 王永珍 尤方明)数据是数字经济发展的关键生产要素,是国家基础性战略性资源,是发展新质生产力的重要基础
2025-05-02 18:16:00

快科技5月2日消息,日前A股算力芯片龙头海光信息发布公告,称公司董事会于近日收到公司董事长孟宪棠先生的书面辞职报告。海光信息表示
2025-05-02 16:07:00

快科技5月2日消息,今天苹果发布了财报,第二财季总净营收为953.59亿美元,与去年同期的907.53亿美元相比增长5%
2025-05-02 09:07:00

在科技浪潮奔涌、首发经济蓬勃发展的时代浪潮中,齐鲁大地也迎来了一场前所未有的科技盛宴!EX未来科技探索中心,作为国内首个将人形机器人
2025-05-02 09:22:00

快科技5月2日消息,奇瑞集团日前公布了最新销量数据。4月份,奇瑞集团销售新车200760辆,同比增长10.3%。其中,奇瑞集团出口87738辆
2025-05-02 09:37:00

快科技5月2日消息,多名网友日前爆料称,小米SU7 Ultra迎来了史诗级OTA更新。在更新Xiaomi HyperOS的页面能够看到
2025-05-02 09:37:00

快科技5月2日消息,安兔兔发布了4月5000元以上手机性价比榜单,红魔10 Pro+的16GB+512GB版本以504
2025-05-02 09:37:00

快科技5月2日消息,据合肥发布介绍,日前在聚变堆主机关键系统综合研究设施园区,紧凑型聚变能实验装置(BEST)工程总装启动仪式举行
2025-05-02 09:37:00

快科技5月2日消息,根据最新消息,今年底英特尔将推出PantherLake处理器的首个SKU——4P+8E+0LPE+4Xe版本
2025-05-02 10:07:00