- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。大语言模型都卷起来了,模型越做越大,token越来越多,输出越来越长。那么问题来了,如何有效地评估大语言模型的长篇大论呢?要是输出长度长了但...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...你有帮助。前言:网上已经有很多文章介绍AUC、召回率和准确率等指标了,但更多只是从计算公式来讲解,并没有结合工作中实际的业务场景。一上来就介绍指标计算,并没有给到读者一个对于机器学习任务离线效果评估指标体...……更多
2023-05-06 13:00:00评估指标,准确率,评估,机器,指标,策略

...和数学竞赛中的成绩超过了人类平均水平,SAT数学考试的准确率达到了95%,中国高考英语考试的准确率达到了92.5%,表明了目前基础模型的非凡表现。但GPT-4在需要复杂推理或特定领域知识的任务中不太熟练,文中对模型能力(理...……更多
2023-05-13 21:28:00微软,基准,专为,团队,人类,全新

...验评估方面,HourVideo采用五选多任务问答(MCQ)任务,以准确率作为评估指标,分别报告每个任务以及整个数据集的准确率。由于防止信息泄露是评估长视频中的MCQ时的一个重要挑战——理想情况下,每个MCQ应独立评估,但这种...……更多
2024-11-11 13:31:00团队,智能,空间,视频,模态,模型

...学场景。
所有数据和代码、模型均已开源。MMedBench 上的准确率,图 d 展⽰了在 MMedC 上进⼀步预训练使模型性能相⽐于基线显著提升。大规模多语医疗语料(MMedC)构建在构建数据集方面,研究团队收集了一份多语言医疗语料库...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...T4-8k、GPT3.5-turbo-6k、LlamaIndex这种商业模型,平均只有40%的准确率。而像开源模型表现就更不理想了…ChatGLM2-6B、LongLLaMa-3B、RWKV-4-14B-pile、LLaMA-7B-32K平均只有10%的准确率。目前该论文已被ACL 2024接……更多
2024-08-08 09:39:00基准,北大,生成,模型,文本,评估

...行业巨头如GPT-4——便在测试数据集上实现了28.18%的答案准确率提升和13.89%的工具使用精度提高。这挑战了AI开发中的一个惯有想法:更大的模型必然能带来更好的结果。教会AI在使用外部工具和依赖内部知识之间进行判断——就...……更多
2024-12-03 13:34:00正确率,清华,模型,全新,科学,方法

...GPT-4o和Gemini-1.5-pro表现最佳,分别达到了56.1%和55.2%的平均准确率。在所有细分领域中,GPT-4o在摩擦和加速度方面表现优越。相比之下,Gemini-1.5-pro在理解与重力、弹性、反射、吸收与透射、颜色和刚性相关的物理常识方面表现更...……更多
2024-12-07 09:53:00准确率,百分点,百分,模型,物理,视频

...T-4o mini 仅 37.6 分,ChatGLM3-6B 和 Qwen2.5-1.5B 仅 11.2 和 11.1 的准确率。基于中文 SimpleQA,我们对现有 LLM 的事实性能力进行了全面的评估。并维护一个全面的 leaderboard 榜单。同时我们也在评测集上实验分析了推理 s……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型

...中表现显著衰减,表现最佳的o1-preview模型在三轮对话的准确率从87.7%下降到70.7%;在非拉丁文字语言上,所有模型的表现显著弱于英语。在大语言模型(LLMs)不断发展的背景下,如何评估这些模型在多轮对话和多语言环境下的指...……更多
2024-11-26 09:51:00多语,大比,基准,指令,任务,语言

...语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。在现代化工具的帮助下,...……更多
2024-12-09 09:50:00暴虐,准确率,模型,高达,完了,科研
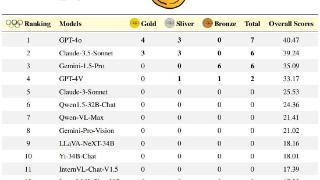
...过基于规则的匹配进行评估,研究团队对非编程任务使用准确率,并对编程任务使用公正的pass@k指标,定义如下:
本次评估中设定k = 1且n = 5,c表示通过所有测试用例的正确样本数量。奥林匹克竞技场奖牌榜:与奥运会使用的...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力
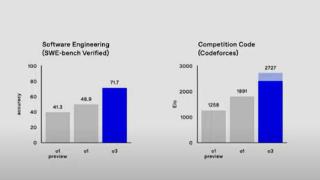
...突破,最高的测试成绩达到了类人水平。o3软件工程测试准确率比o1高近47% 竞赛数学高15% 人类博士专家级生化物高近13%今年9月,OpenAI 发布o1的预览版o1 preview时称,o1是第一个具备真正通用推理能力的大模型,它的核心能力推理...……更多
2024-12-21 09:15:00下一代,推理,正面,模型,模型,测试

... 作为备选。最终的报告结果将基于得分转换为 0 到 100 的准确率指标。未来也可以在我们动态更新的榜单里查看多模态模型在每个月动态更新的最新评测数据,以及在榜单上的最新评测的结果。 ……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本

...提升测试结果显示,经过CodeDPO优化后,代码模型的生成准确率和效率,都获得了一定提升。★代码准确性实验研究团队在HumanEval(+),MBPP(+)和DS-1000三个数据集上进行了广泛实验,涵盖8种主流代码生成模型,包含Base模型和SF...……更多
2024-11-28 09:57:00代码生成,偏好,框架,北大,生成,模型

...数据融合进核保预测模型中,不断修正核保结论,训练核保准确率。这种基于数据的分析和修正过程,使得平安保险核保系统能够准确地评估风险,提高核保的效率和准确性。面对保险行业核保场景新一轮的挑战,平安保险始终与时俱...……更多
2023-11-07 19:58:00平安保险,多维,平安,立体,评估,学习
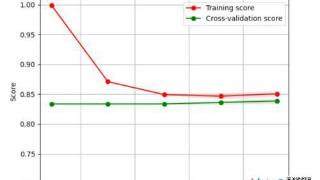
...贝叶斯算法学习曲线,红色线代表测试集(学习过程中)的准确率(Score),绿色线代表该模型在测试集上的准确率,线两侧的半透明带的宽度代表方差(方差越小,模型稳定性越好,泛化性能越好)。从图1可看出,随着训练量(Train examp...……更多
2024-08-26 09:59:00性能分析,算法,电子邮件,性能,常见,邮件

...的 LongVILA 模型在 1400 帧的大海捞针实验中实现了 99.5% 的准确率,相当于 274k 个 token 的上下文长度。此外, MM-SP 系统可以有效地将上下文长度扩展到 200 万个 token 而无需梯度检查点,与环形序列并行(ring sequence parallel……更多
2024-08-22 09:51:00英伟,准确率,支持,视频,序列,训练

...估了模型的性能,结果显示相比现有方法,RecDiff在推荐准确率方面取得了显著提升。未来,RecDiff团队计划将RecDiff拓展到更多推荐场景中,并结合多模态信息,进一步探索该模型的潜力和应用价值。论文:http://github.com/HKUDS/RecDif...……更多
2024-07-30 09:31:00社交,实验室,模型,实验,智能,数据

...评估AI智能体在计算可重复性方面的表现,最简单任务的准确率可以达到60%,最难任务准确率仅有21%大模型的能力越来越强,用户在一些重要的任务中也可以依赖大模型,比如说辅助做科研。不过现有科研辅助相关的基准测试都...……更多
2024-09-26 13:38:00普林,普林斯顿,斯顿,准确率,基准,科学家
...e given problem about geometric shapes.」可以看到,性能并不好,准确率只有 36%,应该有很大的改进空间。不过,在使用 APE 之前,让我们先尝试下一种提示技术:思路链(CoT)推理;这种技术虽然对原始提示词修改不多,但事实证明却...……更多
2024-09-10 13:39:00从头,人工,提示,指南,工程,提示
...模型预测的有效性,确保模型能准确反映市场动态。采用准确率、召回率等评估指标,对模型性能进行量化衡量,是这个阶段的关键操作。金融领域对预测准确性的要求极高,因此,模型要持续优化和更新以适应市场变化。(二)...……更多
2024-04-13 05:53:00优势,驱动,金融,应用,分析,数据
...反馈,不断优化数据模型和算法,提高风险识别和预警的准确率。同时,根据实际业务需求和市场变化,持续改进数据管理流程和方法,提升金融风险数据资产的管理水平。信息化在金融风险数据资产建设方面发挥着重要作用。...……更多
2024-01-22 11:43:00风险管理,信息化,风险,金融,应用,管理

...多学科多模态理解和推理(MMMU)基准测试中取得了69.1%的准确率。不过,基准测试结果是否真的能反映模型对多样化主题的深入理解,仍然有争议,或者说模型是否只是利用了统计模式,而非依靠理解和推理的情况下就能得出正...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本

...论文的几个重要结论:总体结果:LLMs在BrainBench上的平均准确率为81.4%,而人类专家的平均准确率63.4%。LLMs的表现显著优于人类专家子领域表现:在神经科学的几个重要的子领域:行为/认知、细胞/分子、系统/回路、神经疾病的...……更多
2024-12-02 09:51:00结论,神经,科研,人类,水平,专家

...25岁小哥,让ChatGPT帮他创建了个地理位置识别程序,最终准确率最高达99.7%。而且各种细节步骤全在,一边干活还一边教你学习。这一波,被ChatGPT感动到了。更贴心的是,在每次答疑解惑完,ChatGPT都会说上一句:如果你有任何...……更多
2023-02-08 23:47:00准确度,高达,小哥,数据,模型,训练

...问题,OmniSearch的表现显著优于GPT-4V结合启发式mRAG方法,准确率提升了近88%。
多模态知识需求:OmniSearch能够有效地结合图像和文本进行检索,其在需要额外视觉知识的复杂问题上的表现远超现有模型,准确率提高了35%以上。
...……更多
2024-12-05 09:45:00模态,拆解,阿里,检索,过程,智能

...主研发的 AIGC HR 行业大模型和多模态算法,人机对比实验准确率超 92%,在国际处于技术领先水平,但却在融资和业务拓展中遭遇重重困难。在 AI 招聘的蓝海市场中,作为一家创业期的 AI 招聘公司,近屿智能如何向客户证明 AI ...……更多
2023-10-31 21:02:00还是,公司,算法,招聘,智能,候选人
...键步骤。统计学方法提供了各种性能指标,如均方误差、准确率、召回率和F1分数等,用于衡量模型的性能。这些指标允许我们量化模型的预测能力,并对不同模型进行比较。通过统计学方法,我们可以确定哪种模型在特定任务...……更多
2024-01-27 03:05:00人工智能,统计学,人工,策略,统计,智能

...中,深度研究所使用的模型在专家级问题上达到了26.6%的准确率,刷新之前的18.2%的纪录。 相比之下,DeepSeek的R1模型的准确率是9.4%。这一测试由全球众多领域专家共同开发,目的是评估人工智能在广泛学科领域的表现,被视为...……更多
2025-02-04 04:25:00新功能,终极,深度,人类,考试,研究
更多关于科技的资讯:

确定了,日产和本田一拍两散。从确认合体,到官宣“闪离”,只过去短短52天。这场合并,原本就被不少业内人士不看好,现实却也如他们预料那般
2025-02-16 14:53:00

快科技2月16日消息,上汽通用别克品牌宣布,别克GL8陆上公务舱限时优惠价为18.99万元起,相比官方指导价全系降低4
2025-02-16 14:53:00

快科技2月16日消息,春节假期之后,多地机票价格明显回落,尤其是一些旅游城市机票回调幅度更大,适合错峰旅游。据报道,2月7日起至3月底
2025-02-16 14:53:00

2023年,光线传媒董事长王长田预测《哪吒2》票房可能超70亿被群嘲时,谁也没有想到,他还是太保守了。2月13日晚,《哪吒2》票房冲破100亿元
2025-02-16 15:23:00

快科技2月16日消息,据韩国JTBC电视台独家报道,近日,韩国廉价航空易斯达航空(Eastar Jet)多名空姐在清州机场站在机翼上身穿制服拍照
2025-02-16 15:23:00

快科技2月16日消息,不少停车场都有免费停车15分钟的政策,但有些司机却动起了歪心思,利用15分钟免费的规则钻停车场漏洞
2025-02-16 15:23:00

维达金盏花湿厕纸60片*6包(360片)日常售价52.9元,今日天猫百亿补贴直降至34.9元好价。单包折合5.82元、单张仅需0
2025-02-16 15:23:00

快科技2月16日消息,据媒体报道,由于遇到“工程问题和软件错误”,苹果的新版AI Siri上线时间可能会推迟。此前有消息称
2025-02-16 15:53:00

快科技2月16日消息,在手机性能上,苹果iPhone凭借其A系列芯片一直占据优势地位,不过这一局面似乎正在发生变化,据YouTube频道PhoneBuff的最新测试结果显示
2025-02-16 15:53:00

快科技2月16日消息,日前,零跑汽车公布了其智驾计划,宣布将在2025年一季度实现城快及高架NAP功能的全国覆盖。此外
2025-02-16 15:53:00

快科技2月16日消息,据报道,广州海珠国家湿地公园举行的广东省“世界湿地日”暨红树林保护宣传活动上,正式发布了全球新物种——“海珠微瓢虫”
2025-02-16 15:53:00

快科技2月16日消息,据灯塔专业版全球影史票房榜实时数据,《哪吒之魔童闹海》总票房(含点映、预售及海外票房)已超117
2025-02-16 15:53:00

快科技2月16日消息,HKC推出了一款2K 300Hz电竞显示器:ANT253PQ,首发1799元。新款主显示器的屏幕为一块24
2025-02-16 16:23:00

快科技2月16日消息,特斯拉在北美地区发布了2025.2.6软件更新。此次更新主要针对2022年款及后续的Model Y车型
2025-02-16 16:23:00

快科技2月16日消息,日产汽车为恢复业绩,公布了详细的结构改革计划,该计划包括在全球范围内削减产能。其中中国市场产能将减少50万辆
2025-02-16 16:53:00