- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
chatgpt教你写ai包教包会,准确度最高达99.7%

现在,AI小白甚至都不需要看教程,仅凭ChatGPT就可以创建模型。
它不仅帮你找数据集、训练模型写代码,还能评估准确性、创建程序一步到位。
就有这么一个25岁小哥,让ChatGPT帮他创建了个地理位置识别程序,最终准确率最高达99.7%。
而且各种细节步骤全在,一边干活还一边教你学习。

这一波,被ChatGPT感动到了。
更贴心的是,在每次答疑解惑完,ChatGPT都会说上一句:如果你有任何疑问,请告诉我。

具体实现
项目一开始,这位小哥开宗明义:我不想努力了,你可以帮我创建一个AI程序吗?
以两个坐标为输入,并预测他们在哪个国家。

而ChatGPT“欣然”接受挑战,还提醒这位小哥,需要相应数据集,否则模型无法训练。另外要是还有更多信息,就更好了。
首先,需要找到合适的数据集。
小哥再问ChatGPT,结果它到是二话不说直接扔出了三个供其选择,介绍链接都有。

从三个数据集来看,自然地球数据集显然更好,而且还有“边界”、海岸线等信息,这也就意味着要向模型解释“边界”概念,分隔标签。但作为新人而言,第一个数据集与任务相关的数据更多,模型更容易实现,作者最终选择了第一个数据集。
将这个决定告诉ChatGPT之后,紧接着它就来教你创建DataFrame(数据框架),并给出了示例代码。

执行成功后,就来到了第二阶段:模型训练。ChatGPT也二话不说地给了份代码,甚至还附上了详细解释。
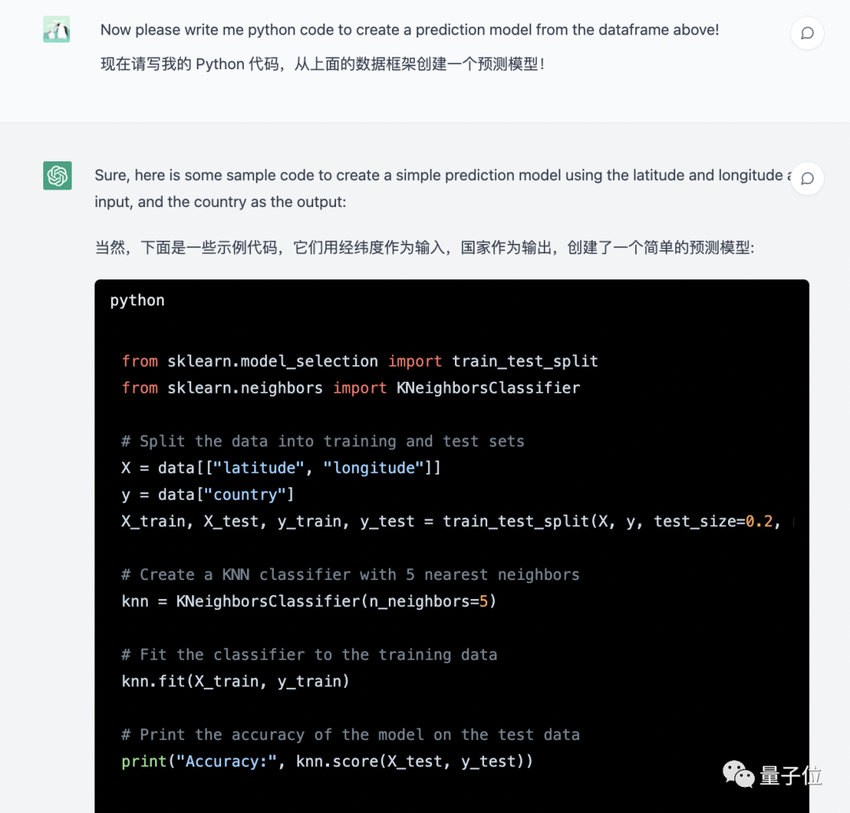
该代码将使用k-NN算法根据给定的坐标来预测国家。KNN算法是一种简单的算法,它根据输入的k个最近邻的大多数类对输入进行分类。
在这个例子中,数据被分成训练集和测试集,比例为80-20。然后用训练集对KNN分类器进行训练,并用测试集对模型的精度进行测试。
请记住,这是一个简单的示例,模型的准确性可能不高。您可以尝试使用不同的算法和k的不同值进行实验,看看是否可以提高模型的准确性.
在丢弃一些空白数据(没有坐标的国家)之后,首次执行k-NN训练成功,并有99.7%的准确率。
不过这个结果并不是那么满意,作者归结了这几个方面的原因:不同国家之间的数据分布不均;存在一些数据错误;偏见等问题。
这样也就来到了第三步:重新评估。

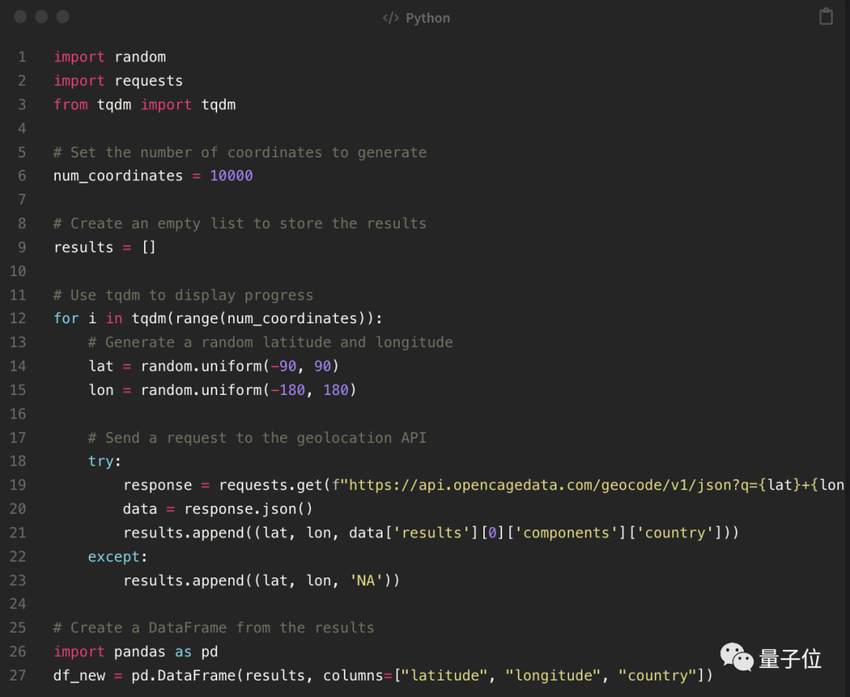
在这段代码中,我使用OpenCage地理编码API从坐标中获取国家信息。您需要使用API密钥替换YORBAPI_KEY以获得对API的访问权限。你可以在OpenCage网站上注册一个免费的API密钥。
按照说明,作者修改了代码,结果显示出现了很多NA错误,相当于只剩下30%数据。不过这个地球确实大部分都是水。(也没毛病,Doge)
最终模型准确性下降了一些,有98.6%,但这个结果作者表示很满意,毕竟只有7个对话回合就帮忙造出来一个AI模型来。
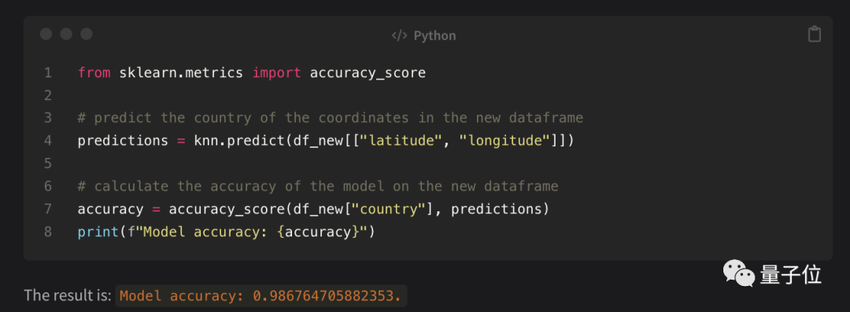
还尝试了其他算法
不过这不是小哥的第一次尝试。第一次谈话时,他用了同一来源的较小数据集,需要更多数据集校正,而ChatGPT提供的第一个模型训练代码是逻辑回归,只有51%的准确性。
而后它又尝试了不同的“求解器”(准确率约为65%),以及其他算法,包括随机森林和k-NN,准确率分别为93%和92%。
这位25岁小哥在SentinelOne担任高级安全研究员,研究和开发恶意软件检测逻辑。
他因为对机器学习很感兴趣开始自学有一定基础,在本次对话中其实他特意以小白的身份与ChatGPT对话,结果被强大的效果惊艳到。
最后他还表示,真的在考虑用“他们”而不是“它”来称呼ChatGPT。
所以AI小白们,ChatGPT快用起来吧。
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2023-02-09 11:45:34
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址:

















