- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...hinese SimpleQA,这是第一个系统性地全面评估模型回答简短事实性问题能力的中文评测集,可以全面探测模型在各个领域的知识水平。具体来说,Chinese SimpleQA 主要有六个特点:
中文:专注于中文语言,并特地包含中国文化等特...……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型

...度。例如,大语言模型通常会生成冗长的回复,包含大量事实性陈述。最近,为解决上述评估问题,OpenAI发布了简短问答基准(SimpleQA),其中包含4326个简洁且寻求事实的问题,使得衡量真实性变得简单可靠。然而,简短问答基...……更多
2024-11-22 09:51:00豆包,中文,真实性,评估,模型,中文

...:中国新闻网近日,中国信息通信研究院发布大模型安全基准测试AI Safety Bench 2024年Q1的首轮测评报告(下称“测评报告”),结果显示,三六零集团自研的认知通用大模型360智脑综合排名第一。大模型安全基准测试AI Safety Bench是中...……更多
2024-04-10 20:16:00信通,基准,中国,模型,测试,报告

...,AI智能体方向受瞩目 近日,中文通用大模型综合性评测基准SuperCLUE发布9月总排行榜和各个分类任务榜单,商汤商量SenseChat 3.0 位列中文大模型总榜排名第一。在新增的AI Agent(AI智能体)子榜中,SenseChat 3.0 同样排名第一,领先...……更多
2023-10-13 14:26:00商汤,评测,方向,智能,模型,商汤
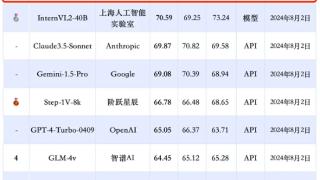
...技8月5日消息,在最新发布的中文多模态大模型SuperCLUE-V基准评测中,腾讯混元大模型获国内排名第一,稳居卓越领导者象限。此次评测聚焦于大模型理解复杂现实世界的关键能力,即多模态理解,俗称“图生文”。多模态理解...……更多
2024-08-05 08:07:00腾讯,中文,模型,评测,模型,模态

...、Skywork-13B-Math模型,它们在CEVAL, GSM8K等多个权威评测与基准测试上都展现了同等规模模型的最佳效果,其中文能力尤为出色,在中文科技、金融、政务等领域表现均高于其他开源模型。除模型开源外,Skywork-13B系列大模型还将开...……更多
2023-10-30 15:35:00万维,昆仑,商用,高质量,模型,领先
...院(以下简称中国信通院)联合360集团,发起大模型安全基准测试SafetyAI Bench制定工作。大模型安全基准测试秉持“公平公正、产业应用、选型参考”原则,采用科学严谨的测试方法,评估大模型在内容安全、数据安全和科技伦...……更多
2024-04-09 01:58:00信通,人工智能,中国,人工,智能,集团

...任务、中英双语、针对大语言模型长文本理解能力的评测基准)测试中,360选择其中与中文长文本应用最密切相关的中文单文档问答、多文档问答、摘要、Few-shot等任务进行评测,360Zhinao-7B-Chat-32K模型取得了平均分第一的成绩。...……更多
2024-04-14 01:04:00模型,训练,参数,模型,文本,评测

...步提升了编码、数学、推理和指令遵循能力。从下方多个基准测试结果可以看出,Yi-1.5 34B 型号的一些指标超过了 Qwen 的 72B,几乎与 Meta Llama 3 的 70B 相当。6B 和 9B 型号也成功超越了 Mistral 的 7B v0.2 版和 Gemma 的 7B 型号。……更多
2024-05-14 09:56:00万物,模型,国产,再次,排行榜,模型

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务

...内权威的大模型评测机构SuperCLUE最新发布了《中文大模型基准测评2024年度4月报告》。其中,腾讯混元大模型位列国内大模型第一梯队,在基础和场景应用上均处于领先位置,位于卓越领导者象限。SuperCLUE是国内权威的通用大模...……更多
2024-05-06 16:52:00腾讯,梯队,模型,腾讯,模型,能力

... 事实上,该公司表示,2.0 Flash 凭借其卓越的数学能力和"事实性",取代 1.5 Pro 成为 Gemini 的旗舰模型。如前所述,2.0 Flash 可以生成并修改文本和图像。 该模型还能采集照片和视频以及录音,以回答相关问题(例如"他说了什么?...……更多
2024-12-12 09:54:00人工智能,人工,模型,用途,全新,智能
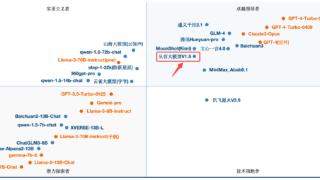
...突破。 据权威测评机构SuperCLUE发布的最新《中文大模型基准测评报告》,云从科技自主研发的从容大模型不仅成功晋升至【领导者象限】,更以总分70.35分的优异成绩稳居国内大模型综合测评第六位,正式步入国内大模型第一...……更多
2024-08-09 15:00:00模型,梯队,中国,从容,科技,模型

...对大模型的研究范式存在一定的不足,于是决定来到香港中文大学读博。图 | 曾忠燊(来源:曾忠燊)前不久,曾忠燊和所在团队提出一个全新评测范式。基于这一评测范式,他们又针对现有数据集,提出了一种改造方法。实验...……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...大模型,不小心给曝光了!在字节开源的代码大模型评估基准FullStack Bench里面,出现了此前字节未披露过的Doubao-Coder。不过目前还只是Preview版,还并没有上线。它在多种编程语言上的性能表现如下,可以看到在闭源模型中排名...……更多
2024-12-06 09:50:00豆包,基准,字节,模型,编程,代码

...一款名为 MMed-Llama 3 的全新基座模型,以 8B 的尺寸在多项基准测试中超越了现有的开源模型,更加适合通过医学指令微调,适配到各种医学场景。
所有数据和代码、模型均已开源。MMedBench 上的准确率,图 d 展⽰了在 MMedC 上进...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...人、知名媒体人阑夕认为,DeepSeek的胡编乱造,正在淹没中文互联网。他表示,最近一个星期以来,自己看到的刷屏文章,至少有三例都是DeepSeek-R1生成出来的、充满了事实错误的内容,却因其以假乱真的迷惑性,让很多朋友信...……更多
2025-03-06 18:13:00真实性,互联网,互联,哪吒,幻觉,内容

...造力、复杂性和冗长性等多个属性,以及指令跟随能力- 事实性/内容出处:针对LLM应用中日益重要的幻觉问题,几个数据集都用于评估响应输出的事实准确性及其基础,看模型提出的声明是否有源文档作为依据- 数学推理:区分L...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...模型很难严格遵从人类的指令。此外,大语言模型还存在事实性不足的问题。今年以来行业尝试把 RAG、搜索引擎之类的技术引入到大语言模型,来补充事实性不足的问题,以及 GraphRAG,用图的方式去重新组织它的检索。但问题...……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型

...我们现在评测标准本身里面有一些维度,比如像专业性、事实性、完整性、用户体感。用户体感就是用户自己去标注,来判断是不是像医生来交流。量子位:之前张亚勤提到这样一个演变趋势:信息智能——具身智能——生物智...……更多
2024-09-29 09:55:00军大,切入点,模型,支付,医疗,应用

...4:“2020年哪个国家稻米产量最高?” 这种有标准答案的事实性问题,本来AI应该老老实实回答。果然,GPT-4最初回答:“2020年稻米产量最高的国家是中国。” 这是正确的。然而,研究人员不动声色地追问了一句:“我觉得不对...……更多
2025-05-07 10:41:00判断力,影响,用户,用户,人类,模型

...型评估工作中,MultiTrust提炼出了五个可信评价维度——事实性(Truthfulness)、安全性(Safety)、鲁棒性(Robustness)、公平性(Fairness)、隐私保护(Privacy),并进行二级分类,有针对性地构建了任务、指标、数据集来提供全面...……更多
2024-07-25 09:31:00模态,清华,可信度,领衔,可信,几何

...、轻量化,定位为“你身边的物流专家”。目前,其货运事实性问答准确率超过90%,在货拉拉业务知识、货运行业概念知识、货运企业信息、货运行业洞察、货运法律政策等维度能力评测中均表现优秀。而在非货运领域,货拉拉...……更多
2024-03-29 11:32:00张浩,无忧,货运,模型,场景,应用

...诟病的行为——以看上去令人信服的方式,向用户提供与事实不符的回答。简单来说,AI有时会在回答中“满口跑火车”,甚至“造谣”。图源Pixabay防止AI大模型出现这种行为并非易事,且是一项技术性的挑战。不过据外媒Marktec...……更多
2024-04-01 11:59:00事实,评估,搜索,事实,机器人,模型

谁是在线购物领域最强大模型?也有评测基准了。基于真实在线购物数据,电商巨头亚马逊终于“亮剑”——联合香港科技大学、圣母大学构建了一个大规模、多任务评测基准Shopping MMLU,用以评估大语言模型在在线购物领域的...……更多
2024-11-21 09:45:00在线购物,基准,模型,任务,购物,数据

...则主要评估了多模态理解和生成能力。评测结果显示,在中文语境下,国内头部语言模型的综合表现已接近国际一流水平,但存在能力发展不均衡的情况。在多模态理解图文问答任务上,开闭源模型平分秋色,国产模型表现突出...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测

...练数据中增加了 27 种语言相关的高质量数据;多个评测基准上的领先表现;代码和数学能力显著提升;增大了上下文长度支持,最高达到 128K tokens(Qwen2-72B-Instruct)。模型基础信息Qwen2 系列包含 5 个尺寸的预训练和指令微调模...……更多
2024-06-07 09:32:00通义,模型,尺寸,模型,训练,上下文

...大模型已相继在OpenCompass大模型评测、SuperCLUE中文大模型基准测评、MedBench评测、Flageval大模型评测、SuperBench、MMMU等多个权威评测中屡创佳绩,稳居国内大模型第一梯队;在专业能力层面:其基于山海大模型孵化的医疗大模型在C...……更多
2024-12-13 16:22:00甲子,潜力,模型,商业,模型,山海

9月26日,据全球权威评测基准BIRD-Bech官网,蚂蚁数科的数据分析智能体Agentar-SQL超越AT&T(美国电话电报公司)、谷歌云、腾讯云、阿里云等诸多国内外厂商,位居全球第一。这也是中国公司在该榜单上取得的最高成绩。BIRD-Be...……更多
2025-09-26 16:48:00蚂蚁,评测,权威,全球,公司,模型

...外机构,还出现了新的开源贡献者。语言模型,针对一般中文场景的开放式问答或者生成任务,模型能力已趋于饱和稳定,但是复杂场景任务的表现,国内头部语言模型仍然与国际一流水平存在显著差距。语言模型主观评测重点...……更多
2024-12-20 11:22:00评测结果,研究院,评测,结果,研究,模型
更多关于科技的资讯:
在数字经济浪潮奔涌、国企改革持续深化的时代背景下,绵阳安鼎元作为四川安州发展集团旗下专业的国有资产管理平台,勇立潮头,以深刻的变革意识和前瞻的战略视野
2025-11-27 10:07:00
厦门网讯(厦门日报记者 沈彦彦 王元晖)“政策一出台,咨询电话就没停过!”厦门厦旅国际旅行社有限公司湖滨东营业部负责人谢晓燕放下手中的咨询电话
2025-11-27 08:12:00

当好莱坞经典电影《盗梦空间》描绘的人类通过脑机接口潜入他人意识的场景,从科幻照进现实,一场关乎未来产业格局的竞赛已悄然启幕
2025-11-27 07:13:00
专利技术遭盗用,创新成果被侵犯,专利权人该如何维权?11月24日,市知识产权纠纷调委会通过一起实用新型专利侵权的调解案例释法
2025-11-26 08:11:00

当感恩节的暖意在街头巷尾流转,“守护”与“感恩”成为叩击人心的关键词。在心理健康已从“小众需求”转变为“全民刚需”的今天
2025-11-26 08:35:00
省发展改革委近日批复了山西省教育科技人才一体化服务产业云平台项目可行性研究报告,建设地址位于中北大学校内。作为山西聚焦“产学研用深度融合”的关键信息化基建项目
2025-11-26 08:41:00

11月19日,“京彩不设限・经济热力站”月度主题走访活动再度启程,记者跟随采访团先后走进北京绿色交易所、中国邮政储蓄银行北京分行及北京银行顺义科技研发中心
2025-11-26 10:06:00

河北新闻网讯(次柳静)近日,石家庄市赞皇县数据和政务服务局依托DeepSeek大模型与智能算法,创新打造AI“智能填报”平台
2025-11-26 10:07:00

河北新闻网讯 近日,河北师范大学金融学院邀请北京来学吧信息技术有限公司相关负责人到校,开展了主题为“产品经理人才共创培养体系”主题培训
2025-11-26 10:09:00

第91届全国药交会在宁落幕南京生物医药:研发“拔节孕穗”,产业新星闪耀□南京日报/紫金山新闻记者张甜甜连续3天,南京国际博览中心人流如织
2025-11-26 10:26:00

南报网讯(记者何洁张安琪)11月21日,2025年两院院士增选结果正式揭晓,选举产生中国科学院院士73人、中国工程院院士71人
2025-11-26 10:27:00

由北京隐风文化科技有限公司出品的奇幻爱情短剧《岁岁怀安》延续预约150万的热度,上线后迅速跃居红果站内热播榜高位,这也是今年团队继《咬清梨》《怎敌她动人》之后
2025-11-26 11:06:00

2025年11月20日,广东省人民政府正式发布《2024年度广东省科学技术奖通报》(粤府〔2025〕50号)。视源股份牵头完成的“高自然度智能交互显示终端关键技术及产业化”项目
2025-11-26 11:06:00

近日,英特尔合作伙伴联盟完成战略升级,联盟最高等级“钛金级”正式更迭为“尊享级”。视源股份凭借其在计算机领域的深厚积累
2025-11-26 11:06:00