- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...hinese SimpleQA,这是第一个系统性地全面评估模型回答简短事实性问题能力的中文评测集,可以全面探测模型在各个领域的知识水平。具体来说,Chinese SimpleQA 主要有六个特点:
中文:专注于中文语言,并特地包含中国文化等特...……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型

...度。例如,大语言模型通常会生成冗长的回复,包含大量事实性陈述。最近,为解决上述评估问题,OpenAI发布了简短问答基准(SimpleQA),其中包含4326个简洁且寻求事实的问题,使得衡量真实性变得简单可靠。然而,简短问答基...……更多
2024-11-22 09:51:00豆包,中文,真实性,评估,模型,中文

...:中国新闻网近日,中国信息通信研究院发布大模型安全基准测试AI Safety Bench 2024年Q1的首轮测评报告(下称“测评报告”),结果显示,三六零集团自研的认知通用大模型360智脑综合排名第一。大模型安全基准测试AI Safety Bench是中...……更多
2024-04-10 20:16:00信通,基准,中国,模型,测试,报告

...,AI智能体方向受瞩目 近日,中文通用大模型综合性评测基准SuperCLUE发布9月总排行榜和各个分类任务榜单,商汤商量SenseChat 3.0 位列中文大模型总榜排名第一。在新增的AI Agent(AI智能体)子榜中,SenseChat 3.0 同样排名第一,领先...……更多
2023-10-13 14:26:00商汤,评测,方向,智能,模型,商汤
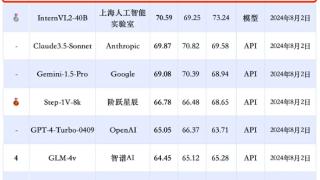
...技8月5日消息,在最新发布的中文多模态大模型SuperCLUE-V基准评测中,腾讯混元大模型获国内排名第一,稳居卓越领导者象限。此次评测聚焦于大模型理解复杂现实世界的关键能力,即多模态理解,俗称“图生文”。多模态理解...……更多
2024-08-05 08:07:00腾讯,中文,模型,评测,模型,模态

...、Skywork-13B-Math模型,它们在CEVAL, GSM8K等多个权威评测与基准测试上都展现了同等规模模型的最佳效果,其中文能力尤为出色,在中文科技、金融、政务等领域表现均高于其他开源模型。除模型开源外,Skywork-13B系列大模型还将开...……更多
2023-10-30 15:35:00万维,昆仑,商用,高质量,模型,领先
...院(以下简称中国信通院)联合360集团,发起大模型安全基准测试SafetyAI Bench制定工作。大模型安全基准测试秉持“公平公正、产业应用、选型参考”原则,采用科学严谨的测试方法,评估大模型在内容安全、数据安全和科技伦...……更多
2024-04-09 01:58:00信通,人工智能,中国,人工,智能,集团

...任务、中英双语、针对大语言模型长文本理解能力的评测基准)测试中,360选择其中与中文长文本应用最密切相关的中文单文档问答、多文档问答、摘要、Few-shot等任务进行评测,360Zhinao-7B-Chat-32K模型取得了平均分第一的成绩。...……更多
2024-04-14 01:04:00模型,训练,参数,模型,文本,评测

...步提升了编码、数学、推理和指令遵循能力。从下方多个基准测试结果可以看出,Yi-1.5 34B 型号的一些指标超过了 Qwen 的 72B,几乎与 Meta Llama 3 的 70B 相当。6B 和 9B 型号也成功超越了 Mistral 的 7B v0.2 版和 Gemma 的 7B 型号。……更多
2024-05-14 09:56:00万物,模型,国产,再次,排行榜,模型

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务

...内权威的大模型评测机构SuperCLUE最新发布了《中文大模型基准测评2024年度4月报告》。其中,腾讯混元大模型位列国内大模型第一梯队,在基础和场景应用上均处于领先位置,位于卓越领导者象限。SuperCLUE是国内权威的通用大模...……更多
2024-05-06 16:52:00腾讯,梯队,模型,腾讯,模型,能力

...事实上,该公司表示,2.0 Flash 凭借其卓越的数学能力和\"事实性\",取代 1.5 Pro 成为 Gemini 的旗舰模型。如前所述,2.0 Flash 可以生成并修改文本和图像。 该模型还能采集照片和视频以及录音,以回答相关问题(例如\"他说了什么...……更多
2024-12-12 09:54:00人工智能,人工,模型,用途,全新,智能
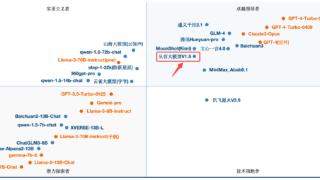
...突破。 据权威测评机构SuperCLUE发布的最新《中文大模型基准测评报告》,云从科技自主研发的从容大模型不仅成功晋升至【领导者象限】,更以总分70.35分的优异成绩稳居国内大模型综合测评第六位,正式步入国内大模型第一...……更多
2024-08-09 15:00:00模型,梯队,中国,从容,科技,模型

...对大模型的研究范式存在一定的不足,于是决定来到香港中文大学读博。图 | 曾忠燊(来源:曾忠燊)前不久,曾忠燊和所在团队提出一个全新评测范式。基于这一评测范式,他们又针对现有数据集,提出了一种改造方法。实验...……更多
2024-03-04 10:23:00革新,模型,范式,中文,推理,团队

...大模型,不小心给曝光了!在字节开源的代码大模型评估基准FullStack Bench里面,出现了此前字节未披露过的Doubao-Coder。不过目前还只是Preview版,还并没有上线。它在多种编程语言上的性能表现如下,可以看到在闭源模型中排名...……更多
2024-12-06 09:50:00豆包,基准,字节,模型,编程,代码

...一款名为 MMed-Llama 3 的全新基座模型,以 8B 的尺寸在多项基准测试中超越了现有的开源模型,更加适合通过医学指令微调,适配到各种医学场景。
所有数据和代码、模型均已开源。MMedBench 上的准确率,图 d 展⽰了在 MMedC 上进...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...造力、复杂性和冗长性等多个属性,以及指令跟随能力- 事实性/内容出处:针对LLM应用中日益重要的幻觉问题,几个数据集都用于评估响应输出的事实准确性及其基础,看模型提出的声明是否有源文档作为依据- 数学推理:区分L...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...模型很难严格遵从人类的指令。此外,大语言模型还存在事实性不足的问题。今年以来行业尝试把 RAG、搜索引擎之类的技术引入到大语言模型,来补充事实性不足的问题,以及 GraphRAG,用图的方式去重新组织它的检索。但问题...……更多
2024-09-13 13:33:00知识,准确率,推理,蚂蚁,框架,模型

...我们现在评测标准本身里面有一些维度,比如像专业性、事实性、完整性、用户体感。用户体感就是用户自己去标注,来判断是不是像医生来交流。量子位:之前张亚勤提到这样一个演变趋势:信息智能——具身智能——生物智...……更多
2024-09-29 09:55:00军大,切入点,模型,支付,医疗,应用

...型评估工作中,MultiTrust提炼出了五个可信评价维度——事实性(Truthfulness)、安全性(Safety)、鲁棒性(Robustness)、公平性(Fairness)、隐私保护(Privacy),并进行二级分类,有针对性地构建了任务、指标、数据集来提供全面...……更多
2024-07-25 09:31:00模态,清华,可信度,领衔,可信,几何

...、轻量化,定位为“你身边的物流专家”。目前,其货运事实性问答准确率超过90%,在货拉拉业务知识、货运行业概念知识、货运企业信息、货运行业洞察、货运法律政策等维度能力评测中均表现优秀。而在非货运领域,货拉拉...……更多
2024-03-29 11:32:00张浩,无忧,货运,模型,场景,应用

...诟病的行为——以看上去令人信服的方式,向用户提供与事实不符的回答。简单来说,AI有时会在回答中“满口跑火车”,甚至“造谣”。图源Pixabay防止AI大模型出现这种行为并非易事,且是一项技术性的挑战。不过据外媒Marktec...……更多
2024-04-01 11:59:00事实,评估,搜索,事实,机器人,模型

谁是在线购物领域最强大模型?也有评测基准了。基于真实在线购物数据,电商巨头亚马逊终于“亮剑”——联合香港科技大学、圣母大学构建了一个大规模、多任务评测基准Shopping MMLU,用以评估大语言模型在在线购物领域的...……更多
2024-11-21 09:45:00在线购物,基准,模型,任务,购物,数据

...则主要评估了多模态理解和生成能力。评测结果显示,在中文语境下,国内头部语言模型的综合表现已接近国际一流水平,但存在能力发展不均衡的情况。在多模态理解图文问答任务上,开闭源模型平分秋色,国产模型表现突出...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测

...练数据中增加了 27 种语言相关的高质量数据;多个评测基准上的领先表现;代码和数学能力显著提升;增大了上下文长度支持,最高达到 128K tokens(Qwen2-72B-Instruct)。模型基础信息Qwen2 系列包含 5 个尺寸的预训练和指令微调模...……更多
2024-06-07 09:32:00通义,模型,尺寸,模型,训练,上下文

...大模型已相继在OpenCompass大模型评测、SuperCLUE中文大模型基准测评、MedBench评测、Flageval大模型评测、SuperBench、MMMU等多个权威评测中屡创佳绩,稳居国内大模型第一梯队;在专业能力层面:其基于山海大模型孵化的医疗大模型在C...……更多
2024-12-13 16:22:00甲子,潜力,模型,商业,模型,山海

...外机构,还出现了新的开源贡献者。语言模型,针对一般中文场景的开放式问答或者生成任务,模型能力已趋于饱和稳定,但是复杂场景任务的表现,国内头部语言模型仍然与国际一流水平存在显著差距。语言模型主观评测重点...……更多
2024-12-20 11:22:00评测结果,研究院,评测,结果,研究,模型

...nAI o1模型(至少目前)还不是多模态大模型,同时在回答事实性问题时也不如其他模型。所以在图像互动、常识问答、互联网搜索方面,GPT-4o依然是更胜一筹的选择。当然,OpenAI明确表示未来会给这个模型增加联网、文件和图像...……更多
2024-09-13 13:34:00新时代,推理,逻辑,模型,模型,问题

...力评测中,文心一言4.0表现优异,位居国内第一,其中在中文推理、中文语言等评测上,文心一言遥遥领先,和其他模型拉开明显差距,中文理解上,文心一言4.0领先优势明显,领先第二名GLM-4 0.41分,GPT-4系列模型表现较差,排...……更多
2024-04-22 09:46:00评测报告,清华,模型,评测,能力,报告

...,执行这些数据集的全面评估变得非常耗时。此外,这些基准在训练期间也容易受到污染的影响。为此, LMMs-Eval 提出了 LMMs-Eval-Lite 来兼顾广覆盖和低成本。他们也设计了 LiveBench 来做到低成本和零数据泄露。LMMs-Eval-Lite: 广覆盖...……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本
更多关于科技的资讯:
如果你一直以为卫星手机是华为的天下,那这次就要让你大开眼界了!大家可能还记得,全球首款卫星手机并不是来自华为,而是由中兴推出的
2024-12-28 13:51:00

据报道,华为Mate70Pro及更高阶的版本更是引领潮流,率先拥抱UFS4.0闪存技术,其读写速度如闪电般迅疾,文件传输效率实现质的飞跃
2024-12-28 13:54:00

华为终端上线华为Mate70Pro+可靠性测试视频。视频显示,得益于业界首发的高亮钛玄武架构,华为Mate70Pro+在经过火箭冲击
2024-12-28 13:58:00
华为或将推出一款融合折叠屏和PC功能的万元级平板电脑。据知情人士透露,这款产品可能将成为市场上的新宠。华为一直秉承着“敢于做别人想得到但做不出来的产品”的理念
2024-12-28 13:59:00
中国电视制造商在超大尺寸电视市场取得了显著进展,TCL成功超越三星成为80英寸及以上电视领域的领军品牌。根据市场研究公司Omdia的数据显示
2024-12-28 14:00:00

今天下午一加除了发布两款新机外,还带来了一加平板和一款新耳机。一加平板主要配置有:11.6英寸2.8K144Hz7:5的LCD屏
2024-12-28 14:01:00
在如今的手机市场,骁龙8至尊版处理器似乎成了“香饽饽”。小米15、iQOO13、一加13、荣耀Magic7纷纷以这款顶级芯片为核心
2024-12-28 14:03:00
12月28日消息,据“长沙市中心医院订阅号”官方报道,近日,在长沙市中心医院(南华大学附属长沙中心医院)急诊抢救室里,一场紧张的抢救正在展开
2024-12-28 14:09:00

快科技12月28日消息,据小米官方消息,小米“基于物联网的智能空调低碳运行技术”荣获中国节能协会节能减排科技进步二等奖
2024-12-28 14:09:00

12月25日,由东鹏控股携手景德镇陶瓷大学及旗下多家子公司共同完成的“高掺量锂尾矿陶瓷砖/板关键技术与篆雕装饰设计研究及产业化”项目
2024-12-28 14:23:00

围绕英伟达即将推出的GeForce RTX 50系列显卡,玩家们的热情持续高涨,大家都在热切等待着这款次世代GPU的正式亮相
2024-12-28 14:39:00

快科技12月28日消息,近日有广州网友发视频称,在海珠区广纸历史公园,有工人给枯萎变黄的草坪进行喷涂作业。可以看到喷过的地方变得绿油油一片
2024-12-28 14:39:00

快科技12月28日消息,近日,黄子韬在其社交平台上宣布,一旦粉丝数量达到1500万,他将送出10台汽车作为奖励。这一消息迅速引发了广泛关注
2024-12-28 14:39:00
快科技12月28日消息,今天,2024年的微博游戏大赏圆满落幕,其中《黑神话:悟空》荣获了年度玩家选择游戏的殊荣,这无疑是对其卓越品质和受欢迎程度的高度认可
2024-12-28 14:39:00