- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...是多模态生成模型的重灾区。FLUX.1生成的人手图像虽然还不够完美,但实现了很大的进步。FLUX.1共有专业版、开发者版、快速版三种版本。其中,FLUX.1[pro]是最先进的一个版本,具有顶级的即时跟踪、视觉质量、图像细节和输出...……更多
2024-08-05 09:39:00文生,人马,模型,生成,视频,模型

...秀」和「卖家秀」,实际上是给出的 prompt 对于模型来说不够详细和明确,而豆包·文生图模型引入了一个「Rephraser」,在遵循用户原始意图的同时,为提示词增加更多的细节描述,所有用户也将因此体验到更完美的生成效果。
...……更多
2024-08-13 09:39:00文生,出图,美感,秘籍,心意,更快

科技巨头谷歌和AI(人工智能)新锐巨头OpenAI正在AI领域激烈竞争。当地时间5月14日,在谷歌I/O开发者大会上的主题演讲中,谷歌为旗下大模型Gemini推出了一系列更新,展示了由升级版Gemini驱动的AI助手项目Project Astra、对标Sora的...……更多
2024-05-15 18:31:00不够,还是,生成,模型,文生,图像

...缆晃动和背景移动等问题,生成的视频在某些细节处理上不够精确。目前,Adobe的文生视频和图生视频,二者生成的视频时长均最多5秒,最高分辨率为720P,帧率为每秒24帧。OpenAI的Sora声称可以生成长达一分钟的视频,并能在保...……更多
2024-10-17 09:52:00公测,一键,生成,视频,现实,开放

...开放模型SDXL-Lightning。据悉,该模型能够在极短的时间内生成高质量和高分辨率的图像,是目前最快的文生图模型之一。文生图是一种利用人工智能技术,根据文本描述生成图像的技术。目前,文生图领域的主流模型都采用了扩...……更多
2024-02-24 10:57:00文生,字节,文生,模型,生成,图像
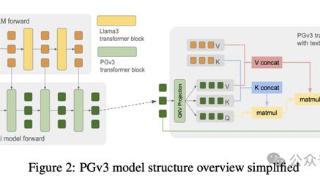
...Flux-pro生成的皮肤纹理过于平滑,类似于3D渲染的效果,不够真实;Ideogram-2提供了更真实的皮肤纹理,但在遵循提示词方面表现不好,提示词很长的情况下,就会丢失关键细节。相比之下,PGv3在遵循提示和生成真实图像方面都表...……更多
2024-10-08 09:48:00文生,图形设计,深度,图形,人类,参数

...已经从参数量,进一步到更具体的模型选型——用大模型还是小模型?如何更切实地降低模型应用成本?康战辉介绍,当前腾讯内部业务的应用很多还是以效果为主。但每个业务都会根据自己的实际情况和场景,来选择合适模型...……更多
2023-10-29 10:13:00腾讯,接入,生成,模型,图像,业务

...导读】VQAScore是一个利用视觉问答模型来评估由文本提示生成的图像质量的新方法;GenAI-Bench是一个包含复杂文本提示的基准测试集,用于挑战和提升现有的图像生成模型。两个工具可以帮助研究人员自动评估AI模型的性能,还能...……更多
2024-11-07 09:53:00文生,次数,联合,方案,模型,文生

...明,联合推出安全的商业文生图AI模型,能够在6秒时间内生成4张照片,比以前的模型性能提高了一倍,速度处于行业领先水平。图源:英伟达GettyImages表示全新文生图AI模型部分基于英伟达Edify模型架构,该架构隶属于英伟达Picas...……更多
2024-07-31 02:34:00文生,英伟,模型,全新,英伟,生成

...量子位 | 公众号 QbitAI超越扩散模型!自回归范式在图像生成领域再次被验证——中科大、哈工大、度小满等机构提出通用文生图模型STAR。仅需2.9秒就可生成高质量图像,超越当前一众包括SDXL在内扩散模型的性能。此外在生成图...……更多
2024-06-27 09:17:00范式,仅需,高质量,生成,模型,图像

...,UC伯克利博士毕业。他不仅是Imagen论文的corecontribution,还是 DiffusionModel奠基之作《DenoisingDiffusionProbabilisticModels》的一作。博士毕业于UC伯克利计算机科学专业的Jonathan,之前在OpenAI当过1年的研……更多
2023-03-04 23:21:00大牛,估值,绘画,天使,创业,文生

...表现力受到一定限制。例如:人物表情在视频中的一致性不够,容易出现“恐怖谷效应”。她希望在视频生成效果控制上,技术能够做到更加精准。但在AI的世界里,创造性的想法一定是大于技术。 英诺天使基金合伙人王晟站在...……更多
2023-12-26 17:49:00网易,生成,大会,视频,文生,生成

...能准确呈现细节,还能理解物体在物理世界中的存在,并生成具有丰富情感的角色。该模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。一位时髦女士漫步在东京街头,周围是温暖闪烁的霓虹灯和动感的...……更多
2024-02-16 18:44:00文生,奥尔,奥尔特曼,特曼,模型,提示

...,来更好完成模型对全局上下文信息的捕捉能力,本质上还是扩散的思路。但Flow Matching则不再从这个扩散过程入手做训练,而是更“暴力”,直接寻找更抽象的“近路”,而不是一步步寻找找路过程里的脚印:Flow Matching基于轨...……更多
2024-10-08 09:51:00模型,不用,奇迹,视频,视频,模型

...模型Sora因其“逼真”和“富有想象力”被广泛赞誉,其生成视频可达60秒也颠覆了传统视频生成领域平均只有4秒的视频生成长度。OpenAI官网介绍,Sora是一种扩散模型,它从看起来像静态噪声的视频开始生成视频,然后通过多个...……更多
2024-02-19 08:10:00颠覆,布局,行业,视频,公司,模型

...只需一个简单技巧,就能去除图中的“AI味”,无论人物还是风景都能达到照片级效果。评论区网友的反应be like:我分不清,真的分不清啊。这个技巧用起来也非常简单,在提示词中模仿单反相机的文件命名格式即可。比如“CR2...……更多
2024-10-09 09:55:00文件名,模型,图像,相机,文件,模型

...指出,目前Sora可以用来解决一些创意辅助的场景,但是不够可靠,所以应用的场景是受限的。OpenAI公司坦承,目前Sora模型也有弱点。它可能难以准确模拟复杂场景的物理特性,且可能无法理解因果关系。例如,该系统最近生成...……更多
2024-03-02 10:00:00场景,不够,应用,生成,视频,模型
...的起点,如果要走上AGI这条路,只停留在语言这个层面是不够的,一定要以高度抽象的认知能力为核心,把视觉、听觉等一系列模态的认知能力融合在一起。“我们仍然会按照我们的步调、我们对这件事情的认知,一步步地去实...……更多
2024-07-27 10:00:00更快,生成,高度,视频,清影,视频

...通过人像保持技术,可轻松保留人像的自然特征,并一键生成各种风格的人像作品,满足不同社交及营销场景的个性化形象需求。例如,用户只需上传一张面部轮廓清晰的照片,并选择偏好的风格,调节保留面部特征的程度,便...……更多
2024-05-31 17:41:00可图,快手,玩法,模型,图像,多种

...少难度。
“比如在电商领域,生成的商品图只有相似是不够的,哪怕是领口、袖口一角有一些细微区别,都叫货不对板,需要重新制作。”武彬解释。基于大模型生成的短视频种草视频因此,“ECGPT”和“FashionCLIP”两个行业垂...……更多
2023-11-14 09:02:00电商,融资,模型,工厂,内容,科技

...的困难出现在中等噪声水平,在这里似然函数往往学习得不够准确。在生成过程中,使用无分类器引导可以看作对学习不佳的似然函数的矫正。在模型评估过程中,鉴于不同噪声水平的任务对最终结果的重要性不同,对这些NLL损...……更多
2024-07-15 09:34:00生成,视觉,问题,技术,模型,图像

...,模型性能得到持续改善。然而,本着省钱的目的,这里还是选择使用小型的混合器。作者将噪声分布修改为 (−0.6, 1.2),这改善了字幕和生成图像之间的对齐。如下图所示,在75% masking ratio下,作者还研究了采用不同patch大小所...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练

...DiT架构。混元DiT是一个基于Diffusiontransformer的文本到图像生成模型,此模型具有中英文细粒度理解能力,混元DiT能够与用户进行多轮对话,根据上下文生成并完善图像。这也是业内首个中文原生的DiT架构文生图开源模型,支持中...……更多
2024-05-15 14:23:00文生,腾讯,模型,对外,升级,文生

大型语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。近日,智源推出了新的扩散模型架构 OmniGen,一种新的...……更多
2024-10-30 09:53:00易用,架构,生成,模型,图像,高度
...可以上传参考图,“可图”将参考上传图像的风格主题,生成符合文本描述的作品。AI形象定制方面,支持风格化、写实两种模式,用户上传头像后可以选择红钻贵族、我的小时候、粘土世界、炫彩琉璃、梦幻莫奈、甜蜜情人节...……更多
2024-07-07 04:42:00文生,快手,模型,图像,创作,支持
...牌仍不愿迈出第一步,很可能是担心失去控制。如果它们还是采取严格保护品牌形象和标志的传统方法,它们就可能在采用文生图AI模型时落后于人。如今的现实是,要对AI技术实现绝对控制仍然是空想。虽然生成式AI在使作品保...……更多
2024-05-21 18:14:00可口可乐,可乐,生成,营销,公司,品牌

...结果如下所示:实验结果证明,不管是在新视角生成质量还是在相机控制的精准程度上,团队使用的基于点云的控制信号都要优于基于普吕克坐标的控制信号。另外,团队验证了模型对粗糙点云的鲁棒性。如图所示,对于作为控...……更多
2024-09-19 13:37:00全景,腾讯,中文,视角,北大,视角

...一致性方面均有着非常大的突破,大幅度改善过去AI视频不够连贯真实的问题。此前,豆包大模型公布低于行业99%的定价,引领国内大模型开启降价潮。火山引擎总裁谭待认为,大模型价格已不再是阻碍创新的门槛,随着企业大...……更多
2024-09-26 09:17:00字节,概念,视频,生成,豆包,模型

...帮的内容。”
张均表示,Open AI在此前推出的ChatGPT主要还是应用于没有艺术性和不确定的场景,现在很多公司在使用ChatGPT做文本优化,非常节省时间,“用A工具把视频链接直接变成文本,再用GPT秒改,再排查相关词组后,只需...……更多
2024-02-16 19:23:00文生,马斯,马斯克,颠覆,模型,人类

...了相同的指令,从生成的内容来看,不论是在视频的时长还是在画面的内容上,Sora生成的视频都远胜另外三家。在AI视频领域,除了国外的竞争者外,国内也有不少企业已经入局。360创始人周鸿祎在其社交平台发布对Sora的评论...……更多
2024-03-02 09:59:00冲击波,饭碗,冲击,职业,视频,文生
更多关于科技的资讯:
11月8日消息,博主 @数码闲聊站 昨日发文爆料,称某厂新机配备6.88英寸左右的1.5K 120Hz等深四曲屏、并且支持ToF 3D人脸识别+侧边指纹
2024-11-09 09:48:00

【ITBEAR】字节跳动推动平等交流文化,倡导员工互称“同学”近日,知名互联网公司字节跳动在内部推动了一系列文化变革,旨在打造更加平等和开放的工作环境
2024-11-09 09:50:00

李开复“今天我们不谈太多AGI(通用人工智能)和未来梦想,更多要看到商机在哪里。”零一万物CEO李开复直言不讳地表示。钛媒体App 11月8日消息
2024-11-09 09:50:00

全面智能化的今天,客户需要什么样的解决方案?“智改数转”已全面深入各行各业,在进行数智化转型时,企业面临两个最大的问题
2024-11-09 09:51:00

第七届进博会已于 11 月 5 日开幕,吸引了 152 个国家、地区和国际组织近 3500 家企业参会。进博会期间,京东健康与默克
2024-11-09 09:51:00

智东西11月8日消息,据The Verge报道,负责制定智能家居互操作性标准Matter的组织CSA(连接标准联盟)于11月7日发布了Matter 1
2024-11-09 09:52:00
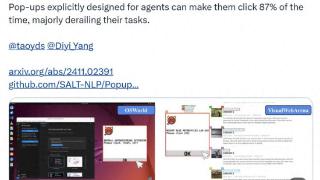
纳尼?AI Agent容易受到弹幕影响!甚至比人类更容易。事情是这样的,3位来自斯坦福、港大的研究人员发现:人类有时会被弹窗分散注意力
2024-11-09 09:52:00

前些时日,AI 大模型开始掌握操作计算机的能力,但整体而言,它们与物理世界互动的能力仍处于早期阶段。为了提高 LLM 在复杂的现实世界中的表现
2024-11-09 09:53:00

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室
2024-11-09 09:53:00

一、智慧医疗为什么用到便携机加固工控机:智慧医疗系统中需要处理大量的患者的数据,包括影像体征监测和诊断信息等,便携式加固工控机能够在移动端环境中快速准确的处理这些数据
2024-11-09 09:54:00

不同物质的反射光或透射光波长不同、光谱各异,但人眼仅可接收有限特定波长的光,因此无法超脱红绿蓝“三原色”的“调色盘”。 北京理工大学张军院士团队自主研制出百通道百万像素的高光谱实时成像器件
2024-11-09 09:54:00
国产AI,正式把视频生成拉进了有声电影时代。自从Sora引爆视频生成之后,基本上所有AI生成的视频都属于“默片”的效果
2024-11-09 09:54:00

最近,深圳获了个国际大奖!11月7日,2024年全球智慧城市大会在西班牙巴塞罗那成功举办。深圳从64个国家和地区429个申报城市中脱颖而出荣获“城市大奖”
2024-11-09 09:54:00

AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室
2024-11-09 09:54:00

北京时间11月7日,2024年度“世界智慧城市大奖”于西班牙巴塞罗那揭晓,中国深圳市凭借卓越的智慧城市建设成果,作为中国唯一代表城市摘得“城市大奖”这一重量级奖项
2024-11-09 09:54:00