- 我的订阅
- 科技
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
比LoRA更高效!上交大&哈佛推出新微调框架,瞄准特定任务方向

比LoRA更高效的模型微调方法来了——
以常识推理为例,在参数量减少8~16倍的情况下,两种方法能达到相同效果。
新方法名叫LoRA-Dash,由来自上海交通大学和哈佛大学的研究人员提出,主要针对特定任务微调模型往往需要大量计算资源这一痛点。

研究完成的主要工作是:
对高效微调过程中的TSD(Task-specific Directions,特定任务方向)进行了严格定义,并详细分析了其性质。 为了进一步释放TSD在下游任务中的潜力,提出新的高效微调方法LoRA-Dash。
来看具体内容。

从头搭建特定任务方向的框架
随着大型语言模型的发展,针对特定任务微调模型往往需要大量计算资源。
为了解决这一问题,参数高效微调(PEFT)策略应运而生,像LoRA等方法被广泛应用。
在LoRA中,作者们通过一系列实验发现,LoRA本质上是捕捉一些预训练中已学习到的但并不重要的方向,这些方向对应的特征在之后的下游任务中被LoRA放大。
LoRA把这些方向定义为“特定任务方向”(Task-specific Directions, TSD)。
然而,在LoRA原论文关于TSD的叙述中却出现了一些矛盾和冲突。
比如作者认为TSD是∆的最大的几个奇异值对应的奇异向量。
然而这些从∆中得到的奇异向量基本不可能和的奇异向量一致。
这些冲突导致研究者们对TSD的概念很模糊,更别说利用这些方向。
为了解决这些问题,论文作者对高效微调过程中的TSD进行了严格的定义,并详细分析了其性质。
TSD的定义
首先,定义矩阵的基、矩阵的方向如下。
定义1:对于一个矩阵 ,其左奇异向量和右奇异向量分别由矩阵和表示,矩阵的基定义如下。
核心基:矩阵的核心基定义为
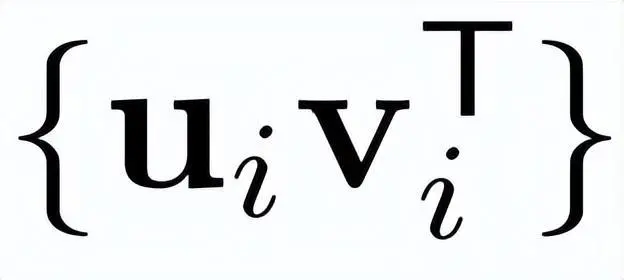
,其中每个
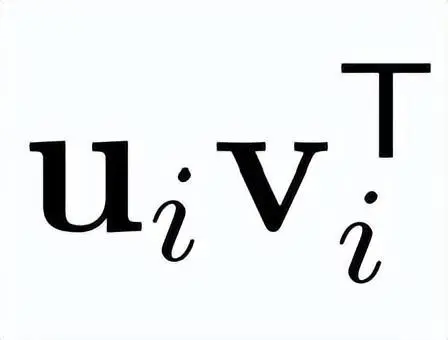
是由奇异向量和构成的秩为1的矩阵。
全局基:矩阵的全局基定义为
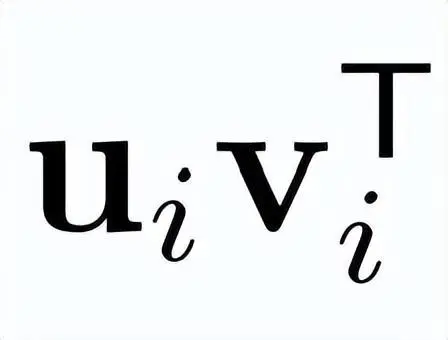
,对于所有, ,涵盖了左奇异向量和右奇异向量的所有组合。
定义2:矩阵 ∈ ℝx(其中 < )的方向基于其全局基定义,采用其奇异值∑的扩展集合,并用零填充。
具体表示为(1,0,…,0,2,0,…,0,n,…,0)∈ ℝx,即通过行展平的∑。
研究人员提醒道,任何全局基都可以视为一个单位方向,因为它的方向是一个one-hot的向量。
至于特定任务方向,作者们基于以下前提进行研究:
对于任何特定任务,矩阵空间ℝx中存在一个最优矩阵
对于预训练权重矩阵,其针对该任务的最佳调整为∆=-。
在PEFT中,研究人员只能获得及其方向的信息。
由于∆和*的方向基于各自的基,他们首先将二者投影到的全局基上。
定义3:定义 ·(·)为将一个坐标系中的方向投影到另一个坐标系中的投影算子。
特别地,()=(11,…,)∈ ℝ是将矩阵 ∈ ℝx 的方向投影到矩阵 ∈ ℝx的全局基上。
基于矩阵的全局基,(*)表示需要演变的方向。
由于最多只能利用个核心基,它只能改变其方向的个值。
因此,重点关注核心方向的变化。
变换过程中,不同核心方向的坐标值变化程度不同,受下游任务的多样性影响,某些核心方向可能变化显著,而其他方向变化较小。
定义的变化率衡量了第个核心方向的变化程度:
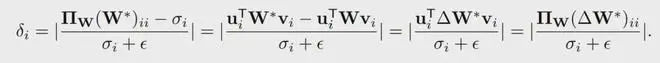
因此,研究人员定义TSD为:
对于某个特定任务和预训练权重矩阵,假设该任务的最优权重为,则该任务在上的TSD是指那些在从到的变化过程中,其坐标值表现出显著高变化率的核心方向。
TSD的性质及使用难点
作者通过一系列实验,得出了TSD的两个性质:
TSD主要对应于较小但非最小的奇异值相关的核心方向。 TSD仅涵盖少数方向,这些方向在从到*的转变过程中具有显著的变化率,而其他大多数核心方向的变化率则较小或可以忽略不计。
尽管TSD的定义和性质已被充分探讨,但由于在微调之前∆和都是未知的,因此在实际操作中事先利用TSD信息几乎不可能。
为解决这一挑战,作者假设LoRA的∆预测出的高变化率核心方向与TSD密切相关。
通过广泛实验,结果显示预测方向与实际TSD之间存在高度重叠,由此得出一个重要结论:
无论LoRA的秩设置、训练步骤或模型层次如何,LoRA的∆一致地捕捉到了任务特定方向的信息。
这表明,即便在未知TSD的情况下,仍能通过LoRA训练中获得的∆捕捉到这些关键信息。
释放TSD潜力:LoRA-Dash
为了进一步释放TSD在下游任务中的潜力,研究人员提出了一个新的高效微调方法LoRA-Dash。
LoRA-Dash包含两个主要阶段:
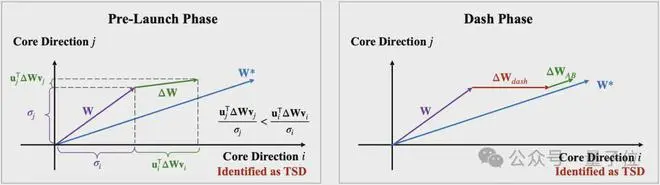
第一是“预启动阶段”。在此阶段,任务特定方向被识别。这是模型优化的关键部分,确保识别出最需要调整的方向。
具体而言,这一阶段中LoRA-Dash利用在t次更新之后得到的∆进行TSD的预测,确定下一阶段需要被调整的方向。
第二是“冲刺阶段”。在这一阶段,模型利用之前识别的TSD的潜力,进行微调优化,使预训练模型更好地适应特定任务。
具体而言,作者直接模拟TSD的坐标变化,加速模型的适应性调整,从而提升其在新任务中的表现。
LoRA-Dash的伪代码如图。

实验
作者们分别在常识推理(commonsense reasoning)、自然语言理解(natural language understanding)和主体驱动生成(subject-driven generation)任务上做了实验。
实验结果表明,LoRA-Dash在各个任务上都取得了远超LoRA的性能提升。
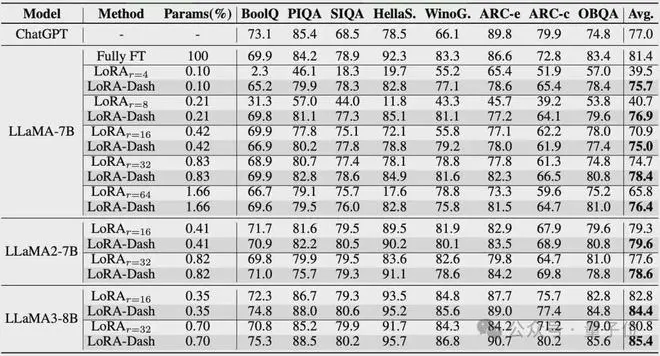
常识推理(使用LLAMA-7B,LLAMA2-7B以及LLAMA3-8B进行微调):
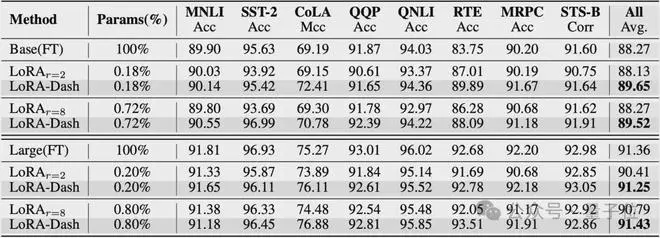
自然语言理解(使用DeBERTaV3-base和DeBERTaV3-large进行微调):
主体驱动生成(使用SDXL进行微调)。与LoRA相比,LoRA-Dash和原图的一致性更高,比如图中的狗和花瓶。

实验结果证明了TSD对于下游任务的有效性,LoRA-Dash能够充分释放TSD的潜能,进一步激发高效微调的性能水平。
目前相关论文已公开,代码也已开源。
论文:https://arxiv.org/pdf/2409.01035代码:https://github.com/Chongjie-Si/Subspace-Tuning项目主页:https://chongjiesi.site/project/2024-lora-dash.html
以上内容为资讯信息快照,由td.fyun.cc爬虫进行采集并收录,本站未对信息做任何修改,信息内容不代表本站立场。
快照生成时间:2024-09-18 11:45:07
本站信息快照查询为非营利公共服务,如有侵权请联系我们进行删除。
信息原文地址:













