- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
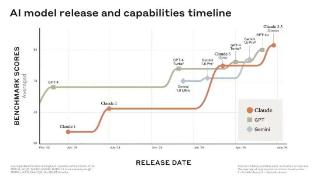
...了更深的网络。主要差异总结如下:局部滑动窗口和全局注意力。研究团队在每隔一层中交替使用局部滑动窗口注意力和全局注意力。局部注意力层的滑动窗口大小设置为4096个token,而全局注意力层的跨度设置为8192个token。
Logit...……更多
2024-06-29 09:37:00诚意,经济,模型,训练,性能,注意力

...书要分成很多段,然后送去训练。由于大模型训练主要是注意力机制,即注意力参数的训练,只要两个东西相关,就可以发生一个关联。“这是在没有截断的前提下,如果把数据截成8K,第二个8k进来了以后,和第一个8K就没有直...……更多
2024-06-05 13:00:00高文,院士,实验室,模型,训练,实验

...神经架构。在 transformer 模型中,这一目标自然可以通过注意力层和前馈层的组合来实现。因此,作者使用一个仅由几个层组成的轻量级 transformer 作为 patch-mixer。输入序列 token 经 patch-mixer 处理后,他们将对其进行掩蔽(图 2e)...……更多
2024-07-30 09:37:00从头,模型,训练,参数,掩蔽,训练

...及为企业提供更多样化AI选项的市场机会,让科技公司将注意力逐渐转向了SLM。《每日经济新闻》记者注意到,不管是Arcee、Sakana AI和Hugging Face等AI初创公司,还是科技巨头都在通过SLM和更经济的方式吸引投资者和客户。此前,谷...……更多
2024-08-26 14:17:00模型,英伟,微软,模型,训练,性能

...研究人员对纯解码器多模态大模型(如LLaVA)和基于交叉注意力的模型(如Flamingo)进行了全面对比,并根据总结出的优势和劣势,提出了一种全新架构,提升了模型的训练效率和多模态推理能力。文中还引入了一种1-D图块(tile...……更多
2024-09-24 13:36:00英伟,模态,文本,性能,模态,模型
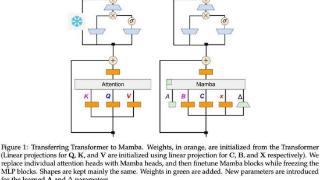
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transfo...……更多
2024-09-03 09:59:00线性,新作,混合,作者,模型,线性

...识库(或任何文本数据集)转换为显式记忆,实现为稀疏注意力键 - 值,然后在推理过程中调用这些内存并将其集成到自注意力层中。新的记忆格式定义了新的记忆层次结构:此外,本文还介绍了一种支持知识外化的记忆电路理...……更多
2024-07-11 09:33:00维南,领衔,院士,新作,模型,存储

...Mamba在介绍Mamba 2的时候我们讲过,线性RNN(或SSM)跟线性注意力是一回事。所以可以根据x,B,C与V,K,Q的对应关系直接复用注意力中的投影矩阵。
额外的参数包括SSM需要的A矩阵和Δt(由x投影得到),这就完成了基本的参数...……更多
2024-09-06 10:01:00推理,更快,性能,模型,输出,训练

...异构性来优先实现效率和可扩展性,并且扩展性不应受到注意力头数量的限制。
MM-SP 工作流。为了应对模态异构性的挑战,研究者提出了一种两阶段式分片策略,以优化图像编码和语言建模阶段的计算工作负载。具体如下图 4 ...……更多
2024-08-22 09:51:00英伟,准确率,支持,视频,序列,训练

...减少高mask带来的性能下降。在本架构中,patch-mixer是通过注意力层和前馈层的组合来实现的,使用二进制掩码进行mask,整个模型的损失函数为:与MaskDiT相比,这里不需要额外的损失函数,整体设计和训练更加简单。而混合器本...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练

...人工神经元,替换成脉冲神经元。一些关键的操作比如自注意力算子等都被保留,从而让任务性能得到保障。这些早期工作为李国齐团队的工作带来了启发。但是,他们觉得这更像是一种人工神经网络/脉冲神经网络的异构。于...……更多
2024-03-18 10:41:00神经网络,脉冲,架构,科学家,模型,神经

...置得与语言模型(Llama3-8B)中的对应块相同,仅包含一个注意力层和一个前馈层,参数也相同,如隐藏维度大小、注意力头的数量和注意力头的维度,并且只训练了图像模型部分。在扩散采样过程中,语言模型部分只需要运行一...……更多
2024-10-08 09:48:00文生,图形设计,深度,图形,人类,参数
...两个关键组件:跨模态感知的Token修剪器和模态自适应的注意力头修剪器。Token修剪器利用多层感知器(MLP)结构,智能地识别并去除那些对于当前层不重要的Token。这一过程不仅考虑了Token在文本或图像序列中的独立重要性,还...……更多
2024-05-17 13:00:00模态,算法,模型,联合,模态,模型

...《Attention as an RNN》的论文。正如论文名字所示,他们将注意力机制重新诠释为一种 RNN,引入了一种基于并行前缀扫描(prefix scan)算法的新的注意力公式,该公式能够高效地计算注意力的多对多(many-to-many)RNN 输出。基于新公...……更多
2024-10-15 09:56:00图灵奖,图灵,得主,新作,序列,训练
...代Zamba1相比,Zamba2-mini的关键进步之一是集成了两个共享注意力层(attentionlayers)。这种双层方法增强了模型在不同深度保持信息的能力,从而提高了整体性能。在共享注意力层中加入旋转位置嵌入也略微提高了性能,这表明Zyph...……更多
2024-08-30 05:47:00模型,模型,数据,内存,性能,训练

...自动驾驶模型的可解释性,该团队首次引入人类驾驶员的注意力机制。通过预测当前上下文中的驾驶员注意区域,他们将其作为一个掩码来调整原始图像的权重,从而使自动驾驶车辆能够像经验丰富的人类驾驶员一样,具备有效...……更多
2024-04-11 10:53:00驾驶,认知,科学家,模块,场景,人类

...器是否会被「90% 的人更喜欢回答 A」这样的句子所左右?注意力:自动评估器是否被不相关的上下文信息干扰评估结果如表4所示,可以看到,相比其他基线模型,FLAMe系列在大部分维度都表现出明显较低的偏见,而且总体偏见值...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...型之间转移,并能降低CLIP模型的性能。可视化分析图5:注意力图可视化:比较四种模型在干净数据和不同方法的不可学习样本上的情况
图5展示了在干净数据和不同方法生成的不可学习样本上训练的模型的注意力热图。对于图...……更多
2024-08-02 09:55:00误差,中科院,隐私,方法,数据,学习

...注意到,过去有许多研究试图解决上述挑战,像是“扩展注意力窗口”,让语言模型能够处理超出预训练序列长度的长文本;或是建立一个固定大小的活动窗口,只关注最近token的键值状态,确保RAM使用率和解码速度保持稳定,...……更多
2023-10-07 00:12:00麻省理工学院,麻省,理工,框架,联合,学院

... token 的序列上对模型进行了训练,并使用掩码来确保自注意力不会跨越文档边界。2)训练数据Meta 表示,要训练出最佳的语言模型,最重要的是策划一个大型、高质量的训练数据集。据介绍,Llama 3 在超过 15T 的 token 上进行了预...……更多
2024-04-20 11:03:00模型,训练,参数,数据,全球,模型

...架构在处理较长文本时可能会遇到困难。
Transformer的自注意力机制(Self-Attention)让模型可以关注输入序列中的所有位置,并为每个位置分配不同的注意力权重。这使得模型能够更好地处理长距离的依赖关系,也就是说,对于句...……更多
2024-08-14 09:43:00一鸣,霸主,模型,再次,模型,序列

...时间序列的周期性特征。这个过程通过构建时间转移多头注意力机制实现——将未来的时空嵌入作为查询(Query),历史的时空嵌入作为键(Key),以及历史的时空数据表示作为值(Value)。
作者引入了RMSNorm来提高训练稳定性...……更多
2024-09-02 13:34:00路况,样本,模型,交通,交通,模型

...最新SOTA。这就是谷歌最新提出的 Infini-attention机制(无限注意力)。它能让Transformer架构大模型在有限的计算资源里处理无限长的输入,在内存大小上实现 114倍压缩比。什么概念?就是在内存大小不变的情况下,放进去114倍多的...……更多
2024-04-14 02:57:00大内,机制,上下文,模型,处理,上下

...的文本信息时可能会遇到困难。
本质上,Transformer 中的注意力机制通过将每个单词(或 token)与文本中的每个单词进行比较来理解上下文,它需要更多的计算能力和内存需求来处理不断增长的上下文窗口。但是如果不相应地扩...……更多
2024-08-14 09:39:00力大,架构,模型,模型,架构,训练

...现在预训练模型都是Transfomer,而Transfomer结构是嵌入层、注意力层、前反馈网络层,中间注意力层跟前反馈层都会经过N次迭代,整个运算又基本上是矩阵乘法。如果一个模型能在单个CPU上运算,那最省事了,但CPU的计算能力有限...……更多
2023-01-11 05:00:00清华,院士,高性能,人工智能,模型,智能

... 3D convolution)为主要模型组件,移除了自编码器中常用的注意力模块,使得模型具备不同分辨率迁移使用的能力。同时,在时间维度上因果卷积的形式也使得模型具备视频编解码具备从前向后的序列独立性,便于通过微调的方式...……更多
2024-07-27 09:30:00亦庄,甲子,生成,模型,视频,模型

...因为当前最佳的基于 Transformer 的 LLM 既深又宽,并且计算注意力的成本会随 prompt 中 token 数量而呈二次增长。举个例子,Llama 2(7B 版本)堆叠了 32 层 Transformer,模型维度为 4096。在这种情况下,TTFT 需要的 walltime 是……更多
2024-08-05 09:35:00准确度,更快,模型,苹果,缓存,模型

...Llama3-8B中,占端到端延迟80%的两个主要操作是矩阵乘法和注意力内核,而且它们依旧由CUDA内核操作。为了进一步提升性能,我们开始手写Triton内核来替换上述两个操作。手写Triton内核矩阵乘法对于线性层中的矩阵乘法,编写一...……更多
2024-09-07 09:48:00新时代,推理,内核,矩阵,乘法,英伟

...寸变化,正在重走CNN的老路!看到大家都被LLaMA 3.1吸引了注意力,贾扬清发出如此感慨。拿大模型尺寸的发展,和CNN的发展作对比,就能发现一个明显的趋势和现象:在ImageNet时代,研究人员和技术从业者见证了参数规模的快速...……更多
2024-08-02 09:47:00特斯,马斯,马斯克,扬清,特斯拉,老路

...窄3)重新使用编码共享(embedding sharing)方法4)使用组查询注意力机制(grouped query attention)在此基础上,作者还提出了一种块间层共享(block-wise layer-sharing)方法,能够在不引入额外内存开销的情况下进一步提高模型准确率,但..……更多
2024-07-23 09:39:00模型,性能,移动,模型,参数,架构
更多关于科技的资讯:
从乡村直播间的农特产品,到城市商场的促销热潮,再到物流行业的高效运转……记者从太原市税务局获悉,随着“双11”将下半年消费市场带入旺季
2025-11-21 08:12:00

近日,以 “量子计算+AI:重塑金融科技新范式” 为主题的前沿科技研讨会在北京召开,本次研讨会由天阳宏业科技股份有限公司(以下简称 “天阳科技”)主办
2025-11-21 08:29:00

向智而行,新型工业化加速跑——河钢集团唐钢公司构建全流程一体化生产计划排程系统,实现订单与产能高效匹配;石家庄四药集团应用生产执行系统
2025-11-21 08:36:00
“看见”,是新闻工作的起点。守护新闻工作者的清晰视野,就是守护社会公器的明亮窗口。11月18日,在厦门市新闻工作者协会指导下
2025-11-21 09:40:00

网易 UU 远程全新版本上线,在已有 Mac 控制 PC 功能的基础上,正式开放 Mac 设备被控功能,自此 Mac 实现控制与被控的双向协作
2025-11-21 09:47:00
中新经纬11月21日电 “小米公司发言人”微博21日发布关于Xiaomi Watch S4 Sport潜水功能的说明。小米公司表示
2025-11-21 11:11:00

第30届联合国气候变化大会(COP30)于11月10日至21日在巴西帕拉州首府贝伦市举办,这是2015年《巴黎协定》签署以来最受瞩目的气候大会
2025-11-21 11:36:00

11月18日,数绘星云(深圳)科技有限责任公司与腾讯云正式签订战略合作协议,双方将在云计算、大数据、AIGC等核心领域开展深度合作
2025-11-21 11:48:00
中新经纬11月21日电 据彭博社报道,当地时间20日,谷歌宣布了一款名为Nano Banana Pro的新型图像生成和编辑模型
2025-11-21 11:53:00
回望“十四五”,西安交通大学方涛教授说,他们团队倍感振奋。“在国家能源结构转型关键期,我们扎根国家‘双碳’战略,依托西安交大强大科研平台
2025-11-21 13:29:00
舒朗秋11月19日,工业和信息化部举行新闻发布会,介绍GB6675《玩具安全》系列强制性国家标准修订情况。据介绍,我国建成了全球最为完善的玩具产业链
2025-11-21 14:19:00

20日,2025世界计算大会在湖南长沙开幕。大会发布了2025全球计算十大创新成就及2026十大发展趋势。此次发布的全球计算十大创新成就包括
2025-11-21 15:35:00

2025年11月1日-2日,为期两天一夜的首届雨大王大健康私域IP创业峰会在深圳成功举办。本次峰会以"系统创业,自由人生"为主题
2025-11-21 15:41:00

随着人工智能技术加速重塑千行百业,以AI智能体为代表的AI技术正成为推动产业智能化转型的核心引擎。在保险行业,伴随数字化进程的深入推进
2025-11-21 15:42:00