- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

AI生成的图像太逼真,为什么不能拿来训练AI呢?可别说,现在还真有人这么做了。来自香港大学、牛津大学和字节跳动的几名研究人员,决定尝试一下能否使用高质量AI合成图片,来提升图像分类模型的性能。为了避免AI合成的...……更多
2023-02-23 12:53:00训练,数据,数据,训练,模型,图像

...绘画侵权,实锤了!最新研究表明,扩散模型会牢牢记住训练集中的样本,并在生成时“依葫芦画瓢”。也就是说,像StableDiffusion生成的AI画作里,每一笔背后都可能隐藏着一次侵权事件。不仅如此,经过研究对比,扩散模型从...……更多
2023-02-03 22:00:00绘画,侵权,模型,照片,模型,训练

...倍的模型相比具有显著竞争力。研究人员使用分类目标预训练的视觉变换器(ViT)模型与对比性预训练的模型(SigLIP)进行了比较,结果发现,PaLI-3 虽然在标准图像分类基准上略微表现不佳,但基于 SigLIP 的 PaLI 在各种多模态基...……更多
2023-10-17 16:31:00更快,模型,视觉,语言,训练,模型
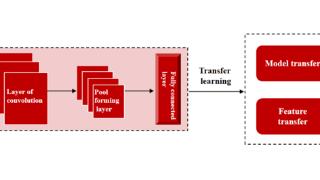
...。然而,由于语义分割任务的复杂性和数据的不足,单独训练一个语义分割模型可能会面临一些挑战,例如模型过拟合、模型泛化能力不足等。为了解决这些问题,微美全息(NASDAQ:WIMI)将迁移学习引入到语义分割模型中。迁移学...……更多
2023-11-15 01:02:00语义,全息,高质量,模型,任务,学习

...因为黑客可能会未经授权地利用图像-文本数据进行模型训练,其中可能包括个人和隐私敏感信息。最近的工作提出通过向训练图像添加难以察觉的扰动来生成不可学习样本(Unlearnable Examples),可以建立带有保护的捷径.然而,...……更多
2024-08-02 09:55:00误差,中科院,隐私,方法,数据,学习

只用1890美元、3700 万张图像,就能训练一个还不错的扩散模型。现阶段,视觉生成模型擅长创建逼真的视觉内容,然而从头开始训练这些模型的成本和工作量仍然很高。比如 Stable Diffusion 2.1 花费了 200000 个 A100 GPU 小时。即使研...……更多
2024-07-30 09:37:00从头,模型,训练,参数,掩蔽,训练

...上做出大突破。与DALL・E一样,两点依旧是CLIP模型,除了训练数据庞大,CLIP基于Transformer对图像块建模,并采用对比学习训练,最终帮助DALL・E2取得了不错的生成效果。下图是DALL・E2根据“一只戴着贝雷帽、穿黑色高领毛衣的柴...……更多
2023-01-30 16:34:00生成,模型,新论,代表作,盘点,进展

...,构建了图像分类融合模型,通过利用在大规模数据集上训练的模型的特征表示来提升小样本数据集上的分类性能。深度迁移学习可将已经在大规模数据集上训练好的深度学习模型应用于新的任务中。在图像分类中,深度迁移学...……更多
2023-10-23 16:02:00图像,分类,全息,深度,模型,准确性

...理的全新模型架构。具体来说,为了支持图像输入,Meta 训练了一组适应器权重(adapter weight),其可将预训练的图像编码器集成到预训练的语言模型中。该适应器由一系列交叉注意层组成,这些层的作用是将图像编码器表征馈...……更多
2024-09-27 13:42:00推理,可在,图像,运行,版本,支持

...ohnSchulman在接受科技播客主持人DwarkeshPatel采访时透露,后训练是提高模型性能的关键因素。GPT-4o的识图能力有多牛?四大维度深度体验基于图片类型,记者将识图功能的测评分为4大维度,分别为普通图像、特定专业领域的图像...……更多
2024-05-19 14:21:00维度,深度,能力,体验,模型,训练

...与文本指令进行视频生成,并有效利用公开视频数据进行训练。首先,团队采用广泛使用的2D UNet作为扩散模型,该模型由一系列空间下采样层和一系列空间上采样层构建,并插入了跳跃连接。具体来说,它由两个基本模块构建...……更多
2024-09-26 13:41:00字节,火爆,再次,小时,论文,指令

...员,利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。训练一个扩散模型要多少钱?之前最便宜的方法(Wuerstchen)用了28400美元,而像Stable Diffusion这样的模型还要再贵一个数量级。大模型时代,一般...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练

...增强方法由于其缓解过拟合的特性,而被广泛使用在模型训练过程中,例如图像的旋转、缩放、颜色的改变等等。然而,美国东北大学三年级博士生张一天和所在团队发现作为图像色彩的一个重要属性,色调(Hue)的变化却在现...……更多
2024-05-07 10:12:00东北大学,视频,美国,模型,方法,数据

...的数据收集,实现一条通过由生成模型加持的物理仿真来训练机器人视觉的技术路线。随着机器人在训练过程中持续进化,进一步提升技能所需的数据也在增长。因此获取足够的数据对于提升机器人的性能至关重要,但在当前实...……更多
2024-11-19 09:50:00从未,现实,机器,训练,环境,数据

...11B和90B型打造了一个全新的模型架构。在图像输入方面,训练了一组适配器权重,将预训练的图像编码器集成到预训练的大语言模型中。具体来说,该适配器:由一系列交叉注意力层组成,负责将图像编码器的表示输入进大语言...……更多
2024-09-27 13:39:00模态,宝宝,模型,图像,训练,文本

...新步伐基于腾讯混元的开源模型,开发者及企业无需从头训练,即可直接用于推理,并可基于腾讯混元系列打造专属应用及服务,能够节约大量人力及算力。同时,各大模型研发团队均可基于腾讯混元模型进行研究与创新,加速...……更多
2024-12-04 09:48:00文生,腾讯,模型,参数,社区,视频

...处于混乱状态,开源模型在选择LLM主干、视觉编码器以及训练数据方面都存在差异,性能优异的闭源多模态大模型也没有公布相关信息,无法直接进行模型对比和研究。并且,不同模型在处理高分辨率图像输入时的设计(如动态...……更多
2024-09-24 13:36:00英伟,模态,文本,性能,模态,模型

...人工智能实验室 (SVAIL) 系统团队。他们探讨了深度学习中训练集大小、计算规模和模型精度之间的关系,并且通过大规模实证研究揭示了深度学习泛化误差和模型大小的缩放规律,还在图像和音频上进行了测试。只不过他们使用...……更多
2024-11-28 09:57:00模型,训练,数据,大小,研究,误差

...模拟视觉相似物体和小物体,并且通过在较长的帧序列上训练模型并对「空间」和「物体指向记忆」(object pointer memory)的位置编码进行一些调整,提高了SAM 2的遮挡处理能力(occlusion handling capability)。研究人员还开源了SAM 2开...……更多
2024-11-28 12:02:00一文,大礼包,大礼,安全性,语音,图像

...消息,Google 的 AI 研究实验室Google DeepMind 发布了一项关于训练 AI 模型的新研究,Google 声称,该研究将大大提高训练速度和能效,比其他方法的性能高出 13 倍,能效高出 10 倍。随着有关 AI 数据中心对环境影响的讨论日益升温,...……更多
2024-07-11 09:47:00赛道,训练,方法,数据,模型,学习

...破了 200+ stars!值得注意的是, LLM2CLIP 可以让完全用英文训练的 CLIP 模型,在中文检索任务中超越中文 CLIP。此外,LLM2CLIP 也能够在多模态大模型(如 LLaVA)的训练中显著提升复杂视觉推理的表现。代码与模型均已公开,欢迎访...……更多
2024-11-28 09:59:00模态,教会,文本,升级,数据,模态

...提示LLM生成能解释答案的「原理」(rationale),以便用于训练模型,起到类似于CoT的作用。整个构建过程的流水线如下图所示:这种「以代码为中心」的方式不仅更容易保证图像的细节、质量和多样性,也让LLM更容易生成相关文...……更多
2024-08-08 16:23:00模态,领衔,基准,推理,视觉,能力

...s & Insights from Multimodal LLM Pre-training》(MM1: 多模式LLM预训练的方法、分析和见解)中可以看到,MM1是一个图文的多模态大模型,参数规模有30亿、70亿、300亿三种大小,有图像识别和自然语言推理能力。其中,参与该论文的作...……更多
2024-03-16 18:14:00模型,苹果,参数,焦点,分析,公司

...化学习智能体,在一个由扩散模型构建的虚拟世界中进行训练,能够以更高效率学习和掌握各种任务。在Atari 100k基准测试中,DIAMOND的平均得分超越了人类玩家,证明了其在模拟复杂环境中处理细节和进行决策的能力。环境生成...……更多
2024-11-19 09:49:00模型,训练,小时,学习,世界,模型

...法利用扩散 Transformer 进行视频运动迁移ObjCtrl-2.5D:无需训练的「图生视频」目标控制方法Moxin-7B:一个完全开源的大语言模型微软研究院:创建多用途、高质量 3D 资产智源推出视觉条件多视角扩散模型Turbo3D:超快速文本到 3D 生...……更多
2024-12-13 09:19:00推理,模型,思维,空间,模型,生成

...进行联合建模的大语言模型组成。输入将图像输入经过预训练的视觉编码器 CLIP-ViT-L/14 ,以提取图像嵌入 Z ∈ R H×W×C。对于文本输入,使用经过预训练的大模型标记器对文本序列进行标记,并将其投射至文本嵌入 T ∈ R L×D 当中...……更多
2023-12-26 14:06:00模型,生态,模态,零碎,苹果,模型

...rtexAI的开发人员和企业客户。Google通常不会透露太多用于训练人工智能模型的数据来源,这次也不例外。这是有原因的。大部分训练数据来自网络上的公共网站、资源库和数据集。而其中的一些训练数据,特别是未经内容创作者...……更多
2024-05-16 11:05:00生成,图像,技术,人工智能,数据,模型

...天拥挤的车道、马路上奔跑的狗等,生成写实的Corner Case训练数据,进而训练自动驾驶系统对Corner Case场景的感知能力上限。
“书生2.5”还可根据文本快速检索出视觉内容。例如,可在相册中返回文本所指定的相关图像,或是在...……更多
2023-03-15 13:30:00商汤,模态,书生,模型,任务,社区

...方式。而在时间差方面,「Tiamat」从2021年开始进行模型训练,以自研并自主训练底层模型的方式,始终与海外技术节点、开源社区等保持着同频。“我们拼命地想告诉大家,这件事情很快就会成为风口。”「Tiamat」创始人青柑...……更多
2023-02-28 09:33:00可控性,极致,融资,生成,图像,模型

...机系获得博士学位,在加速推理、可控生成、基础架构、训练策略等方面已发表十余篇顶会论文。首席科学家为清华大学计算机系人工智能实验室主任、智源研究院首席科学家朱军。可以说,2023年是国内大语言模型狂飙的元年...……更多
2024-03-14 15:12:00清华,班底,中国,架构,训练,公司
更多关于科技的资讯:

当承载着“国之重器”的核导弹方阵在阅兵式上巍然驶过,中国的科技实力与国防实力以庄严姿态展现于世界。在震撼之外,“核”所蕴含的巨大能量
2025-09-29 13:11:00
中新经纬9月29日电 题:备战“十一”消费高峰,平台用AI重塑购物逻辑作者 盘和林 工信部信息通信经济专家委员会委员“十一”长假将至
2025-09-29 13:13:00

鲁网9月29日讯在山东聊城市茌平区洪官屯镇的土地上,山东泊西实业集团有限公司正以蓬勃之姿,书写着海外出口的精彩篇章。走进泊西集团的生产车间
2025-09-29 12:07:00


近年来,伴随区域化、特色化产品的迅速增长,各大品牌在深耕主业的同时也开始积极探索新赛道、新领域。乌江榨菜作为涪陵榨菜集团旗下的核心品牌
2025-09-29 08:03:00

[北京] – 继中国首家多美卡品牌专卖店入驻玩具反斗城上海南丰城店并成功引爆小车收藏热潮后,玩具反斗城(Toys“R”Us)与多美(TAKARA TOMY)的战略合作再结硕果
2025-09-29 07:33:00
南报网讯(记者张甜甜)10月2日至3日,由南京报业传媒集团旗下南报优选供应链公司主办的首届紫金山国潮漫文化嘉年华,将在南京国际展览中心举办
2025-09-29 07:42:00

9月23日,长春航空展圆满闭幕,“净月号”凭借其震撼的实体造型与深厚的文化内涵,成为展会瞩目的焦点。这艘承载中式太空梦想的“星舰”
2025-09-28 10:07:00
为更好的服务广大客户,富德生命人寿安平支公司积极组织员工开展《产品健康增值服务》培训。培训中,讲师细致讲解公司产品健康增值服务
2025-09-28 10:12:00
河北新闻网讯(王丽英)9月24日至25日,宁晋县晶龙集团举行人力资源专业培训,内训师靳桂峰、王素峰和张晓宁分别围绕工伤保险及识人辨人
2025-09-28 10:18:00

当地时间9月27日上午11点,美团旗下国际外卖品牌Keeta正式在阿联酋迪拜启动运营,这是Keeta继8月上线卡塔尔、9月上线科威特后
2025-09-28 10:22:00

9月27日上午10点,小米17系列开售,价格4499元起!并全系首发第五代骁龙 8 至尊版。据悉,小米17尺寸6.3,7000mAh 电池
2025-09-28 10:22:00
齐鲁晚报·齐鲁壹点 王会广 通讯员 李杰在数字经济蓬勃发展的当下,大数据、云计算、物联网、移动互联网、人工智能以及区块链等新兴技术的广泛应用
2025-09-28 10:56:00

在直播与正片并行制作逐渐成为综艺内容生产新常态的当下,真人秀现场对影像系统的要求不断提升:既要满足直播的即时输出,又要兼顾正片制作的高质量成片
2025-09-28 11:51:00