- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
IT之家 12 月 18 日消息,谷歌 DeepMind 团队于 12 月 17 日发布博文,宣布推出 FACTS Grounding 基准测试,评估大型语言模型(LLMs)根据给定材料是否准确作答,并避免“幻觉”(即捏造信息)的能力,从而提升 LLMs 的事实准确性,增...……更多
2024-12-19 09:32:00照妖镜,基准,幻觉,模型,语言,示例

...3D场景理解中的鲁棒性和泛化能力,在多个3D多模态学习基准测试中取得了优异的性能,超越了以往的方法,且无需针对特定任务的微调。多模态大语言模型(Multi-modal Large Language Models, MLLMs)以文本模态为基础,将其它各种模态...……更多
2024-10-16 13:35:00模型,场景,训练,语言,数据,物体

...的研究人员联合撰写百页长文,发布名为MultiTrust的综合基准,首次从多个维度和视角全面评估了主流多模态大模型的可信度,展示了其中多个潜在安全风险,启发多模态大模型的下一步发展。论文标题:Benchmarking Trustworthiness of ...……更多
2024-07-25 09:31:00模态,清华,可信度,领衔,可信,几何

...评估 SELF-GUIDE 的有效性,研究者从 Super-NaturalInstructions V2 基准中选择了 14 个分类任务和 8 个生成任务。研究者随机选择了一半任务用于超参数搜索,剩余的一半用于评估。在模型方面,研究者选择了 Vicuna-7b-1.5 作为输入生成、...……更多
2024-08-02 09:40:00清华,性能,任务,数据,学习,生成

...。
该团队通过实验表明,RBR 得到的安全性能与人类反馈基准相当,同时还能大幅减少拒绝安全提示词的情况。
研究表明 RBR 适用于多种奖励模型,既能改善过度谨慎的奖励模型,也能改进(有时候)偏好不安全输出的奖励模型...……更多
2024-11-07 09:54:00定律,机器人,模型,规则,机器,安全

...是在推广自家产品。这位网友进一步质疑道:「当脱离了基准测试里的简单任务,需要做比较复杂的查询时,不会所有 AI 工具都失效了吧。」评论区也有很多工作中常用 SQL 的网友与他有同感:「AI 会写 SQL 与能写高效且性能优...……更多
2024-08-28 09:43:00编程语言,编程,语言,网友,数据,模型

...动评分器 ( FLAMe-RM 和 FLAMe-Opt-RM)。在12个自动评分器评估基准中的8个基准上,FLAMe及其变体的自动评分性能优于用专有数据训练的GPT-4o、Gemini-1.5-Pro等模型。- 计算高效的多任务训练:引入了一种计算更为高效的方法,使用创新...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...的输出。- 提高精度并处理边缘情况:微调可以用于纠正幻觉或错误,这些错误很难通过prompt和上下文学习来纠正。它还可以增强模型执行新技能或任务的能力,这些技能或任务很难在提示中表达。这个过程可以帮助纠正模型没...……更多
2024-08-27 12:03:00小白,长文,千字,基础,指南,训练

...
支持多种开、闭源对齐评估:支持了 30 多个多模态评测基准,包括如 MMBench、VideoMME 等多模态理解评测,以及如 FID、HPSv2 等多模态生成评测训练框架北大对齐小组设计了高度模块化、扩展性以及简单易用的对齐训练框架,支持...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。近日,淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,具有“中文、多样性、高质量、静态、易于评估”五...……更多
2024-11-22 09:51:00豆包,中文,真实性,评估,模型,中文

...究了大型语言模型在回答晦涩难懂和有争议问题时产生「幻觉」的原因,发现模型输出的准确性高度依赖于训练数据的质量和数量。研究结果指出,大模型在处理有广泛共识的问题时表现较好,但在面对争议性或信息不足的主题...……更多
2024-10-26 09:51:00哈佛大学,哈佛,等价,共识,幻觉,输出

【新智元导读】大模型幻觉,究竟是怎么来的?谷歌、苹果等机构研究人员发现,大模型知道的远比表现的要多。它们能够在内部编码正确答案,却依旧输出了错误内容。到现在为止,我们仍旧对大模型「幻觉」如何、为何产...……更多
2024-11-11 13:32:00幻觉,内幕,背后,错误,苹果,秘密

谁是在线购物领域最强大模型?也有评测基准了。基于真实在线购物数据,电商巨头亚马逊终于“亮剑”——联合香港科技大学、圣母大学构建了一个大规模、多任务评测基准Shopping MMLU,用以评估大语言模型在在线购物领域的...……更多
2024-11-21 09:45:00在线购物,基准,模型,任务,购物,数据

...的测评结果:Mistral Large 2性能具体如何,来看官方发布的基准测试结果。不到三分之一参数比肩Llama 3.1根据官方Blog,Mistral Large 2参数123B,专为单节点推理设计,在单节点上可实现大吞吐,上下文窗口为128k。代码能力方面,Mistra...……更多
2024-07-26 09:39:00模型,参数,模型,基准,问题,推理
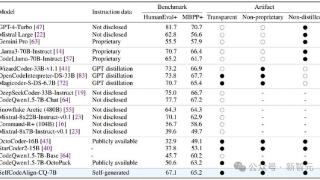
...,超过了参数量大10倍的CodeLlama-70B-Instruct。在全部的三项基准测试(代码生成、数据科学编程、代码编辑)中,SelfCodeAlign都战胜了之前最先进的指令微调方法OctoPack。此外,在HumanEval+上,SelfCodeAlign的性能超越了基于GPT-3.5……更多
2024-11-29 09:26:00伯克,伯克利,进化,模型,代码,方法

...。为了方便自动化评估,团队还一道推出了全新的大规模基准ScholarQABench,覆盖了CS、生物、物理等多个学科,用于评价模型在引用准确性、涵盖度和质量的等方面的表现。由UWNLP和Ai2两大顶流机构联手,OpenScholar在开源方面几乎...……更多
2024-11-27 13:33:00神器,文献,效率,科研,学术,模型

...法全面超越了MMQ和VQAMix这两个先进的医学VQA模型。表4 与基准模型的结果对比总结与讨论为了促进多模态大型语言模型在医学研究中的发展,作者对之前使用传统基于规则方法工作进行了延伸。利用基于LLM的方法,作者创建了一...……更多
2024-08-10 09:47:00德州,问答,视觉,医学,联合,数据

...在多语言和多轮对话任务中表现出的性能不俗。它在许多基准测试中拥有较为先进的水平,并在长上下文代码理解任务中以明显优势超过了其它模型(Llama-3.1-8B-instruct和Mistral-7B-instruct)。▲Phi-3.5-mini-instruct在长上下文代码理解...……更多
2024-08-22 09:49:00上下文,微软,架构,模型,上下,性能

...更加符合预期的结果。整体来看,缺乏交互式数据分析的基准——是本次研究面临的最大问题之一。为了解决这一问题,他们以“斯坦福小镇”项目为启发,创建了“DECISION COMPANY”。“DECISION COMPANY”是数据分析领域的首个多代...……更多
2024-04-07 10:50:00立新,数据分析,基准,科学家,模型,评估

...方法,结果显示语义熵方法在检测编造方面显著优于其他基准方法。那么“语义熵”究竟是什么呢?抛开冗长的专业解释,我们可以将语义熵简单理解为概率统计的一种指标,用来测量一段答案中的信息是否一致。如果熵值较低...……更多
2024-07-01 11:40:00牛津大学,八道,牛津,怎么办,方法,开发

...参数的 LLM 原型 ——Grok-0。这个早期模型在标准 LM 测试基准上接近 LLaMA 2 (70B) 的能力,但只使用了一半的训练资源。之后,他们对模型的推理和编码能力进行了重大改进,最终开发出了 Grok-1,这是一款功能更为强大的 SOTA 语...……更多
2024-03-18 11:51:00马斯,马斯克,权重,架构,模型,参数
...的交互(具身智能),通过交互在不同专业和科学的测试基准上表现出人类水平的智能。而针对幻觉,大模型有时会生成看似合理的编造或无意义的答案。在工作替代性方面,张钹表示,人工智能有助于推动经济增长,建筑、维...……更多
2024-03-21 09:57:00人工智能,人工,可能性,模型,理论,智能

...多种操作技能。在实验中,RoboMamba 在通用和机器人评估基准上展示了出色的推理能力,如图 2 所示。同时,我们的模型在模拟和现实世界实验中展示了令人印象深刻的操纵位姿预测能力,其推理速度比现有的机器人 MLLMs 快 7 倍...……更多
2024-06-21 09:52:00机器,模态,人多,机器人,推理,北大

...一款名为 MMed-Llama 3 的全新基座模型,以 8B 的尺寸在多项基准测试中超越了现有的开源模型,更加适合通过医学指令微调,适配到各种医学场景。
所有数据和代码、模型均已开源。MMedBench 上的准确率,图 d 展⽰了在 MMedC 上进...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...的视频 LMM——LLaVA-Video。实验表明,LLaVA-Video 在多个视频基准上表现出色,展示了该数据集的有效性。
论文标题:VIDEO INSTRUCTION TUNING WITH SYNTHETIC DATA
论文链接:https://arxiv……更多
2024-10-22 09:54:00模态,大功,瓶颈,模型,突破,项目

...理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。无论是语言模型还是视觉模型,似乎都很难完成更抽象层次上的理解和推理任务。语言模型已经可以写诗写小说了,但是依旧算...……更多
2024-08-08 16:23:00模态,领衔,基准,推理,视觉,能力
...估多达 500 个日常对话并获取相关指标:整体质量得分、幻觉率、AI 违规、连贯性、风格等。自动评估工作目前仍在进行中。如果没有自动评估,工程师只能目测结果并在一组有限的示例上进行测试,并且要延迟 1 天以上才能了...……更多
2024-08-07 09:33:00错误率,落地,错误,经验,应用,智能

...,基于技能的方法在GSM8K数据集上的表现,优于CoT和随机基准方法,并强调了准确技能分配、相关上下文示例在有效问题解决中重要性。此外,基于技能方法与自洽性,带来了更好的性能。对于SC实验,研究人员从LLM中采样5个推...……更多
2024-09-23 09:50:00新作,群体,性能,数学,机构,智能

...越重要。百融云创参加的这场“考试”名叫检索增强生成基准测评,这是对大模型处理“幻觉问题”的能力测评,也是对大模型生成内容准确性的测评。尽管大模型带来令人兴奋的技术进步,但“幻觉”一直是制约其发展的主要...……更多
2024-03-28 16:16:00精度,幻觉,模型,结果,模型,幻觉

...过不断增加上下文长度(干扰图片的数量),将现有的VQA基准和简单图像识别集 (MNIST) 扩展为测试长上下文「提取推理」的示例。结果在简单VQA任务上,VLM的性能呈现出惊人的指数衰减。——LLM:原形毕露了家人们。而与实际研...……更多
2024-07-23 17:12:00正确率,长上,下文,模型,只是,能力
更多关于科技的资讯:

快科技4月26日消息,努比亚官微今天宣布,Z70S Ultra摄影师版支持无网实时通话,无惧信号盲区。其实之前的努比亚Z70 Ultra就已经搭载了了双向卫星通信
2025-04-26 10:03:00
科沃斯2024年实现营业收入165.52亿元,同比增长6.71% 2025年4月25日晚间,科沃斯(603486.SH)发布2024年年报和2025年一季报
2025-04-26 10:10:00

快科技4月26日消息,随着鸿蒙智行尊界S800内饰官图的释放,有海外媒体也关注到了这款超豪华豪车,今日,汽车媒体“Carscoops”发布了名为《华为新款超豪华轿车足以与劳斯莱斯一较高下》的文章
2025-04-26 10:33:00

快科技4月26日消息,据国内媒体报道称,工业和信息化部相关负责人昨天在广西南宁举行的“光华杯”千兆光网应用创新大赛上透露
2025-04-26 10:33:00

4月26日消息,近日,“4月26日14时58分,东京湾北部将发生8.3级地震,且会引发30米海啸”这一消息在网上疯传,让很多人感到不安
2025-04-26 10:33:00

天猫【罗蒙羽绒服旗舰店】罗蒙直筒休闲裤日常售价为 309 元,下单 2 件,领取 467 元优惠券,立减 62 元,到手价为 89 元
2025-04-26 11:03:00
快科技4月26日消息,近日,一则令人咋舌的消息引发关注。有媒体在社交平台发布视频,曝光了北京市朝阳区六里屯一位70多岁退休大妈偷快递的荒唐行径
2025-04-26 11:03:00

快科技4月26日消息,REDMI今天公布了Turbo 4 Pro首销战绩,打破2025纪录,获得全价位段首销销量第一。卢伟冰表示
2025-04-26 11:03:00
快科技4月26日消息,近日,第15届北京国际电影节天坛奖国际评委会主席姜文现身“电影大师班”。活动开始前一小时,所有座位已经被影迷们坐满
2025-04-26 11:33:00

天猫【颐莲旗舰店】颐莲 玻尿酸喷雾 300ml*2 瓶标价 200 元,今日立减 20 元,下单领取 100 元大额券 + 20 元品类券
2025-04-26 11:33:00

上海车展,其实也没那么糟。上次我们盘了上海车展的主办方闹剧(传送门)。一开始两个官网、两个公众号的操作,搞得车企和观众一头雾水
2025-04-26 07:33:00

快科技4月26日消息,日前,饿了么平台与骑手代表正式签署《2025年度“饿了么”(上海)网约配送算法和劳动规则协议》。这是全国首份围绕平台算法与劳动者权益达成的专项协议
2025-04-26 08:03:00
近日,杭州市生态环境科学研究院(以下简称“市环科院”)对杭州安防出口产品签发的第一份碳足迹陈述证明“首航出海”。这是杭州首个针对智能家居摄像机产品的碳足迹研究成果
2025-04-26 08:11:00

快科技4月26日消息,极核(ZEEHO)推出了一款全新的电动摩托车AE8 S+MY25,首发价23180元(原价23980元)
2025-04-26 08:33:00

快科技4月26日消息,国产存储厂商佰维官方宣布,其研发的真国产、全自研电力专用eMMC正式上市。据介绍,电力行业常年面临极端温差
2025-04-26 08:33:00