- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...这是该团队在继 PMC-LLaMA 后,在持续构建开源医疗语言大模型的最新进展。该项目受到科创 2030—“新一代人工智能” 重大项目支持。在医疗领域中,大语言模型已经有了广泛的研究。然而,这些进展主要依赖于英语的基座模型...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...简单任务的准确率可以达到60%,最难任务准确率仅有21%大模型的能力越来越强,用户在一些重要的任务中也可以依赖大模型,比如说辅助做科研。不过现有科研辅助相关的基准测试都太简单,跟现实世界的任务差距还是比较大的...……更多
2024-09-26 13:38:00普林,普林斯顿,斯顿,准确率,基准,科学家

...随着ChatGPT在法律、金融、营销等领域的广泛使用,确保模型的安全、准确输出同时被很好理解变得非常重要。但由于神经网络的复杂和多变性,我们根本无法验证其生成内容的准确性,这也就会出现输出“黑盒”的情况。为了...……更多
2024-07-18 09:47:00最新技术,难题,研究,技术,模型,小数

...,中间数据信息,已生成代码信息)会导致模型生成代码正确率下降,可以在未来考虑使用LLM进行总结,对信息进行筛选。b)同一个Task可进行进一步的分解,以降低对LLM推理能力的要求。2、对话交互式,可以将任务和任务的执...……更多
2024-08-08 09:40:00小白,阿里,科学家,流程,自动化,科研

...【新智元导读】剑桥大学研究利用人工智能建立机器学习模型精准预测阿尔茨海默症发展,准确率远超临床测试结果,为阿尔兹海默症早期干预开辟新路径。如果说人工智能可以在一个领域产生前所未有的积极影响,「医疗保健...……更多
2024-07-22 09:40:00阿尔茨海默,剑桥大学,阿尔,剑桥,准确率,临床

...此前,夸克“灵知”学习大模型在考研数学题等评测上的正确率和得分率已经可以比肩OpenAI的o1模型。夸克学习产品负责人程飞表示:“随着AI解题大师上线,夸克能帮助用户把难题讲解得更加准确和透彻,深度思考过程还能启...……更多
2025-03-18 11:49:00夸克,难题,深度,思维,大师,用户

...经常答不完卷子,或者说对题目明明有思路,但是速度和正确率无法兼得,就可以通过刷题来解决。对于一些特别典型的题目,他建议大家可以选择性地裁剪。平时多整理易错点,并用一两句话概括一下错误的原因,这样便于回...……更多
2024-05-27 12:23:00而行,北海,清华,领航,学子,博士

...最近一段时间,有关 AI 科学家的研究越来越多。大语言模型(LLM)有望帮助科学家检索、综合和总结文献,提升人们的工作效率,但在研究工作中使用仍然有很多限制。对于科研来说,事实性至关重要,而大模型会产生幻觉,...……更多
2024-09-13 13:33:00博士后,模型,科研,博士,检索,能力

...种“无效努力”不仅浪费计算资源,还显著降低了答案的正确率。“三心二意”是罪魁祸首这一现象在解决数学竞赛题等更为复杂任务时尤为明显。为了系统分析,团队在三个具有挑战性的测试集MATH500、GPQA Diamond和AIME2024上,对...……更多
2025-02-04 19:41:00弱点,模型,推理,答案,思路,准确率

...效果的影响。主要结论如下:多数情况下,自我纠错后的正确率高于原正确率(图4)
正确率提升与自我评估的准确率高度相关(图4(c):),甚至呈线性关系(图5(a))。
采用不同的评价方式效果依次提升:仅使用对/错评价 &...……更多
2024-11-19 09:48:00推理,北大,团队,解释,能力,理论

实验证明,大模型的 System 2 能力还有待开发。规划行动方案以实现所需状态的能力一直被认为是智能体的核心能力。随着大型语言模型(LLM)的出现,人们对 LLM 是否具有这种规划能力产生了极大的兴趣。最近,OpenAI 发布了 o1 ...……更多
2024-09-25 09:48:00饱和,规划,模型,测试,规划,能力

...爆炸!自动推理绝对算是自然语言处理领域的一大难题,模型需要根据给定的前提和知识推导出有效且正确的结论。尽管近年来NLP领域借着大规模预训练语言模型在各种「自然语言理解」如阅读理解和问答等任务中取得了极高的...……更多
2023-01-09 21:57:00自然语言,算法,推理,自然,语言,目标

新智元报道编辑:alan【新智元导读】当今的LLM已经号称能够支持百万级别的上下文长度,这对于模型的能力来说,意义重大。但近日的两项独立研究表明,它们可能只是在吹牛,LLM实际上并不能理解这么长的内容。大数字一向...……更多
2024-07-23 17:12:00正确率,长上,下文,模型,只是,能力

...准的实验与计算成果,由此发挥更大潜力;运用在大语言模型,可以有效利用大量现有知识,拓展人类局限的想象力……第五范式将带来革命性改变。鄂维南说,曾经,做科研的具体操作犹如“小农作坊”,而AI for science将推动...……更多
2023-11-08 06:44:00范式,关键,范式,科学,人类,科研

...在数据分析场景下的数据测试集(1000+题目)中以85.71%的正确率超过GPT-4。基于商汤“日日新”延伸出的代码模型能力微调,协同办公平台WPS365实现了场景优化和能力增强,可以内化WPS365多类场景的API能力,实现自然语言快速调...……更多
2024-04-12 15:11:00商汤,办公,补强,金山,办公软件,理科

...数据中提取有用信息。如今,他们只需输入问题,由语言模型驱动的底层系统会完成其余工作,让用户只需与数据对话即可立即获得答案。这些新系统向数据库提供自然语言交互,这种转变取得了丰硕成果,但仍存在一些问题。...……更多
2024-09-10 13:38:00自然语言,表格,生成,自然,语言,数据库

Llama 3.1 405B“最强模型”宝座还没捂热乎,就被砸场子了——Mistral AI发布最新模型Mistral Large 2,参数123B,用不到三分之一的参数量性能比肩Llama 3.1 405B,也不逊于GPT-4o、Claude 3 Opus等闭源模型。主打的就是一个高性价比。用官……更多
2024-07-26 09:39:00模型,参数,模型,基准,问题,推理
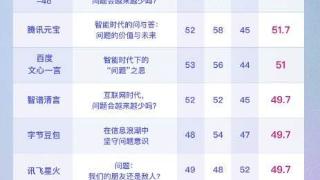
...科技的数学评测中,讯飞星火、文心一言、豆包均以63%的正确率位列第一梯队,智谱清言、阿里通义则以50%的正确率位居第二梯队,其他大模型相对落后。
在量子位的高考数学评测中,虽然没有给出详细成绩单,但展示了各家...……更多
2024-06-12 09:29:00星火,成绩单,模型,成绩,高考,综合

...AI于2023年底正式问世。这款财税领域的GPT以财税理论回答正确率高达92%的惊人成绩,率先占领了业内第一梯队。同时,小竹财税成功获得1000万元天使轮融资。据了解,小竹财税(安徽小竹信息技术有限公司)成立于2021年11月,...……更多
2024-03-14 13:30:00中国,模型,模型,领域,需求,正确率

...上,当p=0.1、0.2和0.3时,Pass@20度量的基线模型,其中绝对正确率增加到61.9%。最后,来看一下研究团队阵容。该研究由田渊栋等人带来。田渊栋现在是Meta FAIR的研究科学家主任,领导LLM推理、规划和决策小组。Qinqing Zheng是FAIR的...……更多
2024-10-18 09:51:00推箱子,快慢,迷宫,整合,团队,推理

几天前 OpenAI 新模型 o1 的发布,再次引发了人们对大语言模型的高度关注和讨论。而 o1 发布之所以如此“轰动”,是因为它与此前大模型由语言驱动用于聊天或语音助手有本质的不同。其不仅进入到复杂的领域,还表现出超强...……更多
2024-09-20 13:33:00模型,推理,思维,原理,核心,模型

【新智元导读】谷歌DeepMind推出LLM自动评估模型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。大语言模型都卷起来了,模型越做越大,token越来越多,输出越来越长。那么问题来了,如何有效地评估大...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据
...型的自学习、自完善、自更新,提高各料型自动判级综合正确率,为废钢采购全流程智能化验质提供技术保障。该公司根据现场需求,积极展开靶向技术攻关。权万红带领技术团队认真查看废钢定级系统中的车次分层拍照质检情...……更多
2023-11-09 18:47:00废钢,攻关,智能,技术,科技,废钢

...进行了验证。验证结果显示,如表3所示,问答对的平均正确率达到了94.8%。表3 数据集人工验证结果Baseline模型介绍基于构建的Medical-CXR-VQA数据集,作者提出了一种多模态图推理模型,如图3所示。针对拍摄胸部X光片时病人姿态变...……更多
2024-08-10 09:47:00德州,问答,视觉,医学,联合,数据

...到2020年末AlphaFold2的出现。AlphaFold2的三维蛋白质结构预测模型准确率超过90%,比最接近的竞争对手高出5倍。通过深度学习,人工智能近乎轻松地破解了“人力不可为”的难题,震撼了生物学界。近几年,AlphaFold2改变了生物学家...……更多
2024-10-10 13:38:00诺贝尔化学奖,诺贝,蛋白质,蛋白,贝克,结构

...能计算创新人物颁奖仪式”在北京举办,本次活动由北京清华工业开发研究院、之江实验室作为战略合作伙伴共同支持。出席本次活动的领导嘉宾包括了北京清华工业开发研究院副院长付小龙、之江实验室党委委员及副主任陈伟...……更多
2024-04-29 10:09:00麻省理工,麻省,峰会,中国,理工,人物
...ixabay撰文 | 张天祁● ● ●今年年初,DeepSeek发布DeepSeek-R1模型,引发全球的关注。在公开评测中,它的综合能力逼近当时的顶尖大模型,尤其在逻辑推理和数学题上展现出强劲性能,而且它的成本要远低于作比较的其他大模型。...……更多
2025-05-27 10:23:00里来,能力,模型,训练,推理,能力

...议,其中多篇文章获得相应会议的最佳论文奖。大型语言模型 (LLM) 在各种自然语言处理和推理任务中表现出卓越的能力,某些应用场景甚至超越了人类的表现。然而,这类模型在最基础的算术问题的表现上却不尽如人意。当...……更多
2024-10-21 09:54:00灵机,模型,训练,过程,语言,运算符

...题、增加候选选项、引入纯视觉输入设置)更严格地评估模型的多模态理解能力;模型在新基准上的性能下降明显,表明MMMU-Pro能有效避免模型依赖捷径和猜测策略的情况。多模态大型语言模型(MLLMs)在各个排行榜上展现的性...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本
...时间更长。而在2000年至2020年的总统选举回测中,猴子的正确率只有50.4%,一时竟分不清其与抛硬币,谁更准一点。更尴尬的是,当实验人员让猴子们看特朗普和哈里斯照片时,猴子们开始目光迷离,让观察人员摸不着头脑。好...……更多
2024-10-23 16:07:00神算,美国,人选,总统,知识,特朗普
更多关于科技的资讯:
在杭州城西科创大走廊东首的西湖区紫金港科技城云谷中心,国内最大模型开源社区“魔搭社区”的首个线下实体空间——魔搭社区(杭州)开发者中心(以下简称“开发者中心”)
2025-12-05 08:13:00
眼下,养宠群体逐渐壮大,带来的刚需消费、悦己消费持续升温、充满潜力,宠物经济迅速崛起。最近,省农业农村厅联合省发改委、省商务厅等五部门印发《关于促进宠物经济发展的意见》
2025-12-05 08:13:00
苏州作为全国数字经济、数字金融的先行城市,始终以敢为人先的魄力,争当保险科技应用的“试验场”与“示范区”。苏州市数字金融高质量发展大会保险科技专题活动在苏州人保财险成功举办
2025-12-05 10:56:00
近日,2025系统医学与健康大会在苏州工业园区举行,四大慢病国家科技重大专项技术总师陈竺,创新药物研发国家科技重大专项技术总师曹雪涛
2025-12-05 11:45:00

孙向辉解读《报告》。中青报·中青网记者 任明超/摄中国青年报客户端讯(李争艳 中青报·中青网记者 任明超)12月4日,《中国电影经济发展研究报告》(以下简称《报告》)在海南岛国际电影节主论坛首发
2025-12-05 11:50:00
近日,由市稳外贸专班主办,苏州市分公司、供应链数字治理研究中心、苏州世标检测有限公司共同承办的“新外贸‘涨’字诀:精通美国知产合规赋能企业竞强价增”活动
2025-12-05 11:54:00

AI时代“一人公司”迎来发展良机AI应用爆发前夜,中国第二经济大省江苏的“双子星”——南京、苏州抢先布局“单人成军”的OPC新形态OPC的全称是One Person Company
2025-12-05 12:11:00

大河网讯 蜜雪冰城诠释着国民饮品的亲切感,河南博物院文创产品让厚重历史走入百姓日常生活,力量钻石折射出河南制造闪耀的科技光芒……12月5日
2025-12-05 12:12:00

大河网讯(记者 刘高雅 王靖/文 杨鑫阳/图)12月5日,“供给焕新程 服务跃新阶——2025河南省新服务新供给品牌建设交流活动”在商丘市举行
2025-12-05 12:12:00
为提升团队惠民保展业能力,夯实业务根基,太湖人保财险成功开展新员工惠民保专项培训,各团队主管全程参与研讨推进,以多维度培训为全体坐席赋能
2025-12-05 12:40:00

大河网讯(记者 刘高雅 王靖/文 杨鑫阳/图)12月5日,“供给焕新程 服务跃新阶——2025河南省新服务新供给品牌建设交流活动”在商丘市举行
2025-12-05 13:13:00

大河网讯(记者 刘高雅 王靖/文 杨鑫阳/图)12月5日,“供给焕新程 服务跃新阶——2025河南省新服务新供给品牌建设交流活动”在商丘市举行
2025-12-05 13:13:00
在当前全球化格局深度调整与数字技术革命交汇的时代背景下,研究生国际联合培养模式的数字化转型,已成为国家教育战略的核心关切
2025-12-05 13:18:00