- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
...维”公司重磅发布了一个根据互联网视频训练的基础世界模型——Genie(精灵)。其可从合成图像、照片、草图生成多种动作可控的环境。 过去几年,生成式人工智能(AI)模型能通过语言、图像甚至视频生成内容。谷歌此次引...……更多
2024-02-29 07:19:00模型,基础,世界,生成,图像,环境

...,跌1.91%,总市值1.70万亿美元。就在本月初,谷歌为其AI模型Gemini推出了图像生成器工具,允许用户通过输入提示来创建图像。但在过去一周中,网友们发现,该工具似乎在有意避免生成包含白人的图像,并在图像中加入了过量...……更多
2024-02-29 15:37:00初期,生成,模型,图像,错误,生成

...品Gauss(高斯)。三星以科技创新优势为人工智能大语言模型领域的发展注入新的活力。2023三星人工智能论坛三星Gauss,人工智能重大进步代表在人工智能的不断发展和突破中,以大模型为代表的生成式人工智能技术凭借高速的...……更多
2023-11-27 17:02:00三星,下一代,模型,语言,智能,应用

...上了一步台阶,可以向公众发布以供广泛使用。以大语言模型(large language models,以下简称“LLM”)为基础的 text-to-X(文本到任意)技术再在2022年有了突破性进展,分别在 text- to-image(文本到图片)、AI-generated-text(AI 生成……更多
2023-01-05 09:26:00模型,生成,用户,技术,应用,图像

...智能(AI)巨头OpenAI又出王炸,其最新推出的文生视频大模型Sora因其“逼真”和“富有想象力”被广泛赞誉,其生成视频可达60秒也颠覆了传统视频生成领域平均只有4秒的视频生成长度。OpenAI官网介绍,Sora是一种扩散模型,它...……更多
2024-02-19 08:10:00颠覆,布局,行业,视频,公司,模型

10月9日消息,英国AI初创公司Wayve公布了旗下GAIA-1生成式模型的最新进展,在今年6月的时候,Wayve建立了将生成式模型用于自动驾驶的概念性验证,而在这几个月中,Wayve公司持续扩展GAIA-1,使其拥有90亿个参数,能够生成逼真的...……更多
2023-10-10 11:51:00英国,进展,公司,模型,驾驶,生成

...览本周AI领域涌现多项重要进展。Runway宣布开展通用世界模型研发,旨在通过研究通用世界模型改进其视频生成系统,使其更好地模拟现实世界的互动。谷歌Deepmind推出Imagen 2,一款高质量、逼真的人工智能图像生成器。Mistral AI...……更多
2023-12-17 18:40:00模型,硅谷,订阅,监督,模型,融资

...工智能在AI技术应用中成为焦点,尤其是文本生成视频大模型Sora,近来更是在全球范围内激发了科技创新的热潮。香港科技大学(广州)人工智能学领域助理教授兼博士生导师陈颖聪教授,作为计算机视觉与机器学习学域的资深...……更多
2024-03-14 05:26:00文生,驾驶,方向,视频,生成,三维

...。他在自然语言处理领域取得了显著成果,特别是在语言模型和对话系统方面。Zhu的工作使得机器能够更自然地与人类进行交互,提高了智能助手的性能和用户体验。RichardSutton,强化学习之父、阿尔伯塔大学教授。他对强化学...……更多
2024-03-24 08:39:00人工智能,美国,院士,科学院,人工,智能

...雨编辑 | 邓咏仪全球首家发布Sora同款底层架构的清华系模型公司,近期完成了新一轮融资。投资名单中,也出现了大模型独角兽智谱AI的身影。36氪获悉,近日多模态AI模型公司生数科技完成新一轮数亿元融资。该轮融资由启明...……更多
2024-03-14 15:12:00清华,班底,中国,架构,训练,公司

...整个ETF市场。投资逻辑方面,日前,谷歌发布了基础世界模型Genie,Genie是一个110亿参数的基础世界模型,可以通过单张图像提示生成可玩的交互式环境。只需一张图像就能创建全新的交互环境的AI技术,为生成和进入虚拟世界的...……更多
2024-03-16 23:35:00模态,涨幅,指数,影视,上市公司,动漫游戏

...凌晨,OpenAI再次扔出一枚深水炸弹,发布了首个文生视频模型Sora。据介绍,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。目前官网上已经更新了48个视频demo,在这...……更多
2024-02-16 18:44:00文生,奥尔,奥尔特曼,特曼,模型,提示

...性能和能效,以满足日益增长的算力需求,同时通过各种模型和算法优化工具,让模型、算法和移动芯片实现软硬件协同,提升端侧生成式AI的运行效率。与此同时,联发科还积极与AI生态伙伴开展密切合作,共同推动从芯片算...……更多
2024-02-27 21:30:00联发,展台,移动通信,突破,通信,移动

...频!美国开放人工智能研究中心(OpenAI)推出的视频生成模型Sora近日震惊全球。目前,Sora只发布了多个演示视频和技术指导,并对一些专家开放内测,但该模型尚未对公众开放注册。也就是说,普通人还无法体验到它的神奇。...……更多
2024-02-22 19:25:00韭菜,开放,视频,生成,模型,提示

...风格或纹理应用于文字和短语。Midjourney:Midjourney 的 V.5 模型在图像生成领域是一个重要的里程碑,它展示了在效率、连贯性和高分辨率方面的显著改进。最新的 alpha 版本,Midjourney V.6,引入了额外的增强功能,如更精准的提示...……更多
2023-12-29 05:02:00之年,人工智能,人工,智能,生成,人工智能

OpenAI周四发布了首个视频生成模型Sora,并展示了几段效果炸裂的演示视频。一位X用户分享了Sora生成的一名女子在东京街头漫步的视频,并评论称:“OpenAI今天宣布了Sora,它使用混合扩散和变压器模型架构生成长达1分钟的视频...……更多
2024-02-16 22:16:00马斯,马斯克,生成,模型,人类,视频
本文转自:中国科学报南开大学等让人工智能模型训练提速10倍以上本报讯(通讯员高雨桐 记者陈彬)南开大学、南开国际先进研究院(深圳福田)教授程明明团队发布了一项国际联合研究成果MDT,与人工智能文字生成视频大...……更多
2024-04-03 07:20:00人工智能,提速,人工,模型,训练,智能

...面。而就在2月16日,OpenAI宣布推出全新的生成式人工智能模型“Sora”。据了解,通过文本指令,Sora可以直接输出长达60秒的视频,并且包含高度细致的背景、复杂的多角度镜头,以及富有情感的多个角色。这意味着,继文本、...……更多
2024-02-18 23:32:00新纪元,生成,模型,创作,领域,内容

2月25日,据报道,谷歌公司的人工智能(AI)模型Gemini在生成人物图像时存在一些问题,用户反馈该模型无法准确地生成白人形象。尽管Gemini能够根据文字快速生成各种各样的人物形象,并且输入关键词“高兴的黑人”时也没有...……更多
2024-02-26 02:06:00人工智能,人工,生成,模型,图像,人物
...中国科学院院士、清华大学人工智能研究院院长张钹:大模型为建立通用人工智能理论提供可能性·GPT-4只能和数字世界打交道,我们最终必须跟物理世界打交道,这就需要机器人,也就是具身智能。·全世界对大模型强大的生成...……更多
2024-03-21 09:57:00人工智能,人工,可能性,模型,理论,智能

...Leonardo.ai官网功能方面,Leonardo.ai是基于Stable Diffusion开源模型建立,集成插件支持AI生图、改图、扩图和3D素材生成。因操作简单,界面友好,用户评价它是“简单版Stable Diffusion”,具有较高的性价比。Leonardo.ai精选模型(Fine……更多
2024-02-21 13:46:00生成,用户,图片,用户,生成,模型

...科学家们已经建立了一个框架,通过将它们浓缩到更小的模型中,在不影响质量的情况下,给像Dall·E3和Stable Diffusion这样的生成式人工智能系统带来了巨大的提振。一项新的研究表明,由于一项技术可以将整个100个阶段的过程浓...……更多
2024-03-27 13:42:00麻省理工,麻省,生成器,人工智能,提速,科学家

...AI工具的更多信息,IT之家整理如下。官方介绍称,EmuEdit模型仅用文字指令就可以准确编辑图像,而通过分解文字转视频(Text-to-Video,T2V)的生成过程,开发团队公布了一种名为EmuVideo的方法,可以改善最终生成视频的品质和多...……更多
2023-11-20 11:38:00图像编辑,图像,工具,生成,图像,模型

...被打破——OpenAI又出王炸,发布了可以生成60秒视频的AI模型Sora。OpenAI官宣Sora。同样在2月16日发布的谷歌最新多模态模型Gemini Pro 1.5,则被Sora迅速夺走了关注度。网友为Gemini和Sora制作的梗图。根据OpenAI官方发布的推文和技术报...……更多
2024-02-18 06:20:00生成,一口,空降,画质,模型,一口气

...。而这些视频全都是通过OpenAI2月15日发布的最新视频生成模型Sora制作的,用户震惊之余,也给予了Sora高度评价,将其描述为“绝无仅有”和“游戏规则改变者”。图片来源:X平台Sora采用了OpenAI文生图模型DALL-E3背后的强大技术...……更多
2024-02-17 21:07:00颠覆,核心,优势,报告,影视,行业
...性等方面具备惊人效果……近日,OpenAI发布的文生视频大模型Sora迅速引发人们关注。业内分析认为,该项新产品或将促使大模型厂商加大对多模态大模型的研发投入,并进一步推动AGI(通用人工智能)进程。一直以来,视频领...……更多
2024-02-26 08:58:00模态,行业应用,模型,进程,场景,应用

...行业,其制作流程繁琐,生产周期长,成本高昂。每个3D模型的创建成本至少需要数千元,而生成式AI技术在2D图像生成方面的成功为其在3D建模中的应用带来了新的可能性。2021年,OpenAI发布了DALL·E,通过输入文字prompt生成清晰...……更多
2023-12-21 12:30:00商汤,模型,生成,负责人,项目,时代
...集群。夯实发展新基底,努力做到数据可控、框架可控、模型可控。加快建设高质量中文数据资源库。要在不断完善国家数据基础制度基础上,推动典型行业数据汇集、访问、共享、处理和使用,着力盘活数据资源存量;加强数...……更多
2024-03-20 05:57:00赛道,经济发展,数字,发展,经济,数据

...有局限性,无法实现复杂的打斗场景。然而,短视频生成模型Sora的问世,让AI根据指令直接生成复杂逼真的动画成为可能。北京时间2月16日凌晨,Sora“横空出世”。这是OpenAI推出的一款能根据文字指令即时生成短视频的模型。Op...……更多
2024-03-02 10:00:00场景,不够,应用,生成,视频,模型

“同行们认为我们用大模型把音乐理解和生成结合在一起的想法比较新颖,论文也是多模态大模型领域的先期工作之一。并且,除了大模型本身,我们提出的针对模型训练的数据集制作流程和整理的数据集,对学术界也具有较...……更多
2024-04-09 10:25:00模态,音乐,科学家,生成,模型,创作
更多关于科技的资讯:

华为nova13系列即将闪亮登场!据悉,全系标配麒麟芯片,并支持旗舰级卫星通信技术,这次能否成为市场的焦点?华为nova12随着华为业务的全面复苏
2024-07-14 00:28:00

智能手机的耐摔性一直是消费者关注的重点之一,在早期,由于技术限制,智能手机普遍不具备出色的耐摔性能。这导致消费者在购买手机后
2024-07-14 01:21:00
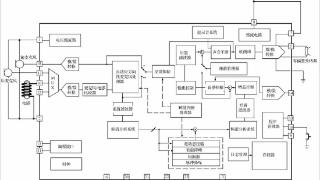
毋庸置疑,助听器最重要的零部件就是芯片,所有核心的信号处理算法如多通道宽动态范围压缩(WDRC)、智能降噪、自适应方向性以及自适应反馈抑制都是在这一块小小的芯片里完成运算的
2024-07-14 01:32:00

在科技日新月异的今天,荣耀即将推出的MagicPad2平板以其“AI赋能的PC级生产力”为核心卖点,正悄然引领着平板市场向更高效
2024-07-14 02:43:00
本文转自:人民日报本报记者 冯学知《 人民日报 》( 2024年07月14日 第 05 版)广东深圳,前海深港青年梦工场(以下简称“梦工场”)北区
2024-07-14 05:55:00
快科技7月13日消息,昨天下午,荣耀Magic V3系列正式发布,搭载全新荣耀视力舒缓绿洲护眼屏,开创性的引入AI主动式护眼技术
2024-07-13 19:44:00

快科技7月13日消息,谷歌将于8月13日推出Pixel 9系列新品,这次谷歌将同时发布Pixel 9、Pixel 9 Pro
2024-07-13 19:44:00

7月13日消息,真人影游《我为情狂》今日正式发售,首发折扣价61.20元。《我为情狂》是根据著名都市传说“三上悠亚结婚隐退事件”改编而成的互动影游
2024-07-13 19:44:00

7月13日消息,据媒体报道,2014年,沈腾、马丽主演的电影《夏洛特烦恼》杀青,这部电影于2015年9月上映。时隔10年
2024-07-13 20:14:00

快科技7月13日消息,盲人如何看电影,答案是加一个解说。今天沈腾、马丽领衔主演的电影《抓娃娃》点映,有些影院有一副专门的耳机
2024-07-13 20:44:00

7月13日消息,最新发布的全球移居目的地调查报告(Expat Insider 2024)显示,阿联酋是中东地区唯一一个跻身综合排名前十的国家
2024-07-13 21:14:00

快科技7月13日消息,在Bilibili World展会上,作为七彩虹原创IP桌宠,柒小希首次线下曝光。它是七彩虹中控软件iGame Center的智能桌面管家
2024-07-13 21:44:00

快科技7月13日消息,华为已经表示,自家乾崑智驾将首次出现在20万元以下汽车上,而这也引发了网友的热议。智能驾驶这个赛道上
2024-07-13 21:44:00

快科技7月13日消息,今天,有米粉问卢伟冰:Redmi K70至尊版总不至于是2799起吧?卢伟冰回复,调较给力,配置很猛
2024-07-13 21:44:00