- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
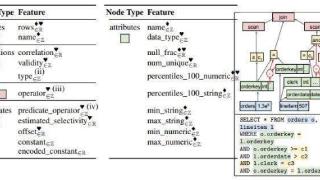
...要为学习型基数估计(cardinality estimation)满足系统评估框架需求。CardBench 基准是个综合评估框架,包含 20 个不同真实数据库中的数千次查询,大大超过了以往的任何基准。项目背景基数估计(cardinality estimation,简称 CE)是优...……更多
2024-09-04 09:48:00框架,评估,数据,模型,基准,查询

...讨了什么因素会影响大模型的安全。提出攻击分析系统性框架JailTrackBench。JailTrackBench研究重点分析了不同攻击配置对LLMs性能的影响,包括攻击者的能力、预算、对抗性后缀长度,以及模型的大小、安全对齐情况、系统提示和模...……更多
2024-11-01 09:29:00模型,基准,攻击,影响,安全,研究

...?来自Meta、KAUST团队的最新研究中,提出了Agent-as-a-Judge框架,证实了智能体系统能够以类人的方式评估。它不仅减少97%成本和时间,还提供丰富的中间反馈。AI智能体,能否像人类一样有效地评估其他AI智能体?对于AI智能体来...……更多
2024-10-28 09:52:00审判,新作,团队,成本,智能,评估

...有的数据、数据混合方法、配方、代码、基础设施和评估框架!模型:https://huggingface.co/allenai
技术报告:https://allenai.org/papers/tulu-3-report.pdf
数据集:https://huggingface……更多
2024-11-26 09:44:00模型,性能,训练,模型,训练,数据

...oTA」的时代,简单易用、标准透明、可复现的多模态评估框架变得越来越重要,而这并非易事。为解决以上问题,来自南洋理工大学 LMMs-Lab 的研究人员联合开源了 LMMs-Eval,这是一个专为多模态大型模型设计的评估框架,为多模...……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本

...标工作。标包2:基于大模型的电力设备诊断与综合预测框架研究咨询服务。现有设备诊断存在依靠人工经验、多源多模态数据利用不充分、诊断准确度无法保证等技术难题。为解决上述问题,构建具备持续学习能力的电力设备...……更多
2025-01-04 00:41:00模型,电力,输配,输配电,框架,电力

...学构建了一个大规模、多任务评测基准Shopping MMLU,用以评估大语言模型在在线购物领域的能力与潜力。一直以来,想要完整建模在线购物相当复杂,主要痛点是:多任务性:在线购物中存在多样的实体(例如商品、属性、评论...……更多
2024-11-21 09:45:00在线购物,基准,模型,任务,购物,数据
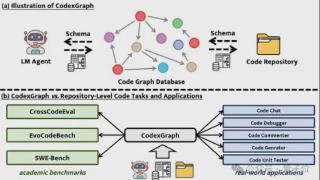
...中发挥了关键作⽤。
真实应⽤场景⽰例基于ModelScope-Agent框架 ,CodexGraph的实际应⽤价值在多个场景中得到了体现,如:代码聊天助⼿(Code Chat)
代码调试⼯具(Code Debugger)
单元测试⽣成器(Code Unit tester)
代码⽣成器(……更多
2024-08-12 09:49:00西安交大,新加坡,阿里,西安,开发者,福音

...异。目前OmniSearch在魔搭社区还有demo可玩。动态检索规划框架,打破传统mRAG局限传统mRAG方法遵循固定的检索流程,典型的步骤如下:
输入转化:接收多模态输入(例如图像+文本问题),将图像转化为描述性文本(例如通过image...……更多
2024-12-05 09:45:00模态,拆解,阿里,检索,过程,智能

...景,无论是针对工业生产目标,还是科学场景辅助需求,评估 LLM 在精细化维度上的能力都是至关重要的,例如:数学及其专门分支领域,如代数、几何、概率和微积分。
不同类型的推理能力,例如符号推理、类比推理、反事实...……更多
2024-10-23 12:03:00多维,基准,群体,模型,自动化,评估

...到处理模糊问题、私有代码库集成等多种模式,可以全面评估模型的交互式数据分析能力。这一基准不仅包括代码生成任务,还设计了多选题任务,要求模型在代码执行后对结果进行理解、归纳和推理,提供有价值的观点。尽管...……更多
2024-04-07 10:50:00立新,数据分析,基准,科学家,模型,评估

...应用方面安全测试领域的空白,为业界提供了统一的测试框架和明确的测试方法,有助于提高人工智能系统安全性,促进技术负责任发展,增强公众信任。记者了解到,此次发布的两项国际标准是大模型及生成式人工智能应用方...……更多
2024-04-25 04:00:00基准,评估,测试,安全,全球,人工智能
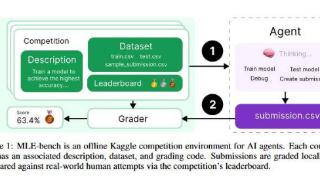
...务中的能力。OpenAI在MLE-bench上测试了多个AI模型和智能体框架,使用AIDE框架的o1-preview模型表现最佳,在16.9%的比赛中至少获得了一枚铜牌,该结果超越了Anthropic的Claude3.5Sonnet。获得5金即可评上"Grandmaster"特级大师,而o1-……更多
2024-10-12 20:06:00基准,机器,任务,学习,基准,自然语言

...成、输出数据生成和质量优化。输入数据生成在 SELF-GUIDE 框架的设计和实现过程中,研究者首先根据任务类型(生成型任务或分类型任务)指定不同的提示模板。对于生成型任务, SELF-GUIDE 框架使用一个相对简单的提示模板。而...……更多
2024-08-02 09:40:00清华,性能,任务,数据,学习,生成

...本间存在多对多问题,无法支持细粒度视频检索的训练与评估(图 1 (a)),因此有必要为细粒度 VCMR 建立一个合适的 benchmark。为解决此问题,该研究提出了细粒度 VCMR 场景,使用更精细的文本查询消除数据集中的多对多现象(...……更多
2024-10-29 09:55:00大规,粒度,范式,清华,片段,大规模

...和卡内基梅隆大学,组建科研团队,合作开发了 ExploreToM 框架,旨在更有效地评估和训练大语言模型(LLM)的心智理论(Theory of Mind,ToM)能力。心智理论心智理论(Theory of Mind,ToM)是人类社会智能的基础之一,能让我们能够...……更多
2024-12-21 09:27:00之路,心智,难题,突破,理论,模型

...京大学一支团队迅速跟进,用自研的全球首个全模态对齐框架「Align Anything」对 Llama 3.2 进行了微调,表现出了比 Meta 微调的 Llama-3.2-11B-Vision-Instruct 更强的对齐性与指令跟随性。
为进一步促进社区的多模态对齐研究,日前,该...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

...h基准测试,通过270个基于90篇跨学科科学论文的任务,可评估AI智能体在计算可重复性方面的表现,最简单任务的准确率可以达到60%,最难任务准确率仅有21%大模型的能力越来越强,用户在一些重要的任务中也可以依赖大模型,...……更多
2024-09-26 13:38:00普林,普林斯顿,斯顿,准确率,基准,科学家

...可以优于专有系统,甚至媲美人类专家。为了方便自动化评估,团队还一道推出了全新的大规模基准ScholarQABench,覆盖了CS、生物、物理等多个学科,用于评价模型在引用准确性、涵盖度和质量的等方面的表现。由UWNLP和Ai2两大顶...……更多
2024-11-27 13:33:00神器,文献,效率,科研,学术,模型

...踪一切」模型SOLAMI:首个端到端社交视觉-语言-动作建模框架RevThink:使用逆向思维增强 LLM 推理想要第一时间获取每日最新大模型热门论文? 点击阅读原文,查看「2024必读大模型论文」合集,以及申请加入「大模型技术分享群...……更多
2024-12-10 09:53:00模型,语言基础,清华,定律,密度,团队

...评估属性。任务定义任务属性RECIPE终身编辑方法总体模型框架如下:构造和更新知识检索仓库在第t个时间步,给定一个新的知识描述kt,则新知识表示通过编码器frm中的MLP层可以获得:
其中frm编码器将输出token表示的最大、最...……更多
2024-10-30 09:57:00模型,训练,知识,数据,模型,知识
...需要帮助来保持准确性和连贯性。MMMLU数据集提供了一个框架,用于测试传统上在NLP研究中代表性不足的语言模型,从而弥补了这一差距。MMMLU数据集意义MMMLU的发布解决了人工智能界的几个相关挑战。它提供了一种更具多样性和...……更多
2024-09-24 22:07:00多语,大规,大规模,任务,语言,语言

新的大语言模型(LLM)评估基准对于跟上大语言模型的快速发展至关重要。近日,淘宝天猫集团的研究者们提出了中文简短问答(Chinese SimpleQA),这是首个全面的中文基准,具有“中文、多样性、高质量、静态、易于评估”五...……更多
2024-11-22 09:51:00豆包,中文,真实性,评估,模型,中文

...练过程中引入偏好学习,提出了一个全新的代码生成优化框架——CodeDPO。在部分模型上,相比于单独使用SFT,CodeDPO能够将模型的HumanEval得分再多提升10个百分点,最高增幅接近1/3。监督微调(SFT)等现有训练方法,尽管提升了...……更多
2024-11-28 09:57:00代码生成,偏好,框架,北大,生成,模型
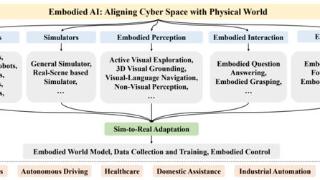
...任务。下图展示了具身智能体的典型架构。
具身智能体框架在本综述中,我们对具身智能的当前进展进行了全面概述,包括:(1)具身机器人—— 具身智能在物理世界中的硬件方案;(2)具身仿真平台—— 高效且安全地训练...……更多
2024-07-29 09:39:00中大,文献,调研,深度,实验室,实验

...hub.io/代码仓库:https://github.com/thu-ml/MMTrustEvalMultiTrust基准框架从已有的大模型评估工作中,MultiTrust提炼出了五个可信评价维度——事实性(Truthfulness)、安全性(Safety)、鲁棒性(Robustness)、公……更多
2024-07-25 09:31:00模态,清华,可信度,领衔,可信,几何
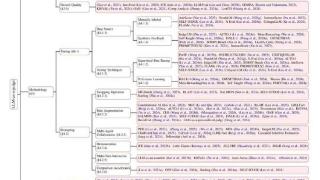
...。随着技术的发展,越来越多复杂且动态的 LLM-as-a-judge 框架被开发出来,例如多智能体判断和 LLM-as-a-examiner。在未来,一个有前景的研究方向是开发具有人类评判思维的大模型智能体;另外,开发一个基于大模型自适应难度的...……更多
2024-12-04 09:49:00范式,模型,基准,偏见,数据,评估
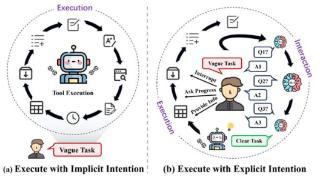
...与用户明确的交互来理解用户的隐式意图。以 Mistral-7B 为框架,基于 IN3 训练的 Mistral-Interact 能主动评估任务的模糊性,询问用户意图,并在启动下游智能体任务执行之前将其细化为可操作的目标。将该模型嵌入 XAgent 框架后,...……更多
2024-08-14 09:39:00意图,模型,人类,智能,智能,任务

...关注的大模型前沿论文北大团队提出「自定义漫画生成」框架UniReal:通过学习真实世界动态实现通用图像生成和编辑苹果团队提出「可扩展视频生成」方法利用扩散 Transformer 进行视频运动迁移ObjCtrl-2.5D:无需训练的「图生视频...……更多
2024-12-13 09:19:00推理,模型,思维,空间,模型,生成
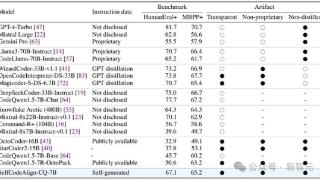
...效率。 类生成:给定一个包含类级和方法级信息的代码框架,要求LLM生成类及其方法。 数据科学编程:给定数据科学任务的描述和部分代码片段,要求LLM完成代码片段以通过相应的测试。 文件级代码编辑:提供文件内容后,要...……更多
2024-11-29 09:26:00伯克,伯克利,进化,模型,代码,方法
更多关于科技的资讯:

第十四届中国创新创业大赛——首届具身智能专业赛成果在厦发布。厦门网讯(文/厦门日报记者 吴晓菁 通讯员 高菲 康潇潇 图/厦门日报记者 卢剑豪)昨日的厦门国际会议中心酒店
2025-09-26 08:38:00
具身智能孵化加速器在厦正式揭牌第十四届中国创新创业大赛首届具身智能专业赛昨日发布成果东南网9月26日讯(海峡导报记者 黄奕琳)昨日
2025-09-26 10:17:00

日前,2025年农业机械检测实验室间比对活动在山东潍坊举行。该活动由中国农业机械化协会主办、农机鉴定检测分会承办、潍柴雷沃智慧农业协助开展
2025-09-26 07:05:00

560余家企业携4.8万余个岗位来东大揽才“AI+”岗位热度不减,实战经验是核心指标□南京日报/紫金山新闻记者何洁 实习生黄佳琪杨久久9月25日
2025-09-26 07:41:00
9月24日,“青春华章・向西而歌”网络大思政课活动上,西安交通大学微电子学院集成电路工程专业博士研究生魏上杰介绍,集成电路是“国之重器”的“心脏”
2025-09-25 09:44:00

企查查APP显示,近日,杜建英持股的杭州芸台文化创意有限公司被吊销,原因是公司成立后无正当理由超过6个月未开业,或者开业后自行停业连续6个月以上
2025-09-25 11:20:00

9月25日,雷军发文:这5年,小米一路摸爬滚打、跌宕起伏,依然启动了造车、芯片和高端化……没什么好犹豫的,五十来岁,正是闯的年纪
2025-09-25 11:20:00

赤水河畔,国内首台高温复合型仿生压曲机稳定运转,物联网实时优化发酵参数……这场酿酒的“数字革命”,也是贵州习酒公司以全链数智革新推动产业跃迁的生动缩影
2025-09-25 11:57:00

在人工智能技术日臻成熟的2025年,AI已是深度融入职场生态的“数字同事”,在AI辅助下的2025年职场迎来了哪些变化
2025-09-25 13:30:00
国庆前夕,房山区物美超市“胖改店”、居然之家房山店、瑞莱广场分别于9月26日、27日、28日开业,进一步丰富了房山区消费场景
2025-09-25 13:38:00

企查查APP显示,近日,负责OPPO项目的杭州逗酷软件科技有限公司发生工商变更,新增山子高科旗下浙江山子超影科技有限公司为股东
2025-09-25 16:25:00