- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

快科技7月29日消息,如今的AI大模型规模越来越庞大,动辄成百上千亿参数,训练过程不仅需要数万甚至十几万块GPU加速卡,出错的几率也越来越高。Meta(Facebook)就披露了一份惊人的报告。Meta在报告中披露,为了训练自己的Llama ...……更多
2024-07-29 11:30:00时报,模型,训练,参数,训练,错误

...皇统治时期建造的。第 7 代:英国的建筑。在接受《纽约时报》采访时,赖特说:"我不认为我能够做我想做的事情有什么问题。它只是对我不起作用。"他补充说:"我不知道你是否可以称之为有趣、第 9 代:建筑。除了成为全球...……更多
2023-07-17 15:49:00完了,人类,数据,数据,模型,训练

...开的彻彻底底。这不,Meta一连放出三篇技术文章,从大模型适配方法出发,介绍了:如何使用特定领域数据微调LLM,如何确定微调适配自己的用例,以及如何管理良好训练数据集的经验法则。接下来,直接进入正题。适配大模...……更多
2024-08-27 12:03:00小白,长文,千字,基础,指南,训练

...蒸馏这一概念,能在保证准确率接近的情况下,大幅压缩模型参数量,让模型能够部署在各种资源受限的环境。比如Siri能够出现在手机上,就是用知识蒸馏压缩语音模型。自它之后,大模型用各种方法提高性能上限,再蒸馏到...……更多
2025-02-07 17:44:00得主,知识,模型,目标,知识,训练

就在刚刚,Meta 发布了其最先进开源大型语言模型的下一代产品——Llama 3。据介绍,Llama 3 在 24K GPU 集群上训练,使用了 15T 的数据,提供了 8B 和 70B 的预训练和指令微调版本,可以支持广泛的应用。同时,Llama 3 在广泛的行业...……更多
2024-04-20 11:03:00模型,训练,参数,数据,全球,模型

...办法缓解AI发展与算力消耗海量资源之间的矛盾?《环球时报》记者就此采访了业内专家。训练AI为何会消耗海量资源随着OpenAI公司发布的聊天机器人ChatGPT的爆红,各国都加快了AI大模型的训练,需要的算力也急速增加。马斯克...……更多
2024-06-29 09:27:00资源,数据中心,数据,能耗,模型,消耗
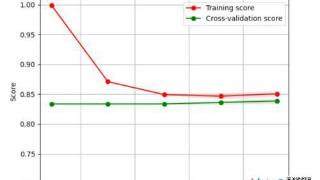
...值向量,进而利用监督学习的方法进行训练。通过训练,模型能够学习到从文本到类别的映射关系,从而实现对新文本的自动分类。这些算法在垃圾邮件识别、新闻分类、情感分析等领域有着广泛的应用。关键词:TF-IDF;决策树...……更多
2024-08-26 09:59:00性能分析,算法,电子邮件,性能,常见,邮件
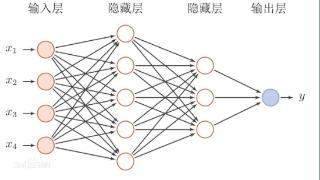
...标准化和归一化以及特征选择和降维技术。最后,介绍了模型构建和训练的关键步骤,包括深度学习模型的选择和设计、模型初始化和参数调整、批量梯度下降和优化算法以及学习率调整和模型评估。通过这些步骤,可以提高深...……更多
2023-09-12 11:30:00深度,关键,应用,学习,教育,技术

不必增加模型参数,计算资源相同,小模型性能超过比它大14倍的模型!谷歌DeepMind最新研究引发热议,甚至有人表示这可能就是OpenAI即将发布的新模型草莓所用的方法。研究团队探究了在大模型推理时进行计算优化的方法,根...……更多
2024-09-12 09:58:00模型,参数,模型,训练,测试,时计

...研究显示,参数量爆发的GPT-2,生成的文本几乎与《纽约时报》的真实文章一样令人信服。这也让更多人意识到无监督学习下,大模型的价值所在。伴随着每年一更新的频率,2020年,GPT-3如约而至。这次的GPT-3,在模型参数上达...……更多
2023-02-08 19:19:00迭代,路线,背后,观察,行业,模型

...进行编码的样式参数。研究人员在六维N-body相空间上训练模型,将粒子速度预测为模型位移输出的时间导数,显著提高了训练效率和模型准确性。最终,模拟器在测试数据(训练期间未见过的各种宇宙学和红移)上实现了良好的...……更多
2024-09-20 13:34:00暗物质,仿真,宇宙,突破,结构,粒子

随着 AI 模型的参数量越来越大,对算力的需求也水涨船高。比如最近,Llama-3.1 登上了最强开源大模型的宝座,但超大杯 405B 版本的内存就高达 900 多 GB,这对算力构成了更加苛刻的挑战。如何降低算力的使用成本和使用门槛,...……更多
2024-10-09 09:52:00模型,跟着,博客,模型,参数,训练

引言:MaaS(ModelasaService,模型即服务)是一种将人工智能算法模型及其相关能力封装成服务,以降低人工智能技术使用门槛、控制应用建设成本、简化系统运维管理复杂度,并提升人工智能技术的综合应用效能的模式。 上新了...……更多
2024-08-07 09:45:00模型,服务,平台,科技,模型,数据

...为什么不使用MoE架构?后训练与RLHF流程是如何进行的?模型评估是如何进行的?我们什么时候可以见到Llama 4?Meta是否会发展agent?恰逢Llama 3.1刚刚发布,Meta科学家就现身播客节目Latent Space,秉持着开源分享的精神,对以上问题...……更多
2024-07-29 09:33:00科学家,训练,科学,模型,训练,基准

让大模型能快速、准确、高效地吸收新知识!被EMNLP 2024收录的一项新研究,提出了一种检索增强的连续提示学习新方法,可以提高知识终身学习的编辑和推理效率。模型编辑旨在纠正大语言模型中过时或错误的知识,同时不需...……更多
2024-10-30 09:57:00模型,训练,知识,数据,模型,知识

...列长度为8,192个数据单元,以处理更长的上下文信息纽约时报点评道,开源Gork背后的原始代码,是这个世界上最富有的人控制AI未来战斗的升级。Meta CEO扎克伯格刚刚也对Grok做出了评价:“并没有给人留下真正深刻的印象,3140亿...……更多
2024-03-20 13:44:00马斯,马斯克,模型,全球,马斯,马斯克
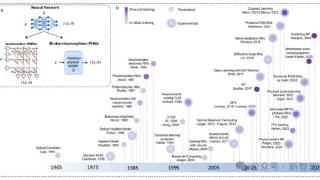
...一新兴的前沿领域还鲜少有人涉足,但绝对值得深耕!AI模型再扩展1000倍的秘密可能就藏在这里。随着Scaling Law越来越成功,LLM的电力和算力消耗也逐渐达到了惊人程度。我们越来越难以想象,当前的模型规模如何能再扩大10倍...……更多
2024-07-15 09:33:00康奈尔,康奈,耶鲁,剑桥,变革,模型

在这段时间,有关大语言模型的消息频频传出,许多人也逐渐了解、甚至开始应用起相关的AI软件。那么,你了解GPT模型的原理是什么吗?大模型和传统AI的区别在于哪里?其应用可以体现于哪些方面?一起来看看作者的分析和...……更多
2023-05-10 03:00:00一键,原理,应用,模型,用户,问题


...被问及训练数据的来源时,她表示不会透露细节。《纽约时报》称,与OpenAI一样,谷歌也转录了YouTube视频,为其AI模型收集文本,这可能侵犯了视频创作者的版权。去年,谷歌还更改了其服务条款。此番动机意图明显,即允许AI...……更多
2024-04-17 03:27:00巨头,秘密,数据,数据,训练,公司

...字逐句照搬训练时“见过”的大段文本。前不久,《纽约时报》向美国曼哈顿联邦法院提起诉讼,指控OpenAI涉嫌违规使用其内容用于人工智能开发的事件引起了社区极大的关注与讨论。《纽约时报》称其“非法使用”“数百万篇...……更多
2024-01-11 06:45:00生成,输出,抄袭,问题,图片,输出

...,一大波测评刷屏全网。更惊喜的是,苹果AI背后的基础模型47页技术报告,也一并上线了。一大早,人们期待已久的「苹果AI」首个预览版,正式向开发者们推送了!iOS 18.1、iPadOS 18.1、macOS Sequoia 15.1三大系统中,全都植入了苹...……更多
2024-08-01 09:40:00进化,模型,苹果,报告,技术,苹果

...BM现已开源其“最先进”和高性能的Granite(花岗岩)代码模型。IT之家附开源链接如下:GitHub:点此进入HuggingFace:点此进入Granite代码模型的参数范围从3B到34B,并且有基础模型和指令跟随模型两种变体,适用于复杂应用现代化...……更多
2024-05-22 10:19:00高性能,最先,模型,代码,模型,代码
证券时报记者 叶玲珍过去一年多,以ChatGPT为代表的生成式AI(人工智能)技术狂飙突进,各路科技巨头争相入局,试图在技术演进、应用落地风口抢占更多话语权,“百模大战”已然打响。本期“中国智造面对面”走进科大讯...……更多
2024-01-29 09:22:00青华,讯飞,工程院,院长,工程,模型
本文转自:北京日报崔文佳去年年末,美国《纽约时报》起诉微软和OpenAI侵犯其版权。半个多月来,这一消息不仅为“吃瓜群众”津津乐道,也引发相关行业人士的关注。这场争端显示出传媒业与AI技术的复杂关系,值得全社会...……更多
2024-01-17 04:25:00厘清,边界,版权,时代,纽约,纽约时报

...随着ChatGPT在法律、金融、营销等领域的广泛使用,确保模型的安全、准确输出同时被很好理解变得非常重要。但由于神经网络的复杂和多变性,我们根本无法验证其生成内容的准确性,这也就会出现输出“黑盒”的情况。为了...……更多
2024-07-18 09:47:00最新技术,难题,研究,技术,模型,小数
近日,OpenAI今年3月发布的GPT-4大模型的详细参数和信息被揭秘。据了解,GPT-4在120层中总共包含了1.8万亿参数,相比之下,GPT-3只有约1750亿个参数。为了保持合理的成本,OpenAI采用混合专家模型来进行构建。混合专家模型是一种...……更多
2023-07-13 19:47:00参数,高达,成本,训练,模型,训练

...VentureBeat报道,德国AI创企Aleph Alpha今日发布了两个大语言模型(LLM)。这两个模型各拥有70亿个参数,可以在多种欧洲语言中提供简洁、长度可控的响应,并已开源。该公司宣称,其模型的性能可以与其他在70亿到80亿参数量级的...……更多
2024-08-28 09:43:00博世,纯血,惠普,欧洲,德国,模型

...智元了解,字节商业化技术团队早在去年就把视觉自回归模型作为重要的研究方向,团队规划了VAR为高优项目,投入研究小组和大量资源。
除了VAR,团队还发表了LlamaGen等相关技术论文,新的研究成果也将在近期陆续放出。事...……更多
2024-12-05 09:47:00实习生,下巴,字节,实习,论文,模型

...示自己的坦诚态度,Mustafa也透露未来三年Inflection AI的大模型进展:"在接下来的3年里,我们要训练的模型要比现在大1000倍。甚至在未来18个月内,Inflection的模型就将比目前的前沿模型大100倍。"对于大模型如此快速的发展,有网...……更多
2023-09-05 19:31:00联创,大料,落后,模型,训练,正在
更多关于科技的资讯:

北京,2025年9月24日——北京 CBD 核心区再添重磅力作!今日,备受瞩目的 Z3 超甲级写字楼项目正式揭开神秘面纱
2025-09-25 13:43:00

9月19日,中国电信山东公司、天翼物联科技公司与青岛海信日立在青岛举行联合实验室揭牌仪式,标志着三方战略合作迈入全方位深度融合的新阶段
2025-09-25 13:43:00

9月24日至26日,全球云计算与 AI 领域年度旗舰盛会 ——2025 云栖大会在杭州云栖小镇盛大启幕。本届大会以“云智一体・碳硅共生”为核心主题
2025-09-25 13:44:00
为落实《个人征信电子授权安全技术指南》(JR/T 0299—2024)金融行业标准,规范金融机构在个人征信电子授权中的技术操作
2025-09-25 13:44:00

秋意渐浓,北京迎来一场文玩行业盛会。9月24日至28日,以“国潮觉醒 文玩新生”为主题的2025全国文玩大会于潘家园市场(西区)盛大举行
2025-09-25 13:46:00
如今,微短剧已然从“内容新贵”成长为拉动数字经济的重要力量。因为“轻、快、密”的内容节奏,短剧得以迅速占领用户的碎片时间
2025-09-25 13:46:00

日前,北京市工商联、通州区人民政府联合召开2025北京民营企业百强发布会。会上,网易有道凭借持续的创新能力和稳健的业绩表现
2025-09-25 10:06:00

近日,首批龙晶PR型有晶体眼人工晶状体植入手术在济南爱尔眼科医院完成,作为“尝鲜吃螃蟹”的人,患者脸上洋溢着发自内心满意的微笑
2025-09-25 11:20:00
观赛有了更佳的趣味性与沉浸感金科院数字科技赋能国际赛艇大赛南报网讯(通讯员陆慧记者姜静实习生黄佳琪)2025南京·大学生国际赛艇公开赛近日在外秦淮河畔举行
2025-09-25 07:38:00
提升“双盲”模式下的评标质效雄安新区面向评标专家智能问答系统正式上线河北日报讯(见习记者康晓博)只需轻点鼠标,远在外地的评标专家就能获得精准指引
2025-09-25 07:58:00

大模型算出爆款,红枣变致富“金枣”——看沧县红枣及干坚果食品加工产业如何实现数字化转型9月18日,河北华聚食品有限公司的工人忙着打包红枣产品
2025-09-25 07:59:00
9月17日,兴业银行信用卡中心与美团企业版在上海签署战略合作协议,共同打造“金融+生活”开放生态。根据协议,双方将基于开放共享
2025-09-24 07:24:00
金洽会上51个重点产业项目签约,计划投资802.21亿元——一串串数字,见证企业对南京的高度认可□南京日报/紫金山新闻记者张甜甜9月23日
2025-09-24 08:11:00
5项科技创新成果案例发布芯片设计迎“超强大脑”多癌早筛一管血“搞定”南报网讯(记者张安琪)9月23日,2025南京金洽会开幕式重点发布环节
2025-09-24 08:12:00
在今年国庆、中秋双节消费旺季来临之际,济南122站以“客户体验感”为核心,从“环境优化、商品管理、客户拓展”三大维度精准发力
2025-09-24 08:50:00