- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...语言模型 (LM) 在各种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建和部署成本过高。改善成本 - 性能的一种方法是使...……更多
2024-09-06 10:01:00推理,模型,成本,参数,模型,训练

...凡的性能而获得了前所未有的关注。然而, LLM 的训练和推理成本高昂,人们一直在尝试通过各种优化方法来降低成本。本文来自上海算法创新研究院、北京大学等机构的研究者受人类大脑记忆层次结构的启发,他们通过为 LLM ...……更多
2024-07-11 09:33:00维南,领衔,院士,新作,模型,存储

...。相比原生PyTorch,单机训练速度最高可提升7.73倍,单卡推理速度提升1.42倍,仅需一行代码即可调用。对于微调任务,可最多提升单卡的微调模型容量3.7倍,同时保持高速运行,同样仅需一行代码。要知道,ChatGPT火是真的火,...……更多
2023-02-15 15:47:00流程,成本,模型,训练,内存,参数
...算效率和算力开销两大问题成为新的行业焦点。对大模型推理成本的优化,可通过很多技术手段实现。首先是模型本身,模型结构、训练方法都可以持续改进,包括业界很关注的MoE(混合专家模型),就是优化推理成本很好的解决...……更多
2024-06-03 14:07:00模型,效率,成本,模型,推理,成本

...万维宣布开源2千亿稀疏大模型Skywork-MoE,性能强劲,同时推理成本更低。Skywork-MoE基于之前昆仑万维开源的Skywork-13B模型中间checkpoint扩展而来,是首个完整将MoE Upcycling技术应用并落地的开源千亿MoE大模型,也是首个支持用单台409...……更多
2024-06-03 20:59:00万维,昆仑,模型,模型,万维,昆仑

...。相比原生PyTorch,单机训练速度最高可提升 7.73倍,单卡推理速度提升1.42倍,仅需一行代码即可调用。对于微调任务,可最多提升单卡的微调模型容量 3.7倍,同时保持高速运行,同样仅需一行代码。要知道,ChatGPT火是真的火,...……更多
2023-02-17 14:37:00流程,成本,模型,训练,内存,参数

...在MMLU(多任务语言理解)、Knowledge(知识)、Reasoning(推理)、Comprehension(理解)等关键指标上均超越了Meta Llama 2的13B模型。这一个故事,在2024年2月1日的发布会上,也被AI模型层公司面壁智能的CEO李大海不断提起。对标Mistral..……更多
2024-02-03 16:03:00适配,推理,模型,主流,成本,智能

...,MoE在训练过程通过门控模型实现“因材施教”,进而在推理过程实现专家模型之间的“博采众长”。 图1MoE架构原理示意图1MoE的特征优势是专家化、动态化、稀疏化,在模型研发成本、训练/推理效率和整体性能之间实现最佳...……更多
2024-11-04 16:00:00研究方向,模型,现状,方向,趋势,研究

...码仓库 Trending Research 第一位。为了赋予机器人端到端的推理和操纵能力,本文创新性地将视觉编码器与高效的状态空间语言模型集成,构建了全新的 RoboMamba 多模态大模型,使其具备视觉常识任务和机器人相关任务的推理能力,...……更多
2024-06-21 09:52:00机器,模态,人多,机器人,推理,北大
...基座大模型基础上,仅耗费数十美元就开发出相对成熟的推理模型。尽管其整体性能尚无法比肩美国开放人工智能研究中心(OpenAI)开发的o1、中国深度求索公司的DeepSeek-R1等,但此类尝试意味着企业可以较低成本研发出适合自...……更多
2025-02-27 05:08:00范式,模型,科研,团队,成本,全球

...类型的信息:- 仅输入和输出文本,也就是少样本学习- 推理追踪:添加中间推理步骤,可参阅思维链(COT)提示- 计划和反思追踪:添加信息,教LLM计划和反思其解决问题的策略,可参阅ReACT
选择正确的适配方法要决定上述哪...……更多
2024-08-27 12:03:00小白,长文,千字,基础,指南,训练

...处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan3还突破“迭代式强化学习”技术...……更多
2024-01-29 19:57:00百川,模型,语言,智能,模型,百川

...。本次新上线了包括:模型训练新基座,支持模型训练、推理、量化、评测等功能。 卓世科技MaaS平台是一款基于知识增强大模型的一站式行业模型训练开发平台。面向开发者和企业提供从基础算力服务、数据服务、模型训练服...……更多
2024-08-07 09:45:00模型,服务,平台,科技,模型,数据

...考两种模式。对于需要深入思考的复杂问题,模型会逐步推理,经过深思熟虑后给出最终答案。对于速度有要求的简单问题,模型则提供快速、近乎即时的响应,让用户实现对模型思考程度的控制。阿里通义团队认为,这两种模...……更多
2025-04-29 16:17:00模型,阿里,话语权,中国,话语,全球

...十亿左右。“做大”,能让大模型具备更强的涌现能力和推理能力,从而适用于难度更高的任务。“做小”,能让大模型获得更优秀的推理能力,从而能被部署到手机、手表、耳机、录音笔等各类小微终端之中。情景学习(ICL,...……更多
2024-03-01 09:36:00模型,范式,科学家,情景,能力,科学

... OpenAI 在大语言模型领域的新尝试,也可能是对人工智能推理能力一次新的革命性提升。根据目前流出的信息来看,相比以往的 GPT 模型,「草莓」在处理复杂问题、执行多步骤任务方面展现出前所未有的潜力,使其成为通用人...……更多
2024-09-12 09:49:00推理,草莓,定价,能力,项目,草莓

...以通过语音识别技术被录入到病例系统中,随后大模型AI推理技术辅助进行智能总结和诊断,医生们撰写病例的效率显著提高。AI推理的应用不仅节省了时间,也保护了患者隐私;在法院、律所等业务场景中,律师通过大模型对...……更多
2024-07-11 16:45:00正在,时代,模型,推理,英特,英特尔

大模型预训练“缩放定律”定律失效?模型推理成“解药”,英伟达一家独大格局要变天?“缩放定律”指导下,AI大模型预训练目前遭遇瓶颈。据路透12日报道,硅谷主要AI实验室的新模型训练计划目前普遍进展不顺,新模型...……更多
2024-11-13 14:09:00英伟,争论,逻辑,意味,根本,策略

...将计算和参数解耦,在保证模型效果的同时,有效解决了推理过程中的访存问题,为人工智能领域带来了新的突破。据了解,UltraMem架构巧妙地将计算与参数分离,不仅确保了模型的卓越性能,更针对推理过程中的访存瓶颈提出...……更多
2025-02-13 19:51:00豆包,字节,推理,架构,模型,团队
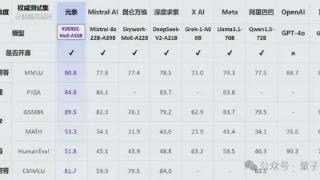
...到100B模型性能的「跨级」跃升。同时训练时间减少30%,推理性能提升100%,使每token成本大幅下降。在多个权威评测中,元象MoE效果大幅超越多个同类模型。包括国内千亿MoE模型 Skywork-MoE、传统MoE霸主Mixtral-8x22B 以及3140亿参数的Mo...……更多
2024-09-18 13:36:00中国,商用,模型,参数,模型,专家
...测中,它的综合能力逼近当时的顶尖大模型,尤其在逻辑推理和数学题上展现出强劲性能,而且它的成本要远低于作比较的其他大模型。更令圈内研究者惊喜的,是它在训练方式上的简化。以往的模型在提升推理能力时,通常依...……更多
2025-05-27 10:23:00里来,能力,模型,训练,推理,能力

...器双产品形态,率先实现从千亿参数大模型训练到场景化推理落地的全链条覆盖。联想创新性推出两大产品:面向敏捷部署的DeepSeek智能体一体机采用ThinkStationPX工作站为载体,搭载沐曦曦思N260 GPU。实测数据显示,在相同并发条...……更多
2025-02-06 15:13:00一体机,模型,一体,解决方案,训练,参数

...支持128k上下文长度。Phi-3.5-mini-instruct主要面向基础快速推理任务,Phi-3.5-MoE-instruct可胜任复杂推理任务,Phi-3.5-vision-instruct则兼具文本与视觉能力。性能最强大的Phi-3.5-MoE-instruct模型有419亿个参数,……更多
2024-08-22 09:49:00上下文,微软,架构,模型,上下,性能

...用于自身业务优化并对外开放合作。
大模型分为训练和推理两个过程,前者将大模型训练成型,后者即为应用。由于训练大模型需极大算力,开发成本高昂,业界多有关于不需“重复造轮”的讨论。例如,入场做大模型后,百...……更多
2023-10-14 00:21:00百川,阿里,前奏,模型,领域,智能

...The」。完整的回复,花了整整20个小时熟悉模型的训练和推理的朋友都知道,这些事情一点都不奇怪。集群搭建(GPU配置、网络设计、轨道优化等)、集群管理(实时监控、故障排除等)……个个都是「拦路虎」。对于缺乏相关...……更多
2024-08-02 09:47:00大厂,模型,参数,疯狂,服务器,服务

...型,MoE模型在相同成本下效果更优,在相同规模下训练/推理成本更低,而且容量大,可训练更多数据。当前MoE的挑战有训练稳定性差、专家负载不均衡等。
一些应对方案包括:1)Scaling Law探索,设计基于中小模型簇的MoE Scaling ...……更多
2024-11-06 09:41:00模型,腾讯,全家,生成,同时,语言
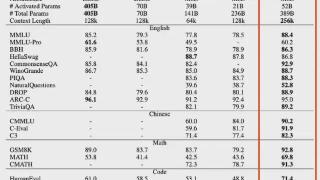
...含四个主要任务:信息抽取、信息定位、定性分析和数值推理。不同于现有的长文本基准测试,”企鹅卷轴”有以下几个优势:数据多样性:”企鹅卷轴”包含了各种真实场景下的长文本,如财务报告、法律文档、学术论文等,...……更多
2024-11-07 09:54:00腾讯,商用,模型,参数,模型,数据

...精度,还显著降低了计算负担,完美解决了时序大模型在推理阶段的计算瓶颈。2. 灵活的预测范围:Time-MoE支持任意长度的输入和输出范围,能够处理从短期到长期的各种时序预测任务,实现了真正的全域时序预测。3. 全球最大...……更多
2024-10-23 09:55:00时序,模型,团队,训练,参数,突破

...并发、技术自主可控方面具有优势的新选择。AI大模型在推理侧的新机遇与RISC-V创新架构具有的可扩展性、可编程性、超大规模等优势特点不谋而合。技术和场景应用的双重优势下,希姆计算的大模型一体机能支撑企业将基座模...……更多
2023-11-15 15:41:00模型,一体机,推理,快车,芯片,一体

... Yi-1.0 的持续预训练版本,使用 500B 个 token 来提高编码、推理和指令执行能力,并在 300 万个指令调优样本上进行了精细调整。刚一发布,就已经有开发者跃跃欲试:并收获了好评:
与前序模型相比,Yi-1.5 系列模型进一步提升...……更多
2024-05-14 09:56:00万物,模型,国产,再次,排行榜,模型
更多关于科技的资讯:
鲁网9月28日讯金融是经济的血脉,更是百姓生活的依托。在中国经济迈向高质量发展的今天,中国建设银行青岛市分行以国有大行的责任与担当
2025-09-28 10:37:00
五年连获七家世界知名轴承制造企业认证一根轴承钢转动全球——“铁疙瘩”怎样变成“金娃娃”(九)前不久,河钢集团石钢公司收到日本某国际知名轴承企业高碳铬轴承钢的认证邮件
2025-09-28 08:04:00
锚定新赛道 壮大新动能超31亿元新一代工业软件基地项目开工南报网讯(记者刘安琪)项目兴则产业兴,项目强则经济强。9月26日上午
2025-09-28 07:43:00

近日,山东省轻工联社发布《关于公布2025年度山东省中小企业服务支撑机构名单的通知》,山东移动成功入选。作为推动中小企业数字化转型的主力军
2025-09-27 08:11:00

在数字化浪潮席卷而来的今天,信息传输网络如同城市的“神经网络”,是智慧城市运转的核心支撑。作为这一无形“生命线”的守护者
2025-09-27 12:34:00

9月24日-25日,新城控股“2025第八届商业年会暨吾悦商管第一届悦链计划合伙人大会”在上海西岸美高梅酒店举行,新城控股集团董事长王晓松及公司高管
2025-09-27 12:37:00
25日上午,以“上山下山·食在晋安”为主题的晋安区“一县一桌菜”云上发布会举行,12道“云端”盛宴引爆味蕾。
2025-09-27 13:53:00

河北新闻网讯(张新)2025年,是我国“十四五”规划收官之年,也是“双碳”目标提出五周年。在此背景下,央视《东方时空》栏目近日推出“可控核聚变专题”
2025-09-27 14:45:00
9月25日,国网山西省电力公司发布消息,该公司成功完成配电网无人机电力北斗定位服务的全面应用,标志着该公司依托电力北斗高精度定位服务
2025-09-27 19:56:00

谢志强,现任中科汇理信息技术研究院党支部书记、秘书长、中科产学研合作一体化人才培育开发平台项目主任。历任中国银行总行风险管理部业务经理
2025-09-27 20:20:00

在第四届全球数字博览会上,贵州工匠行科技有限公司展出的SomaSeek具身智能平台,让机器人彻底告别了遥控器,也能听会说
2025-09-27 22:17:00

齐鲁晚报·齐鲁壹点 胡晓雪 李国栋9月26日,2025潍坊纺织服装产业国际精准对接活动在奎文区成功举办,本次活动以“我帮企业组主场·我为企业找订单”为主题
2025-09-27 22:22:00

齐鲁晚报·齐鲁壹点 陶春燕 山东省宇捷轴承制造有限公司是国家级专精特新重点“小巨人”企业、国内最大的调心滚子轴承生产企业
2025-09-27 20:05:00

当小区突发故障停电,地下车库里业主们的电动汽车,瞬间变身为一个巨大“充电宝”,为消防、通风和应急照明系统供电,守护社区安全
2025-09-27 12:35:00