- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

微软Ignite技术大会在西雅图揭幕。集团CEO纳德拉带来了长达一个小时的揭幕演讲,介绍微软在ESG、新一代空芯光纤、AzureBoost数据中心等项目的新动态。而整场演讲的重头戏,非AI莫属——尤其是首款自研AI芯片AzureMaia100的亮相,...……更多
2023-11-23 09:36:00老黄,英伟,微软,芯片,芯片,英伟

...个AI产业界。ChatGPT的大火,让OpenAI吸金能力飙升。2019年微软曾向OpenAI投资10亿美元,以换取OpenAI技术的独家许可。现在,OpenAI的估值飙涨至290亿美元。ChatGPT 在全球爆红还震动了AI界的大佬谷歌。ChatGPT推出不足1个月后,谷歌CEOSun...……更多
2023-01-30 13:04:00水平,技术,技术,生成,新技,用户

...GPT Plus已经可以适用GPT-4了在前不久的GPT-4“谣言”阶段,微软就曾多次通过各种渠道透出New Bing会第一时间应用GPT-4。新模型发布后,微软更是在第一时间宣布“我们很高兴确认新的Bing正在运行GPT-4,我们已经为搜索进行了定制...……更多
2023-03-16 09:00:00就是,模型,阿拉贡,能力,训练,模态

...大作的谷歌领导层,直接发布了「红色代码」。没多久,微软就给了谷歌一个暴击——宣布要把ChatGPT整合进自家的搜索引擎必应Bing中。而且,还没等谷歌喘口气,据知情人士透露,微软马上要给谷歌「双重暴击」了——微软计...……更多
2023-01-12 21:25:00微软,微软,模型,合进,邮件,电子邮件

...值超越苹果成为美股市值第二大公司;而今年早些时候,微软超越苹果成为全球市值最大公司。今年以来,苹果公司涨幅仅2%,远低于其他科技公司的涨幅。同期英伟达股价暴涨144%,谷歌和亚马逊股价涨幅也都超过20%。
AI——...……更多
2024-06-11 09:00:00库克,多年来,多年,苹果,人工智能,苹果公司

...启发。PHOTOGRAPH: EUGENE MYMRIN GETTY IMAGES去年9月的一个夜晚,微软的机器学习研究员塞巴斯蒂安·布贝克(SÉBASTIEN BUBECK)在醒来之后,想到了人工智能和独角兽。布贝克提前获得了 GPT-4 的使用权,这是 OpenAI 开发的一种强大的文本.……更多
2023-05-11 14:32:00智能,贝克,人工智能,人类,能力,人工

快科技4月16日消息,今天,微软宣布为Canary和Dev频道的Windows 11 Insiders用户推出截图工具应用的全新更新。此次更新将“文本提取”功能正式整合到系统自带的截图工具中,可以直接从屏幕上的任何图像中复制文本,无需先进行...……更多
2025-04-16 12:53:00截图,文本,微软,不用,更新,工具

...去,伴随 ChatGPT 再次将 AI 推向前沿科技的潮头,谷歌、微软、英伟达甚至百度都在按部就班的推动着历史进程,Facebook 似乎成为了一个尴尬的旁观者。2023 年 5 月,美国副总统哈里斯在白宫举办了一场 AI 主题的闭门会,谷歌、...……更多
2023-06-25 23:00:00伯格,扎克,称霸,进程,历史,伯格

...提的。根据Visible Alpha一致预测,2026年全球科技四巨头(微软,谷歌,META和亚马逊)合计资本支出将达2399亿美元,2023-2026年CAGR为18.86%。有观点曾寄希望于Scaling Law的边际效应收窄效应,认为只要熬到技术成熟期(Scaling Law效应边...……更多
2024-07-13 14:48:00李彦,模型,模型,技术,路径,基础

...输入时保留和重用之前的上下文信息。它通过固定数量的参数来存储和回忆信息,而不是随着输入序列长度的增加而增加参数量,能减少内存占用和计算成本。线性注意力机制不同于传统Transformer中的二次方复杂度注意力机制,...……更多
2024-04-14 02:57:00大内,机制,上下文,模型,处理,上下

...户测试了这个模型,2022年 9 月,公司将它推向了市场。微软为 OpenAI 提供资金,以换取其作品的独家商业版权,并将该模式整合到 Azure AI-as-a-service 平台中。8 月,Stability Diffusion 上线 作为解决了 DiscoDifusion 的技术痛点的……更多
2023-01-05 09:26:00模型,生成,用户,技术,应用,图像
...工人看了真的是脑阔痛。这就把腾讯一季度财报表现摘要截图扔给元宝,让它帮忙浅做分析:
元宝读取了图标中的数据,还在最后还小小总结了一把:总体来看,该公司在2024年3月31日的财务表现显著优于2023年3月31日,各项指...……更多
2024-08-09 09:38:00模态,腾讯,国产,模态,腾讯,元宝

...社区中虚心学习,我们会持续进步。”李开复朋友圈回应截图。来源:网络
在零一万物发布官方回应后,又有一张疑似原阿里技术副总裁贾扬清的朋友圈截图传出,强调在开源领域“魔改”不得:“开源是一个相互合作的事情...……更多
2023-11-16 16:45:00李开复,独角兽,旗下,争议,进步,模型
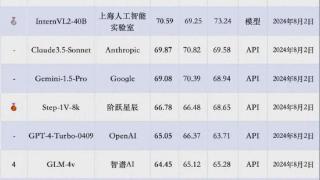
...论文亚军(Best Paper Runner-up):由厦门大学、清华大学、微软研究者共同完成的《Not All Tokens Are What You Need for Pretraining》(并非所有 token 都是预训练所需的), Zhenghao Lin 和 Zhibin Gou(……更多
2024-12-05 09:47:00论文,清华,亚军,字节,北大,模型

...周路平沉寂多时的PC市场,迎来了久违的热闹。不久前,微软推出了号称“史上最强Windows PC”——Copilot+PC,给市场打了个样,并带动华硕、戴尔、联想、三星、惠普和宏碁等多家PC厂商,纷纷宣布推出符合Copilot+PC标准的新款AI PC...……更多
2024-06-06 09:17:00华为,微软,大旗,华为,厂商,微软

...。清华大学自动化专业,读研究期间在新加坡国立大学、微软亚洲研究院、NEC美国实验室和谷歌研究院工作/实习。2008年,奔赴加州大学伯克利分校攻读计算机科学博士,期间创立开源深度学习框架Caffe,被微软、雅虎、英伟达...……更多
2023-08-04 15:00:00大牛,现实,创业,技术,技术,大牛

...时代的淘金者和卖铲人。自ChatGPT刷屏之后的数月时间,微软Azure与OpenAI的示范效应传导至全球,基本所有能做大模型的厂商都尝试“淘金”,其中,云厂商是一股重要力量,云计算天然适合大规模的AI任务,同时云厂商也有人才...……更多
2023-11-01 12:00:00阿里,模型,时代,模型,阿里,通义

...book和Instagram用户的照片上训练AI;《纽约时报》对OpenAI和微软提起诉讼,指控他们未经授权使用其数百万篇受版权保护的文章来训练生成式AI模型。面对AI这头数据饕餮,创作者们不得不与时俱进,学会用AI当作自己的武器,玩起...……更多
2024-08-11 19:03:00神器,水印,文字,生成,概率,文本

...接过程。PaperQA2 将 RAG 分解为工具,使其能够修改其搜索参数,并在生成最终答案之前生成和检查候选答案(下图 A)。PaperQA2 可以访问「论文搜索」工具,其中智能体模型将用户请求转换为用于识别候选论文的关键字搜索。候...……更多
2024-09-13 13:33:00博士后,模型,科研,博士,检索,能力

...处理各种各样的视觉信息,包括文档、图表、图表、屏幕截图、照片,并能进行多学科推理。xAI 表示,将于近期邀请早期测试者和现有的 Grok 用户测试。图源:官网AI大牛吴恩达加入亚马逊董事会4月12日消息,据亚马逊官方,Dee...……更多
2024-04-14 20:33:00模型,特斯,马斯,芯片,融资,英特

...一波,国内大部分人都没反应。春季后,券商报告强推,微软百亿投资openAI,百度紧跟形势不掉队,国内爆炒ChatGPT的热度甚至超过国外,大超预期。然而,ChatGPT不开放来自中国地区IP和手机号码的用户注册,大部分人没有真正...……更多
2023-02-09 10:43:00科学,文字,危机,问题,语言,生成

Meta和微软近日合作推出Llama2,这是Meta公司的下一代开源大型语言模型,可以免费用于研究和商业用途。微软在新闻稿中表示,Llama2旨在帮助开发者和组织,构建生成式人工智能工具和体验。Azure客户可以在Azure平台上更轻松、...……更多
2023-07-19 23:14:00微软,模型,合作,微软,模型,新闻稿

...实现NLG并向用户反馈。然而,这种模式存在显著缺点。如微软官方图例所示,和传统AI一样,用户每遇到一个新的场景,都需要训练一个相应的模型,费用高昂且发展缓慢,NLG层亟需改变。大型语言模型(如GPT)采用了一种截然...……更多
2023-05-10 03:00:00一键,原理,应用,模型,用户,问题

...日,注定是人工智能史上的一个重大时刻:OpenAI、谷歌、微软和智谱AI 等来自不同国家和地区的公司共同签署了前沿人工智能安全承诺(Frontier AI Safety Commitments);欧盟理事会正式批准了《人工智能法案》(AI Act),全球首部 AI...……更多
2024-05-24 16:30:00微软,人工智能,人工,智能,安全,全球

...型是如何学会「1 级推理」的?为此,作者对模型的内部参数进行了探针 probing 研究(见图 4)。结论显示(具体探针方法详见论文),在模型生成第一句话之前,它已经通过心算确定了哪些变量 A 是「必要的」(nece (A)=True)。...……更多
2024-08-06 09:27:00推理,模型,内心,人类,世界,模型

... 章和图像编辑,如人像抠图和海报生成。其次是AI升级的截图工具,现在支持文字提取功能,允许用户在截图中选择并提取文字,然后复制到剪贴板。还可以使用AI马赛克隐私信息。然后在画图&视频编辑功能方面,Windows的画...……更多
2023-10-18 10:00:00行业,月报,行业报告,要闻,报告,全球

...-10上训练了几百个扩散模型。目的是分析模型准确性、超参数、增强和重复数据删除中,哪些行为会对隐私性产生影响。最终得出了如下结论:
首先,扩散模型比GAN记忆更多。但扩散模型也是评估的图像模型中隐私性最差的一...……更多
2023-02-03 22:00:00绘画,侵权,模型,照片,模型,训练

...iv 发表,题目为《优化大语言模型测试时计算比扩大模型参数更高效》(Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters)[2]。论文作者包括:美国加州大学伯克利分……更多
2024-09-20 13:33:00模型,推理,思维,原理,核心,模型

...中。相关公司市值大涨美东时间2月7日周二,科技股龙头微软收涨逾4%,一夜市值飙涨超800亿美元(约5450亿元人民币),报267.56美元/股,最新总市值1.99万亿美元,为5个月新高。消息面上,微软公司推出了新的人工智能搜索引擎...……更多
2023-02-09 11:11:00山寨,月入,原版,山寨,用户,公众

...氪回忆第一次使用这款应用的瞬间,发现它和自己此前在微软参与的、需要强人工协助的对话Bot完全不同,真正称得上“智能化”。而让他彻底决定入局的,则是Stable Diffusion、Midjourney这类文生图产品。“五年以前我们生成图片...……更多
2023-06-25 10:53:00专访,模型,对话,视觉,一家,年度
更多关于科技的资讯:

秋分一过,大闸蟹长成,开始批量上市。近期,盒马的大闸蟹也正式上架,还做出了“不肥包退”的承诺。能够做到“不肥包退”,是因为今年盒马推出了首个大闸蟹分级企业标准
2025-09-24 20:37:00

2025年9月23日,上海 - 全球知名的健康公司康宝莱今日在上海举行“康宝莱全球产品创新中心”揭幕仪式。该中心由原“康宝莱中国产品创新中心”战略升级而成
2025-09-24 20:45:00
近日,由山东移动张店公司为区融媒体中心量身打造的“智慧研学服务平台”正式投入使用。该平台以信息化手段打通家长、教师、基地之间的信息壁垒
2025-09-24 20:48:00

备受行业关注的2025第五届邹区国际照明博览会将于9月26日正式拉开帷幕,将集合全球照明领域的最新技术成果与产品,致力于促进产业链各环节的深度协作
2025-09-24 20:55:00

十堰广电讯(全媒体记者 翁红)华药(十堰市)药业有限公司中药饮片生产线项目是京堰对口协作重点招商项目。自今年6月试生产以来
2025-09-24 21:00:00

由北京康盟慈善基金会与北京生命绿洲公益服务中心共同发起的“医药筹—畅享呼吸患者援助项目”,将于2025年10月1日起正式将援助范围扩展至甘肃省
2025-09-24 21:24:00


9月23日第25届中国国际工业博览会(简称“工博会”)在上海盛大启幕这场聚焦“新质”展现大国工业硬核实力的博览会以“工业新质
2025-09-24 20:55:00
在制造业提质增效的浪潮中,那些藏在生产环节里的“细枝末节”,往往藏着撬动效益升级的关键密码。近日,太重包储分公司的散件箱优化项目传来捷报
2025-09-24 07:52:00

文|胡香赟编辑|海若镜港股迎来今年第11家上市的创新药公司。9月19日,劲方医药在港交所挂牌,首日涨幅接近110%、市值逼近150亿
2025-09-24 06:26:00

中国青年报客户端北京9月23日电(中青报·中青网记者 沈杰群)今天,2025北京文化论坛平行论坛——“虚实无界:视听产业融合破圈”在北京国际饭店会议中心举行
2025-09-24 00:03:00

9月22日下午,在百余家江苏企业代表的共同见证下,中信银行“小天元”企业生态服务平台江苏区域发布会暨“进万企 信服惠企”系列活动在南京成功举办
2025-09-23 23:15:00

北京市科学技术委员会牵头,京冀相关单位共建智能模具科技成果转化中试平台一个平台,推动黄骅模具迈向高端9月11日,智能模具科技成果转化中试平台工作人员正在操作四轴机床进行生产
2025-09-23 08:49:00

数智化转型,让电厂越来越智慧——AI赋能千行百业一线故事(十二)8月28日,石家庄良村热电有限公司生产技术部专业主管苏朝宏介绍智慧展厅
2025-09-23 08:53:00

“产业炬光灯”系列短视频于厦门日报官方视频号、抖音号、快手号、B站账号、央视频账号等全媒体平台同步上线,首期节目走进中材航特
2025-09-23 08:58:00