- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。大语言模型都卷起来了,模型越做越大,token越来越多,输出越来越长。那么问题来了,如何有效地评估大语言模型的长篇大论呢?要是输出长度长了但...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...验评估方面,HourVideo采用五选多任务问答(MCQ)任务,以准确率作为评估指标,分别报告每个任务以及整个数据集的准确率。由于防止信息泄露是评估长视频中的MCQ时的一个重要挑战——理想情况下,每个MCQ应独立评估,但这种...……更多
2024-11-11 13:31:00团队,智能,空间,视频,模态,模型

...学场景。
所有数据和代码、模型均已开源。MMedBench 上的准确率,图 d 展⽰了在 MMedC 上进⼀步预训练使模型性能相⽐于基线显著提升。大规模多语医疗语料(MMedC)构建在构建数据集方面,研究团队收集了一份多语言医疗语料库...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...T4-8k、GPT3.5-turbo-6k、LlamaIndex这种商业模型,平均只有40%的准确率。而像开源模型表现就更不理想了…ChatGLM2-6B、LongLLaMa-3B、RWKV-4-14B-pile、LLaMA-7B-32K平均只有10%的准确率。目前该论文已被ACL 2024接……更多
2024-08-08 09:39:00基准,北大,生成,模型,文本,评估

...T-4o mini 仅 37.6 分,ChatGLM3-6B 和 Qwen2.5-1.5B 仅 11.2 和 11.1 的准确率。基于中文 SimpleQA,我们对现有 LLM 的事实性能力进行了全面的评估。并维护一个全面的 leaderboard 榜单。同时我们也在评测集上实验分析了推理 s……更多
2024-11-21 09:43:00事实性,基准,中文,评测,事实,模型
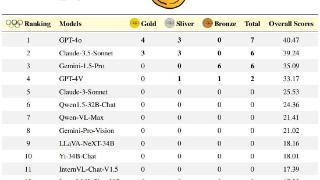
...过基于规则的匹配进行评估,研究团队对非编程任务使用准确率,并对编程任务使用公正的pass@k指标,定义如下:
本次评估中设定k = 1且n = 5,c表示通过所有测试用例的正确样本数量。奥林匹克竞技场奖牌榜:与奥运会使用的...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

... 作为备选。最终的报告结果将基于得分转换为 0 到 100 的准确率指标。未来也可以在我们动态更新的榜单里查看多模态模型在每个月动态更新的最新评测数据,以及在榜单上的最新评测的结果。 ……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本

...数据融合进核保预测模型中,不断修正核保结论,训练核保准确率。这种基于数据的分析和修正过程,使得平安保险核保系统能够准确地评估风险,提高核保的效率和准确性。面对保险行业核保场景新一轮的挑战,平安保险始终与时俱...……更多
2023-11-07 19:58:00平安保险,多维,平安,立体,评估,学习
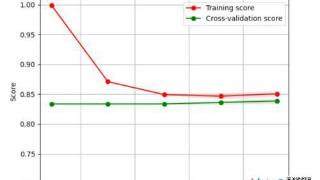
...贝叶斯算法学习曲线,红色线代表测试集(学习过程中)的准确率(Score),绿色线代表该模型在测试集上的准确率,线两侧的半透明带的宽度代表方差(方差越小,模型稳定性越好,泛化性能越好)。从图1可看出,随着训练量(Train examp...……更多
2024-08-26 09:59:00性能分析,算法,电子邮件,性能,常见,邮件

...的 LongVILA 模型在 1400 帧的大海捞针实验中实现了 99.5% 的准确率,相当于 274k 个 token 的上下文长度。此外, MM-SP 系统可以有效地将上下文长度扩展到 200 万个 token 而无需梯度检查点,与环形序列并行(ring sequence parallel……更多
2024-08-22 09:51:00英伟,准确率,支持,视频,序列,训练

...估了模型的性能,结果显示相比现有方法,RecDiff在推荐准确率方面取得了显著提升。未来,RecDiff团队计划将RecDiff拓展到更多推荐场景中,并结合多模态信息,进一步探索该模型的潜力和应用价值。论文:http://github.com/HKUDS/RecDif...……更多
2024-07-30 09:31:00社交,实验室,模型,实验,智能,数据

...评估AI智能体在计算可重复性方面的表现,最简单任务的准确率可以达到60%,最难任务准确率仅有21%大模型的能力越来越强,用户在一些重要的任务中也可以依赖大模型,比如说辅助做科研。不过现有科研辅助相关的基准测试都...……更多
2024-09-26 13:38:00普林,普林斯顿,斯顿,准确率,基准,科学家
...e given problem about geometric shapes.」可以看到,性能并不好,准确率只有 36%,应该有很大的改进空间。不过,在使用 APE 之前,让我们先尝试下一种提示技术:思路链(CoT)推理;这种技术虽然对原始提示词修改不多,但事实证明却...……更多
2024-09-10 13:39:00从头,人工,提示,指南,工程,提示
...模型预测的有效性,确保模型能准确反映市场动态。采用准确率、召回率等评估指标,对模型性能进行量化衡量,是这个阶段的关键操作。金融领域对预测准确性的要求极高,因此,模型要持续优化和更新以适应市场变化。(二)...……更多
2024-04-13 05:53:00优势,驱动,金融,应用,分析,数据
...反馈,不断优化数据模型和算法,提高风险识别和预警的准确率。同时,根据实际业务需求和市场变化,持续改进数据管理流程和方法,提升金融风险数据资产的管理水平。信息化在金融风险数据资产建设方面发挥着重要作用。...……更多
2024-01-22 11:43:00风险管理,信息化,风险,金融,应用,管理

...多学科多模态理解和推理(MMMU)基准测试中取得了69.1%的准确率。不过,基准测试结果是否真的能反映模型对多样化主题的深入理解,仍然有争议,或者说模型是否只是利用了统计模式,而非依靠理解和推理的情况下就能得出正...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本

...主研发的 AIGC HR 行业大模型和多模态算法,人机对比实验准确率超 92%,在国际处于技术领先水平,但却在融资和业务拓展中遭遇重重困难。在 AI 招聘的蓝海市场中,作为一家创业期的 AI 招聘公司,近屿智能如何向客户证明 AI ...……更多
2023-10-31 21:02:00还是,公司,算法,招聘,智能,候选人
...键步骤。统计学方法提供了各种性能指标,如均方误差、准确率、召回率和F1分数等,用于衡量模型的性能。这些指标允许我们量化模型的预测能力,并对不同模型进行比较。通过统计学方法,我们可以确定哪种模型在特定任务...……更多
2024-01-27 03:05:00人工智能,统计学,人工,策略,统计,智能

...的批评意见更长时,也更容易出现幻觉。这有点类似于「准确率」和「召回率」之间的权衡。FSBS能够激励CriticGPT在产生更长、更全面的批评时,减少「无中生有」或者「鸡蛋里挑骨头」的发生率。之后进行的消融实验也证明了FS...……更多
2024-07-01 09:23:00力作,批评,团队,模型,人类,训练

...一组新的 101 个 LitQA2 问题。PaperQA2 在原始 147 个问题上的准确率与后一组 101 个问题的准确率没有显著差异,这表明在第一阶段的优化已经很好地推广到了新的 LitQA2 问题(下表 2)。
PaperQA2 性能分析研究者尝试改变 PaperQA2 的参...……更多
2024-09-13 13:33:00博士后,模型,科研,博士,检索,能力

...是希望actor能生成更好的响应,但训练效率依赖于judge的准确率。因此,meta-judge作为训练judge的角色,可以同时提升模型作为actor和judge的性能。这三种角色组成的迭代训练模式如图1所示,在第t个步骤中,先收集模型M_t对提示x的...……更多
2024-08-01 09:40:00三角,进化,模型,奖励,训练,迭代

...答中“满口跑火车”,甚至“造谣”。图源Pixabay防止AI大模型出现这种行为并非易事,且是一项技术性的挑战。不过据外媒Marktechpost报道,谷歌DeepMind和斯坦福大学似乎找到了某种变通办法。研究人员推出了一种基于大语言模型...……更多
2024-04-01 11:59:00事实,评估,搜索,事实,机器人,模型
...。经过测试,大模型能在一两秒内快速检索百万级数据,准确率高达95%。刘宏斌表示,CARES Copilot 1.0目前已在香港多家医院的不同科室进行了实地测试和优化,验证了其作为手术智能辅助工具的基础功能和关键技术。下一步,研...……更多
2024-04-01 02:22:00模型,开放,中国科学院,香港,模型,医疗

...目已落地丽水,通过AI辅助当地医生提高多种癌症的筛查准确率和效率。AI技术在临床医学上的应用正在提速,这让生物医疗领域的未来有了更多想象空间,也让从前不可及的前沿医学成果快速实现转化,让普通百姓受益。“罗...……更多
2024-03-15 05:43:00钥匙,医疗,甲状,罗定,甲状腺,天南

...;模型也能够从解析后的屏幕中利用更多信息,动作预测准确率更高。因此,OmniParser结合了微调后的可交互图标检测模型、微调后的图标描述模型以及光学字符识别(OCR)模块的输出,可以生成用户界面的结构化表示,类似于...……更多
2024-10-28 09:51:00贾维斯,贾维,时代,电脑,模型,图标

...的新标准。特别是在 MMLU 上,预训练版本实现了 84.0% 的准确率。代码与推理Mistral AI 基于此前 Codestral 22B 和 Codestral Mamba 的经验,在很大一部分代码上训练了 Mistral Large 2。Mistral Large 2 的表现远远优于上……更多
2024-07-26 09:36:00模型,基准,多语,测试,性能,生成

用ChatGPT诊断疾病,准确率已经超过了人类医生?!斯坦福大学等机构进行了一轮随机临床试验,结果人类医生单独做出诊断的准确率为74%。在ChatGPT的辅助之下,这一数字提升到了76%。有意思的是,如果完全让ChatGPT“自由发挥...……更多
2024-11-19 09:43:00准确率,人类,疾病,医生,病例,医生

...绩直接惨不忍睹,表现最好的Command R(simple)只有22.47%的准确率。——要知道,这考试瞎蒙也能得25分(四选一)。
当然,这也说明人家不是瞎蒙的,确实动脑子了。视觉上的长上下文另一篇研究来自UCSB,考察的是视觉大模型...……更多
2024-07-23 17:12:00正确率,长上,下文,模型,只是,能力
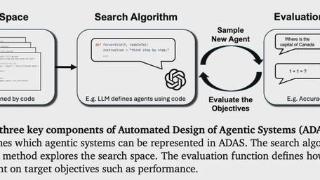
...分数提高了 13.6/100(与基线比),在 MGSM 的数学任务中将准确率提高了 14.4%。此外,在跨域迁移后,它们在 GSM8K 和 GSM-Hard 数学任务上的准确率分别比基线提高了 25.9% 和 13.2%。与手工设计的解决方案相比,本文算法表现出色,这...……更多
2024-08-24 09:36:00设计,手工,数学,智能,智能,元智
...口;在转化环节,全程负责模型研发,动态评估线索推送准确率,迭代式推进模型完善。三是线索集中管理。构建数字办统一推送数字监督线索、业务部门实际开展个案监督或部署专项监督的良性互动机制。确定专人管理线索制...……更多
2024-04-24 07:38:00多维度,多维,路径,数字,监督,检察
更多关于科技的资讯:

快科技2月11日消息,今天下午,金晨惊喜亮相三星Galaxy S25系列发布会现场,网友纷纷点赞:“金晨美若天仙”。据悉
2025-02-11 16:48:00

快科技2月11日消息,蔚来汽车首款车型萤火虫的内饰图首次曝光,预计4月上市,预售价14.88万元。从此次曝光的照片来看
2025-02-11 17:18:00

快科技2月11日消息,今天京东官方宣布,京东外卖正式启动“品质堂食餐饮商家”招募,在2025年5月1日前入驻的商家,更可以全年免佣金
2025-02-11 17:18:00

近日,有不少营销号表示在拍摄《蛟龙行动》时,因为台词涉及国家机密,所以导演和演员说台词的时候只能口述,还要防止被外籍演员听到
2025-02-11 17:18:00

快科技2月11日消息,一个人能捅出多大的篓子?据长沙电视台政法频道报道,南京的屈先生2023年购买了一辆宝马X7,总价100多万
2025-02-11 17:18:00

快科技2月11日消息,乘联分会文章表示,2025年2月中国乘用车市场销量预计将保持稳步增长,新能源汽车将成为主要驱动力
2025-02-11 17:18:00
快科技2月11日消息,据媒体报道,近期,美国初创公司“基础机器人实验室”开发的军用人形机器人“幻影1号”出现在了旧金山一家夜总会
2025-02-11 17:18:00

无论东方还是西方,作为一类动物,蛇类常常被视作一个整体,人们对具体种类的区分并不特别在意。毕竟它们有着鲜明的共同特征——都是食肉动物
2025-02-11 17:18:00
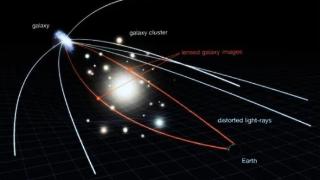
快科技2月11日消息,“爱因斯坦环”是一种非常罕见、极为壮观的天文现象,是引力透镜现象的直接体现,以往曾被发现过,而最新的NGC 6505星系展现了一个几乎完美的“爱因斯坦环”
2025-02-11 17:18:00

快科技2月11日消息,据报道,郑州中牟的王先生在郑州中升奔驰4S店购买了一辆奔驰E300,后来在一次保养时发现该车曾经销售过
2025-02-11 17:18:00
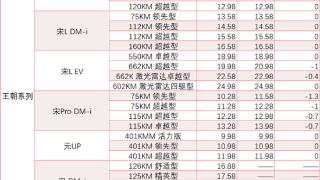
财联社2月11日讯(记者 徐昊)比亚迪在蛇年一开年便打出“王炸”。2月10日,比亚迪发布“天神之眼”技术矩阵,并宣布全系车型将搭载高阶智驾技术
2025-02-11 17:18:00

快科技2月11日消息,日前,华为与上汽集团合作的消息引发关注。据报道,双方合作模式将采用智选车模式,新品牌名为“尚界”
2025-02-11 17:48:00

一、前言:全球首发高频骁龙8至尊版自Galaxy S23 Ultra以来,三星便首发高频版骁龙8系旗舰平台,至今已延续三代
2025-02-11 17:48:00

快科技2月11日消息,据报道,截止2月10日晚,《哪吒2》总票房(含预售)突破86亿,进入全球影史票房榜前30名。该片不仅点燃了手办盲盒
2025-02-11 18:18:00

快科技2月11日消息,上汽通用汽车今日宣布,成为首家将DeepSeek-R1推理大模型深度融入智能座舱的合资车企。近期
2025-02-11 18:18:00