- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...型FLAMe系列,FLAMe-RM-24B模型在RewardBench上表现卓越,以87.8%准确率领先GPT-4o。大语言模型都卷起来了,模型越做越大,token越来越多,输出越来越长。那么问题来了,如何有效地评估大语言模型的长篇大论呢?要是输出长度长了但...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...学场景。
所有数据和代码、模型均已开源。MMedBench 上的准确率,图 d 展⽰了在 MMedC 上进⼀步预训练使模型性能相⽐于基线显著提升。大规模多语医疗语料(MMedC)构建在构建数据集方面,研究团队收集了一份多语言医疗语料库...……更多
2024-09-30 09:51:00多语,大规,模型,语料,基准,大规模

...T4-8k、GPT3.5-turbo-6k、LlamaIndex这种商业模型,平均只有40%的准确率。而像开源模型表现就更不理想了…ChatGLM2-6B、LongLLaMa-3B、RWKV-4-14B-pile、LLaMA-7B-32K平均只有10%的准确率。目前该论文已被ACL 2024接……更多
2024-08-08 09:39:00基准,北大,生成,模型,文本,评估
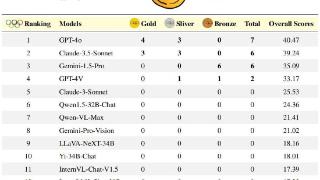
...过基于规则的匹配进行评估,研究团队对非编程任务使用准确率,并对编程任务使用公正的pass@k指标,定义如下:
本次评估中设定k = 1且n = 5,c表示通过所有测试用例的正确样本数量。奥林匹克竞技场奖牌榜:与奥运会使用的...……更多
2024-06-25 09:45:00奥林,奥林匹克,竞赛,模型,推理,能力

... 作为备选。最终的报告结果将基于得分转换为 0 到 100 的准确率指标。未来也可以在我们动态更新的榜单里查看多模态模型在每个月动态更新的最新评测数据,以及在榜单上的最新评测的结果。 ……更多
2024-08-22 09:50:00模态,框架,模型,评测,污染,成本

...数据融合进核保预测模型中,不断修正核保结论,训练核保准确率。这种基于数据的分析和修正过程,使得平安保险核保系统能够准确地评估风险,提高核保的效率和准确性。面对保险行业核保场景新一轮的挑战,平安保险始终与时俱...……更多
2023-11-07 19:58:00平安保险,多维,平安,立体,评估,学习

...贝叶斯算法学习曲线,红色线代表测试集(学习过程中)的准确率(Score),绿色线代表该模型在测试集上的准确率,线两侧的半透明带的宽度代表方差(方差越小,模型稳定性越好,泛化性能越好)。从图1可看出,随着训练量(Train examp...……更多
2024-08-26 09:59:00性能分析,算法,电子邮件,性能,常见,邮件

...的 LongVILA 模型在 1400 帧的大海捞针实验中实现了 99.5% 的准确率,相当于 274k 个 token 的上下文长度。此外, MM-SP 系统可以有效地将上下文长度扩展到 200 万个 token 而无需梯度检查点,与环形序列并行(ring sequence parallel……更多
2024-08-22 09:51:00英伟,准确率,支持,视频,序列,训练

...估了模型的性能,结果显示相比现有方法,RecDiff在推荐准确率方面取得了显著提升。未来,RecDiff团队计划将RecDiff拓展到更多推荐场景中,并结合多模态信息,进一步探索该模型的潜力和应用价值。论文:http://github.com/HKUDS/RecDif...……更多
2024-07-30 09:31:00社交,实验室,模型,实验,智能,数据

...评估AI智能体在计算可重复性方面的表现,最简单任务的准确率可以达到60%,最难任务准确率仅有21%大模型的能力越来越强,用户在一些重要的任务中也可以依赖大模型,比如说辅助做科研。不过现有科研辅助相关的基准测试都...……更多
2024-09-26 13:38:00普林,普林斯顿,斯顿,准确率,基准,科学家
...e given problem about geometric shapes.」可以看到,性能并不好,准确率只有 36%,应该有很大的改进空间。不过,在使用 APE 之前,让我们先尝试下一种提示技术:思路链(CoT)推理;这种技术虽然对原始提示词修改不多,但事实证明却...……更多
2024-09-10 13:39:00从头,人工,提示,指南,工程,提示
...模型预测的有效性,确保模型能准确反映市场动态。采用准确率、召回率等评估指标,对模型性能进行量化衡量,是这个阶段的关键操作。金融领域对预测准确性的要求极高,因此,模型要持续优化和更新以适应市场变化。(二)...……更多
2024-04-13 05:53:00优势,驱动,金融,应用,分析,数据
...反馈,不断优化数据模型和算法,提高风险识别和预警的准确率。同时,根据实际业务需求和市场变化,持续改进数据管理流程和方法,提升金融风险数据资产的管理水平。信息化在金融风险数据资产建设方面发挥着重要作用。...……更多
2024-01-22 11:43:00风险管理,信息化,风险,金融,应用,管理

...多学科多模态理解和推理(MMMU)基准测试中取得了69.1%的准确率。不过,基准测试结果是否真的能反映模型对多样化主题的深入理解,仍然有争议,或者说模型是否只是利用了统计模式,而非依靠理解和推理的情况下就能得出正...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本

...主研发的 AIGC HR 行业大模型和多模态算法,人机对比实验准确率超 92%,在国际处于技术领先水平,但却在融资和业务拓展中遭遇重重困难。在 AI 招聘的蓝海市场中,作为一家创业期的 AI 招聘公司,近屿智能如何向客户证明 AI ...……更多
2023-10-31 21:02:00还是,公司,算法,招聘,智能,候选人
...键步骤。统计学方法提供了各种性能指标,如均方误差、准确率、召回率和F1分数等,用于衡量模型的性能。这些指标允许我们量化模型的预测能力,并对不同模型进行比较。通过统计学方法,我们可以确定哪种模型在特定任务...……更多
2024-01-27 03:05:00人工智能,统计学,人工,策略,统计,智能

...的批评意见更长时,也更容易出现幻觉。这有点类似于「准确率」和「召回率」之间的权衡。FSBS能够激励CriticGPT在产生更长、更全面的批评时,减少「无中生有」或者「鸡蛋里挑骨头」的发生率。之后进行的消融实验也证明了FS...……更多
2024-07-01 09:23:00力作,批评,团队,模型,人类,训练

...一组新的 101 个 LitQA2 问题。PaperQA2 在原始 147 个问题上的准确率与后一组 101 个问题的准确率没有显著差异,这表明在第一阶段的优化已经很好地推广到了新的 LitQA2 问题(下表 2)。
PaperQA2 性能分析研究者尝试改变 PaperQA2 的参...……更多
2024-09-13 13:33:00博士后,模型,科研,博士,检索,能力

...是希望actor能生成更好的响应,但训练效率依赖于judge的准确率。因此,meta-judge作为训练judge的角色,可以同时提升模型作为actor和judge的性能。这三种角色组成的迭代训练模式如图1所示,在第t个步骤中,先收集模型M_t对提示x的...……更多
2024-08-01 09:40:00三角,进化,模型,奖励,训练,迭代

...答中“满口跑火车”,甚至“造谣”。图源Pixabay防止AI大模型出现这种行为并非易事,且是一项技术性的挑战。不过据外媒Marktechpost报道,谷歌DeepMind和斯坦福大学似乎找到了某种变通办法。研究人员推出了一种基于大语言模型...……更多
2024-04-01 11:59:00事实,评估,搜索,事实,机器人,模型

...目已落地丽水,通过AI辅助当地医生提高多种癌症的筛查准确率和效率。AI技术在临床医学上的应用正在提速,这让生物医疗领域的未来有了更多想象空间,也让从前不可及的前沿医学成果快速实现转化,让普通百姓受益。“罗...……更多
2024-03-15 05:43:00钥匙,医疗,甲状,罗定,甲状腺,天南
...。经过测试,大模型能在一两秒内快速检索百万级数据,准确率高达95%。刘宏斌表示,CARES Copilot 1.0目前已在香港多家医院的不同科室进行了实地测试和优化,验证了其作为手术智能辅助工具的基础功能和关键技术。下一步,研...……更多
2024-04-01 02:22:00模型,开放,中国科学院,香港,模型,医疗

...的新标准。特别是在 MMLU 上,预训练版本实现了 84.0% 的准确率。代码与推理Mistral AI 基于此前 Codestral 22B 和 Codestral Mamba 的经验,在很大一部分代码上训练了 Mistral Large 2。Mistral Large 2 的表现远远优于上……更多
2024-07-26 09:36:00模型,基准,多语,测试,性能,生成

...绩直接惨不忍睹,表现最好的Command R(simple)只有22.47%的准确率。——要知道,这考试瞎蒙也能得25分(四选一)。
当然,这也说明人家不是瞎蒙的,确实动脑子了。视觉上的长上下文另一篇研究来自UCSB,考察的是视觉大模型...……更多
2024-07-23 17:12:00正确率,长上,下文,模型,只是,能力
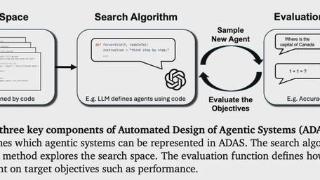
...分数提高了 13.6/100(与基线比),在 MGSM 的数学任务中将准确率提高了 14.4%。此外,在跨域迁移后,它们在 GSM8K 和 GSM-Hard 数学任务上的准确率分别比基线提高了 25.9% 和 13.2%。与手工设计的解决方案相比,本文算法表现出色,这...……更多
2024-08-24 09:36:00设计,手工,数学,智能,智能,元智
...口;在转化环节,全程负责模型研发,动态评估线索推送准确率,迭代式推进模型完善。三是线索集中管理。构建数字办统一推送数字监督线索、业务部门实际开展个案监督或部署专项监督的良性互动机制。确定专人管理线索制...……更多
2024-04-24 07:38:00多维度,多维,路径,数字,监督,检察
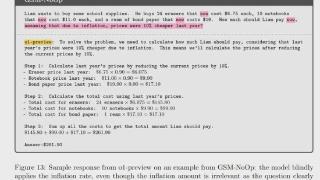
...据集之间,模型存在显著的性能波动,以及与原始 GSM8K 准确率相当的性能下降。这种差异表明,大型语言模型所采用的推理过程可能不是形式化的,因此容易受到某些变化的影响。一个可能的解释是这些模型主要专注于分布内...……更多
2024-10-14 09:55:00数学题,推理,废话,苹果,数学,小学

...面的多维度评估体系是必要的。这不仅涉及一般技术中的准确率、查全率等指标,还需深入考量系统在跨语言法律推理中的一致性表现,及其在面临罕见案例或新兴法律问题时的灵活适应能力。在部署与应用阶段,涉外法律大模...……更多
2024-06-03 02:34:00人工智能,涉外,法治,人工,智能,建设

...)两部分作为上下文信息,模型能还原出被遮住的文字的准确率。蓝色框内表示仅包含图像中的文字(TEI)的作为上下文信息,并不包含图像(VI),模型能还原出的遮住文字的准确率。
结果表明:绝大多数模型目前都不能胜...……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务
...于机器学习建立的暴雨灾害人口损失预估模型,分类预测准确率达89.6%;建立了城市洪涝风险评估模型,并以石家庄为例构建了城市积水模拟模型。在团队的不懈努力下,最终形成了整体面向多承灾体的影响评价技术体系,研究...……更多
2023-11-01 11:08:00灾害,暴雨,评估,风险,减灾,风险评估
更多关于科技的资讯:
20日,国家人工智能应用中试基地(医疗)·浙江正式开园并发布系列重大成果。其中,浙江省推出的全国首个数实融合的“安诊儿”医疗智能体升级至3
2025-12-21 07:20:00
河北日报讯(见习记者康晓博)12月19日,中国气象局在雄安新区发布气象人工智能科学模型“风源”(以下简称“风源”)。该模型将通过提供开源开放科创平台底座
2025-12-20 08:21:00
2025年,港交所成为中国机器人企业的上市“热土”。据不完全统计,年初至今,超30家机器人相关企业向港交所递交申请表,业务范围覆盖核心零部件
2025-12-20 08:23:00
鲁网12月19日讯为加快数字人民币业务拓展,提升数字钱包渗透率,抢占支付市场与同业市场,工商银行泰安分行精心组织、强力推进数字人民币单位钱包拓展工作
2025-12-20 09:07:00

大皖新闻讯 城市地面下的空洞、裂缝和其他隐蔽灾害如若未被及时发现,会存在一定的安全隐患。12月20日,大皖新闻记者从中国科学技术大学获悉
2025-12-20 11:05:00
12月15日,工信部正式公布我国首批L3级有条件自动驾驶车型准入许可,两款分别面向城市拥堵场景和高速公路场景的车型将在北京
2025-12-20 12:13:00
鲁网12月20日讯为进一步提高服务水平,提升业务竞争力,莱芜农商银行高新区公司业务营销中心优化办贷流程,坚持“我们多跑趟
2025-12-20 15:11:00

大皖新闻讯 几天前,关于合肥要造火箭的消息引发外界广泛关注,背后则是合肥星火空间科技有限公司(以下简称星火空间)落户合肥新站高新区
2025-12-20 15:13:00

鲁网12月20日讯为进一步深化“以客户为中心”的服务理念,提升金融产品渗透率与客户满意度,近日,莱芜农商银行钢城区公司业务营销中心精心策划并开展了一场主题为“金融惠民进厅堂
2025-12-20 15:13:00
鲁网12月20日讯为强化基础营销工作,深入推进“做小做散”战略,莱芜农商银行公司金融部全面开展“千企万户大营销”基础工作专项活动
2025-12-20 15:13:00
鲁网12月20日讯小微企业是区域经济发展的“毛细血管”,是稳就业、保民生的重要支撑。作为扎根本土的金融机构,莱芜农商银行营业部始终坚持以优质信贷服务支持辖内小微企业发展
2025-12-20 15:14:00
日前,晋塔塔式起重机远程智能辅助驾驶系统正式在太原“锦绣汾东”落地应用,这是太原首次投入使用的塔式起重机智能辅助驾驶系统
2025-12-20 17:48:00

由吉林省委命题,长春中医药大学校长冷向阳教授牵头制定并实施《落实“AI+中医”具体行动方案》,吉林工商学院副院长赵佳教授领衔
2025-12-20 19:52:00
厦门网讯 (厦门日报记者 林露虹)来自厦门的光通信电芯片“单项冠军”登陆科创板。昨日,厦门优迅芯片股份有限公司在上交所科创板上市
2025-12-20 08:51:00
摘要:随着企业业务复杂度的提升与项目制运营的普及,多项目并行管理成为企业提升效率与竞争力的重要模式。然而,项目间的资源冲突
2025-12-20 05:18:00