- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...但是也有技术缺陷。有时会产生“幻觉”,甚至会犯一些事实性错误。这是大模型技术逻辑带来的天然缺陷,大模型的技术机理是,通过大量的知识训练,基于概率最大的原则生成答案。那么这就带来了几个问题,公开的数据库...……更多
2024-05-13 15:03:00输出,模型,结果,模型,博坦,知识

...码了正确答案,却持续生成错误答案。幻觉,如何定义?事实错误、偏见,以及推理失误,这些统称为「幻觉」。以往,大多数关于幻觉的研究,都集中在分析大模型的外部行为,并检查用户如何感知这些错误。然而,这些方法...……更多
2024-11-11 13:32:00幻觉,内幕,背后,错误,苹果,秘密

...、文本处理、图片编辑三个方向。其中,AI助手测试包括中文普通话语音识别准确度、方言语音识别覆盖率、中文知识储备兼四则运算测试、中文完形填空、中文表述不当纠错、外部信息记忆能力、中文朗读争取性、中文朗读发...……更多
2024-07-06 13:11:00实力,手机,科技,测试,中文,三代

...畴’,甚至其中的部分功能,在行业中已经早有应用。"
中文理解,哪家大模型占优苹果AI浮出水面,随之而来的则是另外一个问题,那就是在国内究竟选择谁作为合作伙伴最为适宜。之前,外界流传百度为国行版iPhone16、Mac系...……更多
2024-06-13 09:23:00合伙人,中国,苹果,苹果,模型,讯飞

...Turbo进行3轮对话,用证据驳斥阴谋论观点研究假设,基于事实性、纠正性信息的论据可能会显得无效,因为它们缺乏足够的深度和个性化。为了验证这一假设,研究人员利用了大语言模型的进步,这是一种AI,能够获取大量信息...……更多
2024-09-18 13:33:00谣言,阴谋,漏洞,封面,模型,阴谋

...比评测报告,声称是首个直接对比 AMD 和英伟达 AI 集群的基准评测。该报告的数据来自 MLCommons,这是一个由供应商主导的评测机构。他们构建了一套 MLPerf AI 训练和推理基准。AMD Instinct 「Antares」 MI300X GPU 以及英伟达的「Hopper」H.……更多
2024-09-05 09:49:00英伟,模型,英伟,内存,推理,性能

...中文大模型。同时,通义千问1100亿参数开源模型在多个基准测评收获最佳成绩,超越Llama-3-70B,成为开源领域最强大模型。历经一年多追赶,国产大模型终于进入核心竞技场,可与国外一流大模型一较高下。奋力追赶一年,成就...……更多
2024-05-09 12:00:00通义,阿里,性能,通义,模型,阿里

...型安全领域两项国际标准发布全球AI安全评估测试有了新基准随着人工智能系统,特别是大语言模型成为社会各方面不可或缺的一部分,以一个全面的标准来解决它们的安全挑战变得至关重要。◎本报记者 崔 爽第27届联合国科技...……更多
2024-04-25 04:00:00基准,评估,测试,安全,全球,人工智能

...。OpenAI表示,新模型在物理、化学和生物等学科的挑战性基准测试中,表现超过人类专家。在国际数学奥林匹克(IMO)资格考试中,新模型得分超83%,远高于GPT-4o的13%。在Codeforces编程竞赛中,o1模型的成绩达到了前89%,而GPT-4o仅...……更多
2024-09-13 16:44:00复旦,相关性,概率,推理,模型,教授
...天机器人“巴德”(Bard)的首次公开演示中犯了令人尴尬的事实性错误。这些人工智能工具应用如此广泛——出错的机会如此之多——引发了人们的兴趣、争论、焦虑和兴奋。“这是人类首次真正地与电脑对话,”美国研究机构和...……更多
2023-12-30 07:56:00人工智能,人工,对话,智能,人工智能,生成

...型有依靠自身无法解决的“幻觉”问题,导致了准确性和事实性无法保证。所以对它的使用需要有所限定,在对可靠性和真实性要求不高的情况下非常有用。针对大模型也不擅长做数学计算,王文广说:“我的建议是,可以通过...……更多
2023-12-21 18:02:00腾讯,风向,模型,业界,应用,专家

...量低于 Llama 3.1 的 4050 亿,但两者性能接近。并且在多个基准测试中与 GPT-4o、Anthropic 的 Claude 3.5 Sonnet 媲美。今年 2 月,Mistral AI 推出了最初的 Large 模型,其上下文窗口包含 32,000 个 token,新版模型在此……更多
2024-07-26 09:36:00模型,基准,多语,测试,性能,生成

...100多万专属评测数据集,评测结果客观性跻身国内外主流基准第一阵营。依托自研大模型评测智能体,支持评测数据自学习、用例自编排、执行自适应,同比评测周期缩短90%以上,已服务政府部委、重点央企,将为更多合作伙伴...……更多
2024-05-25 07:21:00潮起,模型,中国,中国移动,移动,模态

...越重要。百融云创参加的这场“考试”名叫检索增强生成基准测评,这是对大模型处理“幻觉问题”的能力测评,也是对大模型生成内容准确性的测评。尽管大模型带来令人兴奋的技术进步,但“幻觉”一直是制约其发展的主要...……更多
2024-03-28 16:16:00精度,幻觉,模型,结果,模型,幻觉

...-4V在奋力追平GPT-4V的同时,LLaVa-1.6也展现出强大的零样本中文能力。LLaVa-1.6不需要额外训练便具备杰出的中文理解和运用能力,其在中文多模态场景下表现优异,使得用户不必学习复杂的“prompt”便可以轻松上手,这对于执行“...……更多
2024-02-10 21:04:00性能,模型,模态,训练,数据,卷上
...力强项,比如,背靠今日头条和抖音的豆包,更擅长解答事实性、日常性的问题,也试图以轻松、有趣的互动体验作为差异化竞争点。相比之下,腾讯元宝可能会获得专业人士们的青睐,只不过这也有可能限制其在大众用户中的...……更多
2024-06-03 16:59:00腾讯,元宝,波澜,助手,腾讯,元宝

...批社区成员单位共同发布了国内首个运维大语言模型评测基准OpsEval。中科院计算机网络信息中心副研究员裴昶华对OpsEval的社区定位、榜单结果解读以及后续规划进行了分享。目前OpsEval已经拥有近一万七千道多场景评测题目,评...……更多
2023-12-20 13:45:00挑战赛,决赛,成功,国际,模型,南开大学
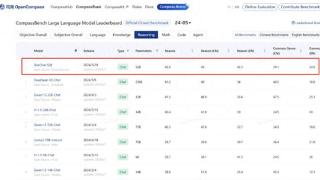
...会(CCL2024)挑战赛两项冠军:TeleAI 在 CCL2024 大会上获得中文空间语义理解评测和古文历史事件类型抽取评测两项第一名。其中,在古文历史事件类型抽取评测任务挑战赛中,更是在所有子任务均取得第一名的情况下获得了综合...……更多
2024-09-30 09:50:00万卡,重磅,模型,国产,训练,模型

本文转自:新华网过去的一个多月中,汽车之家《新能源突破计划》基于深度的用户洞察,拆解消费者对新能源车的需求和痛点,站在用户角度进行评测,以实车对撞、拆解分析、电池包浸水、智能辅助驾驶实际道路测试等实...……更多
2024-01-07 19:44:00新能源,基准,突破,测试,安全,之家

...旨在建立大模型标准符合性名录,是基于官方大模型测试基准的权威评测,被业内称为AI大模型“国标”。受此消息影响,12月25日三六零强势涨停。但26日受大盘整体弱势影响,该股开盘短暂震荡。AI大模型高速发展随着ChatGPT应...……更多
2023-12-26 14:16:00人工智能,国标,人工,模型,结果,智能

...早了1700多年。还有人声称张衡的地动仪能预测地震。但事实上,关于张衡候风地动仪的记载,仅仅只有史书上的196个字。其中描述地动仪内部结构的内容更是只有“中有都柱,傍行八道,施关发机”这12个意义隐晦的字。张衡候...……更多
2024-06-07 17:52:00张衡,地动仪,教科书,教科,地动仪,张衡

...The Information发布的评测报告,AMD的Instinct MI300X GPU在AI推理基准测试中的表现与NVIDIA的H100 GPU相当,显示出AMD在高性能AI计算领域的进步。这份评测报告由MLCommons提供数据,在测试中,AMD的MI300X GPU以及NVIDIA的……更多
2024-09-05 11:09:00逊色,模型,测试,评测报告,戈麦斯,领域
...大学等联合发布了大模型评测体系3.0,暨“方升”大模型基准测试体系。据介绍,测试指标重点强化行业和场景导向的能力考查,提出了自适应动态测试方法,测试数据超过百万条,并首次推出面向行业、通用、应用、安全的评...……更多
2023-12-26 17:41:00信通,人工智能,中国,人工,伙伴,智能

...,依托搜索平台,夸克大模型拥有高质量的各类数据,在中文语境下,模型能力处在行业领先水平。在教育、医疗等垂直领域中,夸克在对话、解题上的能力取得了新的突破,是国产自研大模型的优秀代表之一。同时,在安全性...……更多
2023-11-24 13:53:00夸克,模型,量级,榜首,评测,性能

...要好。
最后,与开源模型一起,Mistral还贡献了一个开源基准测试MM-MT-Bench,用于在实际场景中评估视觉语言模型。技术细节当前的多模态大模型基本上都是:模态编码器 + 投影模块 + 大语言模型主干。如果需要多模态输出,后...……更多
2024-11-20 09:43:00模态,竞技场,竞技,报告,技术,模态

...性消息——结果没多久,Reflection 70B就被打假了:公布的基准测试结果和他们的独立测试之间存在显著差异。无论是AI研究者,还是第三方评估者,都无法复现Matt Shumer所声称的结果。根据Artificial Analysis的数据,Reflection 70B在基准...……更多
2024-10-08 09:47:00神坛,光速,团队,世界,模型,基准

...日新·商量”又拿了金牌!今日,中文多模态大模型测评基准SuperCLUE-V发布10月榜单:商汤日日新·商量多模态大模型(SenseChat-Vision5.5)凭借多个任务上的出色表现,总得分位列国内大模型第一梯队,智夺金牌。商量多模态大模型...……更多
2024-10-14 13:34:00商汤,模态,基准,模型,模型,能力

...架构。以下两张表总结了 MMCL 方法的详细属性。数据集和基准大多数 MMCL 数据集是从最初为非连续学习任务设计的知名数据集中改编而来的,研究人员通常会利用多个数据集或将单个数据集划分为多个子集,以模拟 MMCL 环境中的...……更多
2024-11-14 09:46:00模态,清华,中文,联合,学习,模态
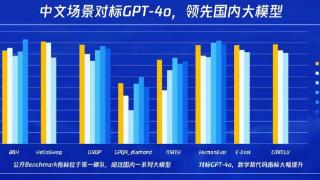
...升100%,推理成本降低50%,解码速度提升20%,效果在多个基准测试上对标GPT-4o,第三方测评居国内第一。在腾讯全球数字生态大会上,腾讯公司副总裁、云与智慧产业事业群COO兼腾讯云总裁邱跃鹏宣布,腾讯混元Turbo在腾讯云上线...……更多
2024-09-05 17:29:00腾讯,新一代,模型,定价,性能,腾讯
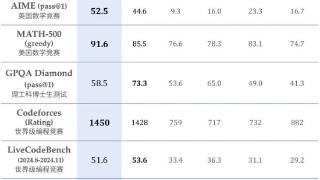
...仅支持网页使用,没有发布完整代码供独立第三方分析或基准测试,也没有通过 API 提供 DeepSeek-R1-Lite-Preview 以进行同类独立测试,也没有解释 DeepSeek-R1-Lite-Preview 是如何训练或构建的博客文章或技术论文,大家心中其实还有许多...……更多
2024-11-22 09:50:00推理,性能,再次,重点,模型,推理
更多关于科技的资讯:

北京,2025年9月24日——北京 CBD 核心区再添重磅力作!今日,备受瞩目的 Z3 超甲级写字楼项目正式揭开神秘面纱
2025-09-25 13:43:00

9月19日,中国电信山东公司、天翼物联科技公司与青岛海信日立在青岛举行联合实验室揭牌仪式,标志着三方战略合作迈入全方位深度融合的新阶段
2025-09-25 13:43:00

9月24日至26日,全球云计算与 AI 领域年度旗舰盛会 ——2025 云栖大会在杭州云栖小镇盛大启幕。本届大会以“云智一体・碳硅共生”为核心主题
2025-09-25 13:44:00
为落实《个人征信电子授权安全技术指南》(JR/T 0299—2024)金融行业标准,规范金融机构在个人征信电子授权中的技术操作
2025-09-25 13:44:00

秋意渐浓,北京迎来一场文玩行业盛会。9月24日至28日,以“国潮觉醒 文玩新生”为主题的2025全国文玩大会于潘家园市场(西区)盛大举行
2025-09-25 13:46:00
如今,微短剧已然从“内容新贵”成长为拉动数字经济的重要力量。因为“轻、快、密”的内容节奏,短剧得以迅速占领用户的碎片时间
2025-09-25 13:46:00

日前,北京市工商联、通州区人民政府联合召开2025北京民营企业百强发布会。会上,网易有道凭借持续的创新能力和稳健的业绩表现
2025-09-25 10:06:00

近日,首批龙晶PR型有晶体眼人工晶状体植入手术在济南爱尔眼科医院完成,作为“尝鲜吃螃蟹”的人,患者脸上洋溢着发自内心满意的微笑
2025-09-25 11:20:00
观赛有了更佳的趣味性与沉浸感金科院数字科技赋能国际赛艇大赛南报网讯(通讯员陆慧记者姜静实习生黄佳琪)2025南京·大学生国际赛艇公开赛近日在外秦淮河畔举行
2025-09-25 07:38:00
提升“双盲”模式下的评标质效雄安新区面向评标专家智能问答系统正式上线河北日报讯(见习记者康晓博)只需轻点鼠标,远在外地的评标专家就能获得精准指引
2025-09-25 07:58:00

大模型算出爆款,红枣变致富“金枣”——看沧县红枣及干坚果食品加工产业如何实现数字化转型9月18日,河北华聚食品有限公司的工人忙着打包红枣产品
2025-09-25 07:59:00
9月17日,兴业银行信用卡中心与美团企业版在上海签署战略合作协议,共同打造“金融+生活”开放生态。根据协议,双方将基于开放共享
2025-09-24 07:24:00
金洽会上51个重点产业项目签约,计划投资802.21亿元——一串串数字,见证企业对南京的高度认可□南京日报/紫金山新闻记者张甜甜9月23日
2025-09-24 08:11:00
5项科技创新成果案例发布芯片设计迎“超强大脑”多癌早筛一管血“搞定”南报网讯(记者张安琪)9月23日,2025南京金洽会开幕式重点发布环节
2025-09-24 08:12:00
在今年国庆、中秋双节消费旺季来临之际,济南122站以“客户体验感”为核心,从“环境优化、商品管理、客户拓展”三大维度精准发力
2025-09-24 08:50:00