- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...加上相应的模态标记。文本数据:[TEXT]这是一个文本句子音频数据:[SPEECH][Hu262][Hu208][Hu499][Hu105]交错语音和文本(Interleaving Speech and Text)对于对齐的语音+文本数据集,通过在单词级别交错语音和文本来混合:[TEXT]th……更多
2024-11-23 09:43:00音频,模态,重磅,文本,任务,情感

...来的人与 AI 交互方式。具体来说,AI 能做到接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合输出。如今,智谱清言的「情感语音通话」又一次推动了国产 AI 对标国际先进水平。情感语音模...……更多
2024-10-26 09:49:00一波,模型,国产,还是,语音,模型
...官米拉·穆拉蒂(Mira Murati)介绍,GPT-4o可以接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合进行输出,其中“o”代表“omni全能”。一直以来,多模态人机交互便是AI领域重点研究发力方向...……更多
2024-05-14 13:59:00进一,模态,易用,易用性,人机,模型

...6725
代码仓库:https://github.com/gpt-omni/mini-omni针对多层级的音频编码方案,本文采用不同层级延迟并行输出的方案减小音频推理长度,有效解决实时性问题。同时还提出了多任务同时推理的生成方法进一步加强模型的语音推理能力...……更多
2024-09-07 09:44:00模型,语音,对话,机构,语音,文本

...高达10,000,000 token的文本时,检索准确性仍然高达99.2%。在音频处理方面,Gemini 1.5 Pro能够在大约11小时的音频资料中,100%成功检索到各种隐藏的音频片段。在视频处理方面,Gemini 1.5 Pro能够在大约3小时的视频内容中,100%成功检索...……更多
2024-02-21 14:05:00劲敌,高产,模式,模型,上下文,处理

...同步性的模型 SyncNet 计算的音画同步置信度。相同的驱动音频和驱动视频,数值越高越好。TTS引擎MeetVoice Pro赋能数字人在第四代数字人系统WetaAvatar 4.0中,用户提交文本后,系统将调用出门问问的TTS引擎MeetVoice Pro,该引擎基于...……更多
2024-04-09 14:00:00重磅,全新,数字,系统,数字,系统

...的独特之处在于:1)Align-Anything 框架支持文本、图像、音频、视频等多种模态的输入和输出对齐,这在目前开源社区中是独一无二的。它填补了现有框架仅支持单一模态或少数模态对齐的空白,为全模态大模型的对齐提供了统...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

...特性,可以从三个方面理解:1.多模态。GPT-4o接受文本、音频和图像的任意组合作为输入,实时对音频、视觉和文本进行推理,生成相应的输出。相比ChatGPT的文生文、文生图,Sora的文生视频等,GPT-4o是一个原生多模态的融合体...……更多
2024-05-19 16:32:00全能,模型,只有,世界,模态,模型
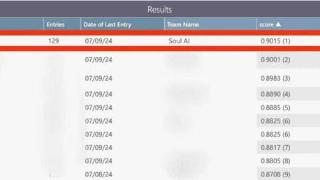
...、语音和视觉多模态,在与社交紧密关联的文字、图片、音频和视频场景齐发力,让用户在立体、多感官的人机互动中体验有温度的 AI。结语2024 年被很多圈内人士称为 AIGC 应用元年,大家关注的焦点不再只是拼参数和基础能力...……更多
2024-08-01 09:34:00模态,拟人,玩家,模态,情感,模型

...性和准确性。想要看懂短视频,除了视觉内容外,语音和音频等听觉信息,如视频音乐、音效、语音内容等,也对短视频的理解起到关键作用。音视频大语言模型(av-LLMs)在近几年取得了显著进展,但语音作为视频中人类语言...……更多
2024-08-01 09:45:00模态,清华,领衔,模型,视频,音视

...趣丸科技在人工智能方面的最新探索成果,以及赋能智能音频和数字安全方面的一些思考。首先,请允许我简单介绍一下趣丸科技。我们是一家成立于2014年的国家高新技术企业,可能有些朋友对我们的兴趣社交产品TT语音和TT电...……更多
2024-05-24 22:22:00模态,生产力,副总,场景,大会,智能

...通过整合跨模态信息,山海多模态大模型能够接收文本、音频、图像等多种形式作为输入,并实时生成文本、音频和图像的任意组合输出。▲云知声山海助手微信小程序IT之家获悉,山海多模态大模型有如下特点:实时秒回,自...……更多
2024-08-27 09:38:00模态,山海,实时,生成,模型,图像

...来里程碑Gemini1.0具有原生多模态的能力,能够处理视频、音频、图像、文本、代码等多种形式的内容,且性能优于现有的“拼接型”多模态大模型。据谷歌介绍,Gemini不仅可以进行双模态之间的转换,也能处理需要进行多模态转...……更多
2023-12-11 15:01:00模态,热潮,产业发展,产业,发展,模态

...术企业展示AI时代云上创新的潮流科技。喜马拉雅珠峰AI音频多模态大模型亮相云栖大会,在“人工智能+”主题馆吸引众多市民驻足围观体验。AI(人工智能)已经在深刻影响着我们的生活,也影响和改变着内容创作行业。作为...……更多
2024-09-21 09:50:00喜马拉雅,创作者,模型,创作,音频,内容

...,随着多模态学习的兴起,研究者们对结合文本、图像和音频等多种数据类型的模型产生了浓厚的兴趣。其中,多模态对比学习成为了这一领域的重要方法,如CLIP和ALIGN等模型利用对比损失训练,以增强图像和文本的相关性,进...……更多
2024-08-02 09:55:00误差,中科院,隐私,方法,数据,学习
...Qwen-72B的开源,通义千问还开源了18亿参数模型Qwen-1.8B和音频大模型Qwen-Audio。开源模型Qwen-1.8B,推理2K长度文本内容仅需3G显存,可在消费级终端部署。Qwen-Audio能够感知和理解人声、自然声、动物声、音乐声等各类语音信号。用...……更多
2023-12-01 13:33:00通义,模态,模型,尺寸,参数,模型

...emini 2.0 Flash,该公司称其除文本外,还能原生生成图像和音频。 2.0 Flash 还可以调用第三方应用程序和服务,使其能够接入 Google 搜索、执行代码等。2.0 Flash 的实验版本将从今天开始通过 Gemini API 和 Google 的人工智能开发者平台AI...……更多
2024-12-12 09:54:00人工智能,人工,模型,用途,全新,智能

...类可以同时处理和整合多种感知数据(例如文本、图像、音频等)的AI架构。据介绍,Monkey模型在18个数据集上的实验中表现出色,特别是在图像描述和视觉问答任务方面,超越了众多现有知名的模型如微软的LLAVA、谷歌的PALM-E、...……更多
2023-12-15 01:14:00华中科技大学,华中,模态,模型,教授,大学

...首个三模态大模型紫东.太初1.0,可以利用文本、图片、音频三种模态数据进行跨模态的统一表征和学习。对应到全模态大模型,泛指可以利用文本、图片、音频、视频、3D等不同模态的数据进行跨模态的统一表征和学习,更接近...……更多
2023-05-12 06:00:00太初,模态,想象力,进化,模型,模态

...探索方向中,“情感AGI”的重要意义。相比文本和图片,音频内容是理解人类情感最好的方式,而音乐又是人类情感表达最充沛、最不受地域和文化限制的内容载体,不论时代变幻,不论是战争还是灾祸,人们总是能通过音乐传...……更多
2024-04-03 11:35:00天工,颠覆,模型,体验,音乐,天工

...型GPT-4 Turbo的两倍,但成本仅为GPT-4 Turbo的一半,视频、音频功能得到改善。OpenAI CEO奥尔特曼(Sam Altman)在博客中表示,ChatGPT免费用户也能用上新发布的GPT-4o。此外,OpenAI还与苹果走到一起,推出了适用于macOS的桌面级应用。Ope.……更多
2024-05-14 14:39:00实测,人机,更快,模型,成本,速度

...,Gemini终于揭开了面纱——展现了其文本、图像、视频、音频和代码的五大能力,一口气推出了大中小三个版本,从云上到手机、平板都可以跑。并且,Gemini还有大量的酷炫用例:AI对一段视频可以做出准确反应,AI能和你玩你...……更多
2023-12-07 08:18:00全能,选手,模型,焦点,分析,模型

...经过一些内部调研,以下是七项GPT-5最具变革性的能力。1音频和视频处理——更强大的多模态处理能力GPT-5比GPT-4更加强大的数据理解能力,可以在多模态理解方面表现更出色。它将延续GPT-4的文本和图像处理功能,同时加入音频...……更多
2023-04-12 14:02:00七大,能力,能力,智能,机器人,模型

...创建过程,同时满足用户的个性化需求。如图像、文本、音频、视频等。AIGC被认为是继UGC(用户生成内容)和PGC(专业生成内容)之后的一种新型内容创作方式。AIGC可以应用于各种领域,如艺术、教育、娱乐、营销等,提供丰...……更多
2023-04-20 16:00:00应用,商业,教育,产品,技术,内容

...惊掉在场所有观众的下巴。在短短232毫秒内,GPT-4o就能对音频输入做出反应,平均为320毫秒。这个反应时间,已经达到了人类的级别!受消息面的催化,今日人工智能AIETF(515070)开盘冲高,截至发稿,人工智能AIETF(515070)涨0....……更多
2024-05-14 12:39:00人工智能,人工,智能,人工智能,人工,智能

...AI技术为基础的多媒体创作垂类大模型,由视频大模型、音频大模型、图片大模型、语言大模型组成,聚焦数字创意垂类创作场景。2月2日,万兴科技在互动平台表示,天幕大模型主要基于公司在数字创意领域二十年的产品开发...……更多
2024-02-19 08:10:00颠覆,布局,行业,视频,公司,模型

...发布会上对外展示,当时发布的新一代大模型GPT-4o集文本音频视觉于一身,支持文本、音频和图像的任意组合作为输入和输出,被OpenAI称为“迈向更自然的人机交互的一步”。根据当时公布的基准测试,GPT-4o在多语言、音频和视...……更多
2024-06-26 11:35:00语音,模型,速度,正在,功能,技术

...味着它接受包括多种媒体类型的输入,组合文本、图像、音频、视频和编程代码。未来,谷歌还计划将 Gemini添加到谷歌搜索引擎和 Chrome 网络浏览器等产品中,而全球有数十亿人在使用这些产品。谷歌首席执行官皮查伊
让GPT-4...……更多
2023-12-07 16:15:00神仙,模型,观察,科技,模型,任务

...实现认知和决策智能的转折点。现实世界的信息是文本、音频、视觉、传感器以及人类各种触觉的综合体系,要更为精准地模拟现实世界,就需要将各种模态能力打通,例如文本-图像、文本-视频等跨模态甚至全模态的综合能力...……更多
2024-03-24 17:44:00李开复,工场,模型,领域,应用,投资

...以多种模态存在——自然语言、程序代码、图像、视频、音频、3D模型、数学符号……这些信息形式各自独立,彼此之间的“对话”几乎不存在。AI虽然能够在单一模态下表现出色,但面对多模态信息时,却往往显得力不从心。...……更多
2024-09-20 09:51:00阿里,生成,统一,语言,世界,模态
更多关于科技的资讯:
大皖新闻讯 记者1月23日从合肥市商务局公告获悉,合肥市商务局拟开展2025年合肥市家电及数码产品“焕新”补贴发放工作
2025-01-23 22:49:00

快科技1月23日消息,今天,演员倪虹洁勇敢地分享了自己一段尘封已久的往事。那是在1999年,她拍摄的一则内衣广告,在那个相对保守的年代
2025-01-23 23:03:00

快科技1月23日消息,凯迪拉克宣布推出其首款纯电动高性能车型——2026款LYRIQ-V,标志着高性能V系列正式迈入电动化时代
2025-01-23 23:33:00

快科技1月23日消息,2025年第97届奥斯卡提名今天正式公布。其中,Netflix出品的歌舞片《艾米莉亚·佩雷斯》可谓最大赢家
2025-01-24 00:03:00

快科技1月23日消息,近日,比亚迪汽车新技术研究院院长杨冬生在内部讲话中分享了对技术研发、管理及制度的看法,并提出了新的工作方向
2025-01-24 00:03:00

快科技1月24日消息,近日,英伟达创始人兼CEO黄仁勋结束了其备受关注的中国之行。据报道,行程结束后,他搭乘私人飞机前往日本
2025-01-24 00:33:00

就在北京时间 1 月 23 号凌晨,三星发布了全新一代 Galaxy S25 系列旗舰手机。用省流的话来说,这一代 S25 系列依旧没啥惊喜
2025-01-24 00:33:00
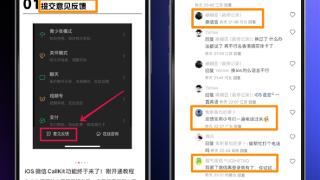
虽然现在就是年底,但这两天微信一个更新,还是让关注微信的网友直呼——过年了因为 “ CallKit 回归了 ” 。不过和往常一样
2025-01-24 00:33:00

快科技1月24日消息,据博主@小马甲不小 透露,小米空调2025年的销量目标是突破1000万台。根据小米此前公布的数据
2025-01-24 00:33:00

快科技1月24日消息,近日,国际标准化组织批准由我国牵头的7项新能源汽车领域国际标准项目立项,涉及电动汽车整车、动力电池
2025-01-24 00:33:00

快科技1月24日消息,下周就要过年了,春节团圆拍上几张合照必不可少。腾讯元宝AI美照正式上线了新年专题,可以让大家一键Get春节大片
2025-01-24 00:33:00
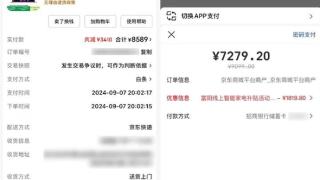
相信不少小伙伴这几天已经刷到新闻,知道新一轮的国补又来了。但这件事,在咱们差评编辑部里,可以说是有人欢喜有人愁。比如去年那轮国补
2025-01-24 00:33:00

快科技1月23日消息,近日,美国家公路交通安全管理局(NHTSA)宣称,已对福特BlueCruise驾驶辅助系统展开工程分析(EA)
2025-01-23 18:33:00

快科技1月23日消息,捷豹路虎首席商务官Lennard Hoornik在接受采访时透露,电动版路虎卫士预计要到2030年前后才会问世
2025-01-23 18:33:00

快科技1月23日消息,据媒体综合报道,今日凌晨,美国计算机协会 ACM(Association for Computing Machinery)公布了最新一届会士名单
2025-01-23 18:33:00