- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。
...了更深的网络。主要差异总结如下:局部滑动窗口和全局注意力。研究团队在每隔一层中交替使用局部滑动窗口注意力和全局注意力。局部注意力层的滑动窗口大小设置为4096个token,而全局注意力层的跨度设置为8192个token。
Logit...……更多
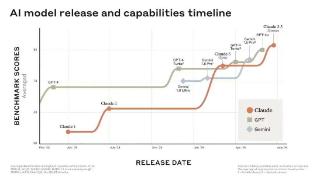
2024-06-29 09:37:00诚意,经济,模型,训练,性能,注意力

...书要分成很多段,然后送去训练。由于大模型训练主要是注意力机制,即注意力参数的训练,只要两个东西相关,就可以发生一个关联。“这是在没有截断的前提下,如果把数据截成8K,第二个8k进来了以后,和第一个8K就没有直...……更多
2024-06-05 13:00:00高文,院士,实验室,模型,训练,实验

...神经架构。在 transformer 模型中,这一目标自然可以通过注意力层和前馈层的组合来实现。因此,作者使用一个仅由几个层组成的轻量级 transformer 作为 patch-mixer。输入序列 token 经 patch-mixer 处理后,他们将对其进行掩蔽(图 2e)...……更多
2024-07-30 09:37:00从头,模型,训练,参数,掩蔽,训练

...及为企业提供更多样化AI选项的市场机会,让科技公司将注意力逐渐转向了SLM。《每日经济新闻》记者注意到,不管是Arcee、Sakana AI和Hugging Face等AI初创公司,还是科技巨头都在通过SLM和更经济的方式吸引投资者和客户。此前,谷...……更多
2024-08-26 14:17:00模型,英伟,微软,模型,训练,性能

...研究人员对纯解码器多模态大模型(如LLaVA)和基于交叉注意力的模型(如Flamingo)进行了全面对比,并根据总结出的优势和劣势,提出了一种全新架构,提升了模型的训练效率和多模态推理能力。文中还引入了一种1-D图块(tile...……更多
2024-09-24 13:36:00英伟,模态,文本,性能,模态,模型
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transfo...……更多
2024-09-03 09:59:00线性,新作,混合,作者,模型,线性

...算顺序等方法近似 Softmax 函数,但仍存在性能不如 Softmax 注意力且可能增加额外开销的情况。线性 RNN 模型线性 RNN 模型如 Mamba 等通过将序列表示为状态空间并利用扫描操作,以线性时间复杂度提供了序列建模的新解决方案。然...……更多
2024-10-16 13:34:00序列,架构,北大,混合,团队,性能

...识库(或任何文本数据集)转换为显式记忆,实现为稀疏注意力键 - 值,然后在推理过程中调用这些内存并将其集成到自注意力层中。新的记忆格式定义了新的记忆层次结构:此外,本文还介绍了一种支持知识外化的记忆电路理...……更多
2024-07-11 09:33:00维南,领衔,院士,新作,模型,存储

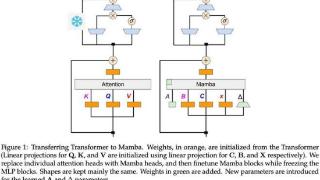
...Mamba在介绍Mamba 2的时候我们讲过,线性RNN(或SSM)跟线性注意力是一回事。所以可以根据x,B,C与V,K,Q的对应关系直接复用注意力中的投影矩阵。
额外的参数包括SSM需要的A矩阵和Δt(由x投影得到),这就完成了基本的参数...……更多
2024-09-06 10:01:00推理,更快,性能,模型,输出,训练

...异构性来优先实现效率和可扩展性,并且扩展性不应受到注意力头数量的限制。
MM-SP 工作流。为了应对模态异构性的挑战,研究者提出了一种两阶段式分片策略,以优化图像编码和语言建模阶段的计算工作负载。具体如下图 4 ...……更多
2024-08-22 09:51:00英伟,准确率,支持,视频,序列,训练

...减少高mask带来的性能下降。在本架构中,patch-mixer是通过注意力层和前馈层的组合来实现的,使用二进制掩码进行mask,整个模型的损失函数为:与MaskDiT相比,这里不需要额外的损失函数,整体设计和训练更加简单。而混合器本...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练

...人工神经元,替换成脉冲神经元。一些关键的操作比如自注意力算子等都被保留,从而让任务性能得到保障。这些早期工作为李国齐团队的工作带来了启发。但是,他们觉得这更像是一种人工神经网络/脉冲神经网络的异构。于...……更多
2024-03-18 10:41:00神经网络,脉冲,架构,科学家,模型,神经

...略,来减轻异常通道引入的量化误差。简单来说就是,对注意力层和FFN层的输入采用4位量化,同时用8位整数稀疏化中间状态。大量实验表明,BitNet a4.8在相同的训练成本下,实现了与前代BitNet b1.58相当的性能,同时因为可以吃...……更多
2024-12-06 09:55:00架构,激活,新一代,模型,突破,激活

...置得与语言模型(Llama3-8B)中的对应块相同,仅包含一个注意力层和一个前馈层,参数也相同,如隐藏维度大小、注意力头的数量和注意力头的维度,并且只训练了图像模型部分。在扩散采样过程中,语言模型部分只需要运行一...……更多
2024-10-08 09:48:00文生,图形设计,深度,图形,人类,参数

...循,自研 3D 视觉编码器支持图像视频混合训练,通过全注意力机制提升画面运镜能力,并根据自研的图像视频 Scaling Law 设计和训练了最优配比模型。模型方法介绍Hunyuan-Video 是一个综合的视频训练系统,涵盖了从数据处理到模...……更多
2024-12-04 09:48:00文生,腾讯,模型,参数,社区,视频
...两个关键组件:跨模态感知的Token修剪器和模态自适应的注意力头修剪器。Token修剪器利用多层感知器(MLP)结构,智能地识别并去除那些对于当前层不重要的Token。这一过程不仅考虑了Token在文本或图像序列中的独立重要性,还...……更多
2024-05-17 13:00:00模态,算法,模型,联合,模态,模型

...《Attention as an RNN》的论文。正如论文名字所示,他们将注意力机制重新诠释为一种 RNN,引入了一种基于并行前缀扫描(prefix scan)算法的新的注意力公式,该公式能够高效地计算注意力的多对多(many-to-many)RNN 输出。基于新公...……更多
2024-10-15 09:56:00图灵奖,图灵,得主,新作,序列,训练
...代Zamba1相比,Zamba2-mini的关键进步之一是集成了两个共享注意力层(attentionlayers)。这种双层方法增强了模型在不同深度保持信息的能力,从而提高了整体性能。在共享注意力层中加入旋转位置嵌入也略微提高了性能,这表明Zyph...……更多
2024-08-30 05:47:00模型,模型,数据,内存,性能,训练
...d》中被首次提出,Transformer的核心优势在于具有独特的自注意力(Self-attention)机制,能够直接建模任意距离的词元之间的交互关系,解决了循环神经网络(RNN)、卷积神经网络(CNN)等传统神经网络存在的长序列依赖问题。相...……更多
2024-10-21 10:03:00模型,行业报告,新纪元,报告,发展,行业

...潜在token的数量。线性DiT(Diffusion Transformer):用「线性注意力」替换了DiT中所有的普通注意力,在高分辨率下更加高效,且不会牺牲质量。基于仅解码器模型的文本编码器:用现代的仅解码器SLM替换T5作为文本编码器,并设计...……更多
2024-10-18 09:49:00英伟,清华,架构,大片,性能,笔记本

...MoE的Scaling Law公式,C ≈ 9.59ND + 2.3 ×108D。又比如用交叉层注意力节省KV缓存的内存占用。下面送上发布会现场演讲和技术报告精华内容总结。Hunyuan-Large技术报告MoE的Scaling Law直接上公式:C ≈ 9.59ND + 2.3 × 108D……更多
2024-11-07 09:54:00腾讯,商用,模型,参数,模型,数据

...自动驾驶模型的可解释性,该团队首次引入人类驾驶员的注意力机制。通过预测当前上下文中的驾驶员注意区域,他们将其作为一个掩码来调整原始图像的权重,从而使自动驾驶车辆能够像经验丰富的人类驾驶员一样,具备有效...……更多
2024-04-11 10:53:00驾驶,认知,科学家,模块,场景,人类

...器是否会被「90% 的人更喜欢回答 A」这样的句子所左右?注意力:自动评估器是否被不相关的上下文信息干扰评估结果如表4所示,可以看到,相比其他基线模型,FLAMe系列在大部分维度都表现出明显较低的偏见,而且总体偏见值...……更多
2024-08-05 09:37:00准确率,模型,评估,评估,模型,数据

...型之间转移,并能降低CLIP模型的性能。可视化分析图5:注意力图可视化:比较四种模型在干净数据和不同方法的不可学习样本上的情况
图5展示了在干净数据和不同方法生成的不可学习样本上训练的模型的注意力热图。对于图...……更多
2024-08-02 09:55:00误差,中科院,隐私,方法,数据,学习

...注意到,过去有许多研究试图解决上述挑战,像是“扩展注意力窗口”,让语言模型能够处理超出预训练序列长度的长文本;或是建立一个固定大小的活动窗口,只关注最近token的键值状态,确保RAM使用率和解码速度保持稳定,...……更多
2023-10-07 00:12:00麻省理工学院,麻省,理工,框架,联合,学院

...加上[IMAGE END]。 FFN中的门控:在隐藏层中使用门控,而非注意力块中的标准前馈层。 序列打包:为了在单个批次中有效地处理图像,作者沿序列维度将图像展平并连接起来,并构建了一个块对角掩码,以确保来自不同图像的patch...……更多
2024-11-20 09:43:00模态,竞技场,竞技,报告,技术,模态

... token 的序列上对模型进行了训练,并使用掩码来确保自注意力不会跨越文档边界。2)训练数据Meta 表示,要训练出最佳的语言模型,最重要的是策划一个大型、高质量的训练数据集。据介绍,Llama 3 在超过 15T 的 token 上进行了预...……更多
2024-04-20 11:03:00模型,训练,参数,数据,全球,模型

...架构在处理较长文本时可能会遇到困难。
Transformer的自注意力机制(Self-Attention)让模型可以关注输入序列中的所有位置,并为每个位置分配不同的注意力权重。这使得模型能够更好地处理长距离的依赖关系,也就是说,对于句...……更多
2024-08-14 09:43:00一鸣,霸主,模型,再次,模型,序列
...基准上实现了 SOTA。ELM-2B 生成的一些不同类别的图像至于注意力模式,不同大小的模型的差别倒是不大:L 大小的模型主要关注局部信息,难以捕获长程信息。相较之下,更大的 XL 和 XXL 模型的某些层表现出了更长程的注意力,...……更多
2024-11-27 13:32:00潜力,模型,图像,起点,领域,还是

...时间序列的周期性特征。这个过程通过构建时间转移多头注意力机制实现——将未来的时空嵌入作为查询(Query),历史的时空嵌入作为键(Key),以及历史的时空数据表示作为值(Value)。
作者引入了RMSNorm来提高训练稳定性...……更多
2024-09-02 13:34:00路况,样本,模型,交通,交通,模型
更多关于科技的资讯:

大皖新闻讯 日前,安徽省量子信息工程技术研究中心发布消息称,我国实现了全球首款四通道超低噪声半导体单光子探测器的量产落地(以下简称“深度制冷单光子探测器”)
2025-10-12 10:52:00

漫步浩瀚太空,秒回侏罗纪时代,与科幻机甲同框……济南方特东方神画“九州神韵”的XR拍摄专区,小学生李安安兴奋地“穿越”在异时空中
2025-10-11 10:21:00
近日,据大象新闻报道,疾控卫监部门在一次突击检查中发现,某美容院将普通的高频电灼仪包装为“黄金微针”项目进行推广。这类看似创新的营销话术
2025-10-11 12:36:00
中新经纬10月11日电 (李自曼)近期,多家险企推出1年期的短期重疾险产品。同样保额下,传统重疾险保费动辄千元甚至上万元
2025-10-11 13:55:00

鲁网10月11日讯近日,中国红十字应急救援北部协作区综合救援演练在山东省滨州市惠民县黄河三角洲应急消防实训基地拉开帷幕
2025-10-11 14:44:00

当碳基生命的创造力与硅基生命的智慧力深度融合,将迸发出怎样的“AI+”可能?2025年10月10日—10月12日,中国移动全球合作伙伴大会在广州保利世贸博览馆盛大召开
2025-10-11 15:31:00

10月10日至12日,2025中国移动全球合作伙伴大会在广州举行。10月11日上午,中国移动董事长杨杰出席大会主论坛,并发表题为《碳硅共生 合创AI+时代》的主旨演讲
2025-10-11 15:31:00

国庆假日期间,北京apm以“沉浸式假日体验”为核心,精心打造多元互动活动、热门IP联名快闪与专属会员福利矩阵,为王府井商圈注入鲜活动能与浓郁假日氛围
2025-10-11 15:41:00

近日,张家口农商银行钟楼北小贷中心积极组织开展一场针对光大新天地商城内各商户的专项走访活动。此次活动旨在深入了解商城内各类商户的经营状况
2025-10-11 16:20:00

2025年国庆长假期间,全国文旅消费市场持续呈现旺盛活力。易生支付凭借高并发交易处理、全渠道聚合支付、实时资金清算等核心技术能力
2025-10-11 17:08:00
齐鲁晚报·齐鲁壹点 连宁燕今年以来,威海市商务局围绕促消费开展了一系列卓有成效的工作。紧跟国家、省级、市级各级各类消费提振部署安排
2025-10-11 17:10:00

新范式·新百川·新未来:20周年发布品牌与战略升级近日,行业专家、合作伙伴及媒体代表逾300人齐聚深圳百川装饰集团20周年现场
2025-10-11 17:11:00

鲁网10月11日讯(记者 泮晓阳)10月11日上午,聊城市政府新闻办公室召开“产业链上的山东好品牌”企业家系列现场记者见面会(六)聊城黑色金属加工
2025-10-11 17:44:00

鲁网10月11日讯(记者 泮晓阳)10月11日上午,聊城市政府新闻办公室召开“产业链上的山东好品牌”企业家系列现场记者见面会(六)聊城黑色金属加工
2025-10-11 17:49:00