- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

AI生成的图像太逼真,为什么不能拿来训练AI呢?可别说,现在还真有人这么做了。来自香港大学、牛津大学和字节跳动的几名研究人员,决定尝试一下能否使用高质量AI合成图片,来提升图像分类模型的性能。为了避免AI合成的...……更多
2023-02-23 12:53:00训练,数据,数据,训练,模型,图像

...绘画侵权,实锤了!最新研究表明,扩散模型会牢牢记住训练集中的样本,并在生成时“依葫芦画瓢”。也就是说,像StableDiffusion生成的AI画作里,每一笔背后都可能隐藏着一次侵权事件。不仅如此,经过研究对比,扩散模型从...……更多
2023-02-03 22:00:00绘画,侵权,模型,照片,模型,训练

...倍的模型相比具有显著竞争力。研究人员使用分类目标预训练的视觉变换器(ViT)模型与对比性预训练的模型(SigLIP)进行了比较,结果发现,PaLI-3 虽然在标准图像分类基准上略微表现不佳,但基于 SigLIP 的 PaLI 在各种多模态基...……更多
2023-10-17 16:31:00更快,模型,视觉,语言,训练,模型
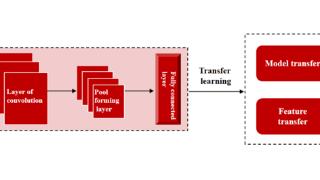
...。然而,由于语义分割任务的复杂性和数据的不足,单独训练一个语义分割模型可能会面临一些挑战,例如模型过拟合、模型泛化能力不足等。为了解决这些问题,微美全息(NASDAQ:WIMI)将迁移学习引入到语义分割模型中。迁移学...……更多
2023-11-15 01:02:00语义,全息,高质量,模型,任务,学习

...究人员首先介绍了指令微调数据的构建,然后则是具体的训练过程。之后,分别从模型和数据的角度阐述了两种提高指令微调性能的技术。为了保证指令微调数据的多样性,同时考虑到它们的可及性,研究人员收集了大量公开可...……更多
2023-05-15 20:17:00团队,华人,指令,数据,模型,研究

...上做出大突破。与DALL・E一样,两点依旧是CLIP模型,除了训练数据庞大,CLIP基于Transformer对图像块建模,并采用对比学习训练,最终帮助DALL・E2取得了不错的生成效果。下图是DALL・E2根据“一只戴着贝雷帽、穿黑色高领毛衣的柴...……更多
2023-01-30 16:34:00生成,模型,新论,代表作,盘点,进展

...,构建了图像分类融合模型,通过利用在大规模数据集上训练的模型的特征表示来提升小样本数据集上的分类性能。深度迁移学习可将已经在大规模数据集上训练好的深度学习模型应用于新的任务中。在图像分类中,深度迁移学...……更多
2023-10-23 16:02:00图像,分类,全息,深度,模型,准确性

...ohnSchulman在接受科技播客主持人DwarkeshPatel采访时透露,后训练是提高模型性能的关键因素。GPT-4o的识图能力有多牛?四大维度深度体验基于图片类型,记者将识图功能的测评分为4大维度,分别为普通图像、特定专业领域的图像...……更多
2024-05-19 14:21:00维度,深度,能力,体验,模型,训练

...增强方法由于其缓解过拟合的特性,而被广泛使用在模型训练过程中,例如图像的旋转、缩放、颜色的改变等等。然而,美国东北大学三年级博士生张一天和所在团队发现作为图像色彩的一个重要属性,色调(Hue)的变化却在现...……更多
2024-05-07 10:12:00东北大学,视频,美国,模型,方法,数据

...套图像分割的通用模型,降低了对于特定场景建模知识、训练计算、数据标记的需求,有望在统一框架下完成图像分割任务。目前Meta公司已经开放共享SAM的代码和训练数据集。
利用海量数据实现准确分割那么,SAM是通过什么技...……更多
2023-04-17 01:26:00模型,图像,杨戈,数据,物体,提示

...s & Insights from Multimodal LLM Pre-training》(MM1: 多模式LLM预训练的方法、分析和见解)中可以看到,MM1是一个图文的多模态大模型,参数规模有30亿、70亿、300亿三种大小,有图像识别和自然语言推理能力。其中,参与该论文的作...……更多
2024-03-16 18:14:00模型,苹果,参数,焦点,分析,公司

...进行联合建模的大语言模型组成。输入将图像输入经过预训练的视觉编码器 CLIP-ViT-L/14 ,以提取图像嵌入 Z ∈ R H×W×C。对于文本输入,使用经过预训练的大模型标记器对文本序列进行标记,并将其投射至文本嵌入 T ∈ R L×D 当中...……更多
2023-12-26 14:06:00模型,生态,模态,零碎,苹果,模型

...rtexAI的开发人员和企业客户。Google通常不会透露太多用于训练人工智能模型的数据来源,这次也不例外。这是有原因的。大部分训练数据来自网络上的公共网站、资源库和数据集。而其中的一些训练数据,特别是未经内容创作者...……更多
2024-05-16 11:05:00生成,图像,技术,人工智能,数据,模型

...天拥挤的车道、马路上奔跑的狗等,生成写实的Corner Case训练数据,进而训练自动驾驶系统对Corner Case场景的感知能力上限。
“书生2.5”还可根据文本快速检索出视觉内容。例如,可在相册中返回文本所指定的相关图像,或是在...……更多
2023-03-15 13:30:00商汤,模态,书生,模型,任务,社区

...方式。而在时间差方面,「Tiamat」从2021年开始进行模型训练,以自研并自主训练底层模型的方式,始终与海外技术节点、开源社区等保持着同频。“我们拼命地想告诉大家,这件事情很快就会成为风口。”「Tiamat」创始人青柑...……更多
2023-02-28 09:33:00可控性,极致,融资,生成,图像,模型

...机系获得博士学位,在加速推理、可控生成、基础架构、训练策略等方面已发表十余篇顶会论文。首席科学家为清华大学计算机系人工智能实验室主任、智源研究院首席科学家朱军。可以说,2023年是国内大语言模型狂飙的元年...……更多
2024-03-14 15:12:00清华,班底,中国,架构,训练,公司

...更大像素、更高分辨率的图像以提供丰富细致的信息进行训练和推理,标注数据的规模和复杂性也随之增加。如何提高超大像素图像数据标注的效率和精度,成为当前亟待解决的问题。例如,一张超大像素的医学影像可以更好地...……更多
2023-10-25 19:02:00精度,像素,图像,效率,能力,科技

...正在教授人工智能理解和模拟运动中的物理世界,目标是训练出能够帮助人们解决需要与现实世界互动的问题的模型。在此,隆重推出文本到视频模型——Sora。Sora可以生成长达一分钟的视频,同时保证视觉质量和符合用户提示...……更多
2024-02-16 18:44:00文生,奥尔,奥尔特曼,特曼,模型,提示

...提供API接口的闭源经营理念不同,LLaVA1.6的代码、模型与训练数据全开源,且在标准评测数据集上跑出了较为亮眼的成绩。一、LLaVA1.6:卷上加卷LLaVA是一种端到端训练的大型多模态模型,又被称为“大型语言和视觉助手”。LLaVa-...……更多
2024-02-10 21:04:00性能,模型,模态,训练,数据,卷上

...能力的企业望持续成为产业受益者。以ChatGPT为代表的预训练大模型加速商业化落地,将带来大量算力需求,以政府为主导的城市智能计算中心AI算力卡国产化进度较快,建议关注华为昇腾生态圈核心厂商。ChatGPT等AI产业化的落地...……更多
2023-02-19 10:00:00模态,生成,图像,方向,领域,文字

...的不断完善。这其中,CLIP模型基于海量互联网图片进行训练,促进了AI绘画模型的组合创新。另外,Diffusion扩散化模型的引入也实现了算法创新,最终使用潜空间降维的方法解决了Diffusion模型在内存和时间消耗上的问题。从目前...……更多
2023-04-23 16:45:00加速度,赛道,生成,图像,生成,图像
本文转自:中国科学报南开大学等让人工智能模型训练提速10倍以上本报讯(通讯员高雨桐 记者陈彬)南开大学、南开国际先进研究院(深圳福田)教授程明明团队发布了一项国际联合研究成果MDT,与人工智能文字生成视频大...……更多
2024-04-03 07:20:00人工智能,提速,人工,模型,训练,智能

... BEV感知能力,需要积累海量的已标注数据以支持模型的训练。如何找到更多高质量的数据并高效利用,是支持技术不断迭代的重要基石。轻舟智航充分利用作为高级别自动驾驶解决方案提供商在AI领域的先发优势,通过突出的基...……更多
2023-11-01 20:27:00轻舟,关键,轻舟,模型,场景,数据

...学习方法。该方法在 233 名患者的 MRI 图像数据集上进行训练和测试,并取得了良好的分割和分类效果。与之前的方法相比,该方法具有更好的性能和准确度。研究方法卷积神经网络及其实现细节本文首先提出了一种用于肿瘤分...……更多
2024-05-24 10:58:00卷积,脑肿瘤,神经网络,学习方法,尺度,深度

...本报记者 张佳欣人工智能(AI)迅速发展离不开对模型的训练。然而,高质量数据短缺以及部分领域封闭式的数据生态似乎成为AI发展的掣肘。据多家外媒报道,OpenAI、谷歌和Meta等公司正寻求在线信息来训练最新的AI系统。但他...……更多
2024-04-17 03:27:00巨头,秘密,数据,数据,训练,公司

...之一,也是体现通用大模型能力的试金石,对模型算法、训练平台、算力设施都有较高的要求。在用户侧,这又是一个和广大用户联系紧密的应用入口。智能涌现尝试用简单的指令让混元画图,生成速度基本在10秒左右,效果可...……更多
2023-10-29 10:13:00腾讯,接入,生成,模型,图像,业务

...EEE Spectrum)大语言模型(LLM)在多大程度上“记住”了其训练输入内容是一直以来广受关注的问题。而最近的实证研究表明,大语言模型在某些情况下的确可以重现或者生成只包含细小差别的训练集内初始文本。例如,Milad Nasr...……更多
2024-01-11 06:45:00生成,输出,抄袭,问题,图片,输出

...大语言模型LLM之上生长出多模态的应用,而并非从头开始训练的多模态的大模型,这是多模态大模型目前“不能言说的秘密”。
图源:中信建投证券谷歌自己也提到,到目前为止,创建多模态模型的标准方法基本是针对不同模...……更多
2023-12-07 10:31:00强悍,模型,模态,模型,训练,能力
...上取得重要进展。该实验室刘东研究员等提出了一种无需训练的深度电阻抗图像重建方法,为电阻抗成像技术在病变组织特异性判断中的应用开辟了新道路。相关研究成果近日发表于国际权威学术期刊《IEEE模式分析与机器智能...……更多
2023-02-14 02:15:00范式,电阻,图像,突破,图像,电阻

...了一部分公司想要“走捷径”直接偷换概念外,大模型的训练,原本就是烧钱、砸人还不一定有成效的事情。以2022年先后推出 AI Art 赛道明星项目 DALLE2 和对话式 AI 爆款的 chatGPT 的母公司 openAI 来说,其大模型 GPT1 从 2017 年就开...……更多
2023-01-05 09:26:00模型,生成,用户,技术,应用,图像
更多关于科技的资讯:
本文转自:芜湖日报本报讯 (记者 田龙 程中玉)5月24日至26日,2024第八届世界无人机大会在广东省深圳市开幕,全球无人系统领军企业均携带自己的无人机产品或应用解决方案参加展会
2024-05-27 00:29:00
“欧莱雅们”也卷不动平价彩妆。5月26日,北京商报记者获悉,欧莱雅旗下平价彩妆品牌NYXPROMAKEUP(以下简称“NYX”)官方海外旗舰店将于6月底关闭
2024-05-27 00:29:00
在跨境出海的较量中,没有平台和商家能继续“佛系”。5月26日,北京商报记者从亚马逊以及部分跨境商家处了解到,亚马逊已在中国商家端设立了亚马逊入仓分销网络(AWD)的本地支持团队
2024-05-27 00:29:00

作为大模型独角兽企业之一,月之暗面的“炙手可热”还在持续,腾讯入局投资传言四起的同时,阿里也“自曝”已向月之暗面合计投资约8亿美元
2024-05-27 00:29:00
美东时间上周五,美国制药巨头礼来公司宣布,将追加53亿美元的投资,扩大其印第安纳州布恩县黎巴嫩地区制造基地的产能,以满足市场对减肥药Zepbound和糖尿病药物Mounjaro的需求
2024-05-27 00:30:00
本文转自:吉林日报冰雪引领 文旅先行——访“冰雪旅游场地装备与智能服务技术”文化和旅游部重点实验室主任辛本禄本报记者 李婷 姜岸松5月25日
2024-05-27 00:36:00

本文转自:合肥晚报跨星海 开天路 腾“空”而上合肥空天信息产业链整体水平正加速提升5月24日,天启卫星物联网科技有限公司的负责人赫义明带着团队一直在外忙碌
2024-05-27 00:42:00
本文转自:合肥晚报数字中国建设 合肥树“典型”全国首批数据标注基地建设任务城市名单发布本报讯 5月24日至25日,以“释放数据要素价值
2024-05-27 00:42:00

本文转自:合肥晚报合肥造第一台冰箱仍在用?市民“以旧换新”看过来合肥造第一台冰箱“现身”。本报讯 5月25日下午,长虹美菱第二届感恩回馈节在合肥美菱公寓举办
2024-05-27 00:42:00
本文转自:盐阜大众报□记者 张长虎 5月10日,记者走进中联即送网络科技有限公司,被眼前一幕深深震撼:从30平方米的LED大屏上
2024-05-27 00:49:00

本文转自:福州晚报□关注数字中国建设峰会鼓楼展示低空经济“新面孔”将加快发展“低空+”示范应用场景工作人员调试S3500大型无人机机场
2024-05-27 00:54:00
本文转自:南通日报海门医疗器械项目专业化孵化平台东布洲致远孵化器揭牌本报讯 (记者袁晓婕 黄天玲)25日,海门区举办东布洲·致远人才与产业研讨会
2024-05-27 01:09:00