- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

首个开源的ChatGPT低成本复现流程来了!预训练、奖励模型训练、强化学习训练,一次性打通。最小demo训练流程仅需1.62GB显存,随便一张消费级显卡都能满足了。单卡模型容量最多提升10.3倍。相比原生PyTorch,单机训练速度最高...……更多
2023-02-15 15:47:00流程,成本,模型,训练,内存,参数

首个开源的ChatGPT低成本复现流程来了!预训练、奖励模型训练、强化学习训练,一次性打通。最小demo训练流程仅需 1.62GB 显存,随便一张消费级显卡都能满足了。单卡模型容量最多提升 10.3倍。相比原生PyTorch,单机训练速度最...……更多
2023-02-17 14:37:00流程,成本,模型,训练,内存,参数

...质量合成数据混元团队开发了一套完整的高质量数据合成流程,主要包括四个步骤:指令生成、指令进化、回答生成和回答过滤。在指令生成阶段,混元团队使用高质量的数据源作为种子,覆盖多个领域和不同复杂度,确保指令...……更多
2024-11-07 09:54:00腾讯,商用,模型,参数,模型,数据

...模型能力、训练成本、推理成本、数据集类型等。下面的流程图总结了一些建议,可以帮助你选择合适的LLM适配方法。❌ 预训练预训练是LLM训练的重要组成部分,它使用token预测变量作为损失函数。自监督算法,使得大量数据训...……更多
2024-08-27 12:03:00小白,长文,千字,基础,指南,训练

...数量超过近三年总和。MoE大模型架构凭借平衡大模型训推成本和计算效率等优势,更适合处理大规模数据和复杂任务,已成谷歌、OpenAI、阿里、腾讯等企业控制成本、提升模型性能、应对大模型“价格战”的新方向。MoE的内涵、...……更多
2024-11-04 16:00:00研究方向,模型,现状,方向,趋势,研究

...研大模型LexinGPT目前已经在电销、客服、催收等主要业务流程中全面落地。以电销场景为例,应用AI大模型后,当日授信转化率相对外采技术提高70%、当日下单转化率提升10%;客服业务机器人场景下,机器人参与客服的比例和效...……更多
2024-01-29 21:36:00模型,之路,金融业,落地,观察,训练

...是其中的一家创业公司,致力于简化 AI 训练集群的搭建流程。Nikhil Sonti 和 Nikhin Sonti 创立了 Felafax,他们的口号是在构建开源 AI 平台,为下一代 AI 硬件服务,将机器学习的训练成本降低 30%。与英伟达相比,AMD 的 GPU,尤其是 MI3...……更多
2024-10-09 09:52:00模型,跟着,博客,模型,参数,训练
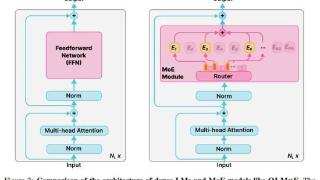
...种任务上取得了重大进展,但在训练和推理方面,性能和成本之间仍然需要权衡。对于许多学者和开发人员来说,高性能的 LM 是无法访问的,因为它们的构建和部署成本过高。改善成本 - 性能的一种方法是使用稀疏激活混合专...……更多
2024-09-06 10:01:00推理,模型,成本,参数,模型,训练

...层大模型的成熟,但训练大模型需要的算力、网络、数据成本非寻常公司能承受。而本文主角潞晨科技,希望为这一难题提供解法。潞晨科技成立于2021年,主要业务是通过打造分布式AI开发和部署平台,帮助企业降低大模型的落...……更多
2023-05-22 09:14:00数亿,分布式,融资,开发,平台,科技

...提高缓存命中率并提升整体性能。通过仔细分析LLM的工作流程并减少不必要的计算开销,该引擎进一步提高了数据重用度和计算效率,特别是在处理Attention机制时,针对不同长度的序列采取了不同的优化算法来确保最高的访存效...……更多
2024-07-11 16:45:00正在,时代,模型,推理,英特,英特尔

...优越的并行处理能力,一举成为了AI训练和推理的首选。成本然而,高端GPU服务器在市场中经常出现供不应求,极难获取的现象。
仅有资金雄厚的科技巨头们,诸如微软、谷歌,才能够承担起这笔费用。另一方面,不仅买不起...……更多
2024-08-02 09:47:00大厂,模型,参数,疯狂,服务器,服务
...在训练大型模型时,我们需要依靠分布式优化技术。这个流程包括四个层次:高质量的数据集、计算网络存储的分布式系统,以及在更高层次上,我们需要选择一个合适的基座模型。在选择模型时,如果我们只是想在自己的业务...……更多
2023-05-28 18:37:00峰会,产业发展,创始人,颠覆,模型,训练

...价是准确性有所损失。不过,仅比较性能,而忽略整体的成本是不公平的对比。毕竟单个晶圆级的WSE-3芯片的成本也远远高于Groq LPU的成本。 ……更多
2024-09-02 13:36:00晶圆,芯片,生成,模型,性能,参数

...的答案,他表示,“vivo大模型现在每年20亿~30亿元的投入成本,总投入成本已经超过200亿元,人才和数据算力各占一半,人才成本平均每人税后100万元。”过去一年,AI大模型席卷整个互联网科技行业,当大模型完成从0到1的基...……更多
2023-12-06 11:40:00年薪,模型,厂商,手机,模型,手机

...了Phi-3系列模型,其能力水平大致与GPT-3.5相当,但运行的成本却远远低于GPT-3.5。仅仅4个月后,微软又将其轻量级模型的表现提升了一个档次。开发算力要求较低的端侧模型,或许能让微软的AI PC和其它使用Windows系统的设备拥有...……更多
2024-08-22 09:49:00上下文,微软,架构,模型,上下,性能

...生适合巨头的生意——这从其成本投入上可见一斑。
从流程上拆解,构建一个大模型至少需要足够的数据处理、计算和网络能力。拿流程上游的数据处理来说,无监督学习能解决一部分数据标注的成本,但此前的数据收集、数...……更多
2023-02-08 19:19:00迭代,路线,背后,观察,行业,模型

...性能而获得了前所未有的关注。然而, LLM 的训练和推理成本高昂,人们一直在尝试通过各种优化方法来降低成本。本文来自上海算法创新研究院、北京大学等机构的研究者受人类大脑记忆层次结构的启发,他们通过为 LLM 配备...……更多
2024-07-11 09:33:00维南,领衔,院士,新作,模型,存储

...入序列长度的增加而增加参数量,能减少内存占用和计算成本。线性注意力机制不同于传统Transformer中的二次方复杂度注意力机制,它能通过更小的计算开销来检索和更新长期记忆。在Infini-attention中,旧的KV状态({KV}s-1)被存储...……更多
2024-04-14 02:57:00大内,机制,上下文,模型,处理,上下

...除了频繁的同步开销,也增加了通信与其他 Checkpoint 存储流程的执行重叠度。系统架构下图展示了 ByteCheckpoint 的系统架构:API 层为不同训练框架提供了简单,易用且统一的读取和写入 ( Save )和读取( Load )接口。Planner 层会根...……更多
2024-08-09 09:37:00万卡,训练,豆包,脆皮,大为,模型

...与静态数据,如今面临着巨大的挑战。将大数据分析的全流程拆解来看,预处理阶段即需要面对多个技术难题。以加密和压缩环节为例,作为批量数据预处理的必然流程,只有优先完成数据处理之后才能进行分析。而这个过程需...……更多
2023-02-22 17:40:00困局,英特,英特尔,数据,四代,处理

...AI软件只需要在里面从设计、优化、部署到分析“走一趟流程”,就能快速转换成在其他操作系统和平台上也可以运行的软件产品。只需要一次开发,甚至是大模型软件的开发,就能让它在多个平台运行,不需要担心适配的问题...……更多
2023-11-16 20:30:00安卓,三个字,模型,三个,手机,模型

...不得不扩展更多计算节点。这就导致构建 AI 基础设施的成本不断激增。降低这些成本具有很大的好处,构建成本和能耗高效型计算机集群也就自然成了一个热门的研究方向。近日,DeepSeek(深度求索)发布了一份基于硬件发展的...……更多
2024-09-07 09:44:00高性能,架构,深度,多年,成本,学习

...、ChatGLM2、Llama2、文心一言ERNIE-Bot-Turbo
2、模型开发全流程一站式能力:场景分析、数据增强、模型训练、模型评估、模型测试、模型发布、模型部署 3、低代码方式降低模型开发门槛:通过拖拽的方式,完成训练流程的搭建...……更多
2024-08-07 09:45:00模型,服务,平台,科技,模型,数据

...Seek R1模型的测试结果,其速度甚至超过了8张A100显卡,而成本却低得多。运行6710亿参数的DeepSeek R1模型通常需要一台搭载6-8张A100的专业级服务器,总价轻松超过百万元这对于普通用户来说几乎是不可能负担的。然而满血版M3 Ultra...……更多
2025-03-12 17:20:00实测,速度,苹果,运行,模型,速度

...包括RWKV 5和6、RetNet、GLA等。尽管会使生成的计算和内存成本翻倍,但仍然是一个可以接受的权衡,因为RNN的生成成本比Transformer低很多。以上3个是不需要训练的方案,而基于SC是由状态参数过拟合引起的假设,我们也可以尝试使...……更多
2024-11-28 12:03:00长上,清华,下文,团队,状态,作者

...利用延迟掩蔽、MoE、分层扩展等策略,将扩散模型的训练成本降到了1890美元。训练一个扩散模型要多少钱?之前最便宜的方法(Wuerstchen)用了28400美元,而像Stable Diffusion这样的模型还要再贵一个数量级。大模型时代,一般人根...……更多
2024-08-13 09:42:00文生,高质量,模型,参数,模型,训练

...拷贝和格式免转换,加速数据价值释放,并实现整体拥有成本(TCO)最优。在推理方面使大模型实现从“快思考”到“慢思考”的转化大模型产品具有即时问答的“快思考”能力,让AI变得更“聪明”,就要使其具备逻辑梳理、...……更多
2024-12-19 18:16:00华为,集群,中国,中国移动,存储,规模

...们2000亿的模型大概花了5亿人民币,也就是几千万美元的成本,要是万亿模型,那肯定接近10亿人民币或者更多,才能训练好。”高文表示,任何说花很少一点钱就能训练出来,那肯定是做了很多简化,简化以后才能训练出来,...……更多
2024-06-05 13:00:00高文,院士,实验室,模型,训练,实验

...球科技公司Yandex推出了YaFSDP,这是一种用于训练大型语言模型(LLM)的开源方法。据介绍,YaFSDP是目前在大型语言模型训练中增强图形处理器(GPU)通信并减少内存使用量的公开可用的最有效工具,与FSDP相比,根据架构和参数数量...……更多
2024-06-18 16:13:00处理器,图形,模型,高达,训练,语言

...化商业部署的关键是对数据安全,算力自主可控以及部署成本的苛刻要求,RISC-V架构本身的开源、灵活等特性,以及希姆计算联合生态伙伴共同打造的软硬一体国产化方案,成为企业规模化部署大模型的坚实基础。一、大模型焦...……更多
2023-11-15 15:41:00模型,一体机,推理,快车,芯片,一体
更多关于科技的资讯:
省数据和政务服务局发布公告公开征集一批河北省高质量数据集河北日报讯(记者解楚楚)9月26日,河北省数据和政务服务局发布公告
2025-10-04 08:03:00
央媒看太原9月30日,央视财经频道《经济信息联播》栏目以《双节市场备货足美食特产受青睐》为题,报道了假期到来,太原市各大综合市场提前备货
2025-10-04 07:17:00
厦门网讯(厦门日报记者 楚燕 通讯员 石青青)长假期间,许多人从忙碌的工作中解脱出来,趁机好好休息。可是,如果休息方式不得当
2025-10-03 08:37:00
渤海之潮涌动着澎湃的脉搏,海河之畔镌刻着科技的印记。10年前,一颗带有“清华”基因的种子在天津这片沃土扎根;10年后,它长成一棵枝繁叶茂的参天大树
2025-10-03 09:25:00

9月29日,抖音生活服务联合北京卫视发起“老板驾到”直播活动,助力北京国庆中秋消费。抖音用户在@北京卫视 直播间下单超1万次
2025-10-03 18:36:00

国庆首日,“FutureBOT未来引力”2025北京机器人文化节在北京昌平超极合生汇正式拉开帷幕,成为国庆假期极具科技温度的打卡地
2025-10-03 19:06:00
泰康人寿发布新品“泰康百万药无忧(庆典版)医疗保险”(以下简称“百万药无忧”),以广覆盖、易投保、强保障、低费率为优势
2025-10-03 09:17:00
厦门网讯(厦门日报记者 翁华鸿 通讯员 林雨新)在近日举行的2025全球数据管理峰会“数据要素分论坛暨大数据统计与人工智能技术创新管理研讨会”上
2025-10-03 08:38:00

摘要:2025“你是达芬奇”全球青少年科学与艺术创新赛圆满落幕,其中金奖获奖少年的亲身实践告诉我们,在AI赋能的新时代
2025-10-02 16:22:00

2025年10月1日,随着国庆长假首日出行高峰的到来,高德基于北斗卫星导航系统的定位数量接近1万亿次,支撑导航总里程数超90亿公里
2025-10-02 22:31:00
10月1日,从太钢获悉,今年以来,太钢不锈进料加工团队以“精准备案、高效协同”为核心,在进料铬铁镍铁资源利用方面取得突破性进展
2025-10-02 17:39:00
厦门网讯(厦门日报记者 林露虹)记者昨日从中国移动咪咕公司获悉,该公司打造的“鼓浪屿AI伴游”服务已正式上线。市民和游客只需打开“鼓浪屿元宇宙”微信小程序
2025-10-02 08:57:00