- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...域。我们认为ChatGPT中短期内产业化的方向主要分为文字模态的AIGC应用、代码开发相关、图像生成领域、智能客服四大板块。ChatGPT的成功,预示着人工智能(AI)无论在经济性与可获得性上都达到了支持普及的水平。同时,ChatGPT...……更多
2023-02-19 10:00:00模态,生成,图像,方向,领域,文字

...果几乎一致。话归正题,OpenAI的这次开源,提供了一条多模态通道,让“以文生图”的效果得到进一步提升(以前不是没有类似的模型,但没有这个效果好)。现在,当我们说“画一个牛油果椅子”,计算机就会将这句话通过CLI...……更多
2023-02-17 06:00:00长文,视角,绘画,经理,产品,模型

...实现AGI(通用人工智能)的重要里程碑。券商建议关注多模态技术Sora视频一出,立刻震惊业界。360集团创始人、董事长周鸿祎2月16日在微博发文表示,这意味着AGI实现将从10年缩短到1年。其实,Sora出现之前,也有其他类似的AI...……更多
2024-02-19 08:10:00颠覆,布局,行业,视频,公司,模型
...业内分析认为,该项新产品或将促使大模型厂商加大对多模态大模型的研发投入,并进一步推动AGI(通用人工智能)进程。一直以来,视频领域便是被普遍看好的AI应用落脚点之一。继可生成图文的ChatGPT之后,Sora的发布迎合了...……更多
2024-02-26 08:58:00模态,行业应用,模型,进程,场景,应用

...研究员成立。与Stability AI类似,黑森林致力于研发优质多模态模型并开源,目前已完成3100万美元(约合人民币2.25亿元)的种子轮融资。黑森林还预告不久之后将发布SOTA(当前技术指标第一)视频模型。从其放出的Demo来看,无...……更多
2024-08-05 09:39:00文生,人马,模型,生成,视频,模型

【新智元导读】Mini-Monkey 是一个轻量级的多模态大型语言模型,通过采用多尺度自适应切分策略(MSAC)和尺度压缩机制(SCM),有效缓解了传统图像切分策略带来的锯齿效应,提升了模型在高分辨率图像处理和文档理解任务的...……更多
2024-08-13 09:42:00模态,华南,专治,后遗症,理工,分辨率

...随着大模型技术日益成熟,vivo在语言、图像、语音、多模态等全模态的AI技术上逐步升级为大模型能力,正从传统的AI技术时代迈向大模型AI技术时代。vivoAI算法技术总监李方圆全新蓝心大模型带来4项核心升级:1、语言大模型升...……更多
2024-10-14 01:53:00开发者,模型,惊喜,用户,开发,模型

...MorpherVLM是国内首个基于概念融合范式提出的近百亿级跨模态生成模型,通过异构的视觉编码-解码网络结构,并引入基于用户反馈的强化学习(RLHF)和细粒度的提示-隐变量对齐技术,提高了模型对图像多尺度信息的建模能力,...……更多
2023-02-28 09:33:00可控性,极致,融资,生成,图像,模型

...手写英文准确翻译成中文、还能精准分析财报数据……多模态能力再次升级!今天,阿里国际AI团队发布了一款多模态大模型Ovis,在图像理解任务上不断突破极限,多种具体的子类任务中均达到了SOTA(最新技术)水平。多模态...……更多
2024-09-20 13:35:00模态,阿里,模型,能力,升级,国际

...为了AI发展的最大障碍。当前的数字化世界,信息以多种模态存在——自然语言、程序代码、图像、视频、音频、3D模型、数学符号……这些信息形式各自独立,彼此之间的“对话”几乎不存在。AI虽然能够在单一模态下表现出色...……更多
2024-09-20 09:51:00阿里,生成,统一,语言,世界,模态

...音乐理解和生成结合在一起的想法比较新颖,论文也是多模态大模型领域的先期工作之一。并且,除了大模型本身,我们提出的针对模型训练的数据集制作流程和整理的数据集,对学术界也具有较大价值。”腾讯 ARC Lab 刘山松研...……更多
2024-04-09 10:25:00模态,音乐,科学家,生成,模型,创作

...品 | 搜狐科技作者 | 潘琭玙OpenAI在3月15日凌晨正式发布多模态大模型GPT-4,作为深度学习的新里程碑,据OpenAI介绍,GPT-4在专业和学术方面表现出近似于人类的水平。例如,它在模拟律师考试中的得分能够排进前10%左右,相比之...……更多
2023-03-15 21:00:00草图,从业者,生成,工程师,代码,工程

12月11日,多模态AI概念股继续活跃,苏州科达(603660.SH)三连板。截至当日中午收盘,因赛集团(300781.SZ)涨13.32%,苏州科达涨9.96%,宣亚国际(300612.SZ)涨9.7%。消息面上,GoogleAI大模型Gemini近日发布,Gemini是Google到目前为止规……更多
2023-12-11 15:01:00模态,热潮,产业发展,产业,发展,模态

IT之家 8 月 26 日消息,云知声于 23 日宣布推出山海多模态大模型。通过整合跨模态信息,山海多模态大模型能够接收文本、音频、图像等多种形式作为输入,并实时生成文本、音频和图像的任意组合输出。▲云知声山海助手微...……更多
2024-08-27 09:38:00模态,山海,实时,生成,模型,图像
...。AIGC不仅提升了新闻采编工作的效率与质量,还通过多模态、多渠道的新闻生产、整合、分发重塑新闻传播业态。AIGC助推报道效率与质量“双提升”AIGC在新闻报道中的应用体现在自动化内容生成和数据驱动的深度分析两个方面...……更多
2024-06-14 04:16:00能力,业务,新闻,新闻,内容,信息

...频,表情、五官、姿势都会产生非常自然的变化。在AI多模态领域,科技巨头、明星初创企业似乎把火力集中到了同一个方向——AI视频生成,Sora的火热更是一石激起千层浪,同类产品发布你追我赶,战况之焦灼可见一斑。在该...……更多
2024-03-01 09:26:00阿里,奋起,模型,国产,视频,视频

Meta最新 6模态大模型,让AI以更接近人类的方式理解这个世界。比如当你听见倒水声的时候就会想到杯子,听到闹铃声会想到闹钟,现在AI也可以。尽管画面中没有出现人类,AI听到掌声也能指出最有可能来自电脑。这个大模型 I...……更多
2023-05-11 19:53:00模态,感官,模型,体验,世界,模态
...大量通用数据、行业数据,支持文本、图像、视频等多种模态,并打造了全流程的数据处理工具。超过700万亿字节的通用数据集可以开展通用模型训练,同时,4.33万亿字节的行业垂类数据对模型训练也极为重要。当前已知的全...……更多
2024-06-16 04:14:00人工智能,北京,人工,运营,智能,数据

...文、文生图、3D生成之后的最新技术进展。据腾讯混元多模态生成技术负责人凯撒现场介绍,此次更新中,HunYuan-Video模型经历了四项核心改进:1、引入超大规模数据处理系统,提升视频画质;2、采用多模态大语言模型(MLLM),...……更多
2024-12-04 09:49:00文生,腾讯,提示,建议,视频,生成

...进模型在视觉推理方面同样不足。为此他们提出了一种多模态的视觉推理基准,并设计了一种新颖的数据合成方法。无论是语言模型还是视觉模型,似乎都很难完成更抽象层次上的理解和推理任务。语言模型已经可以写诗写小说...……更多
2024-08-08 16:23:00模态,领衔,基准,推理,视觉,能力

...7.21705项目地址:https://ali-videoai.github.io/tora_video/一、三种模态组合输入,精准控制运动轨迹Tora支持轨迹、文本、图像三种模态,或它们的组合输入,可对不同时长、宽高比和分辨率的视频内容进行动态精确控制。轨迹输入可以...……更多
2024-08-05 09:34:00马良,神笔,阿里,猫咪,演示,报告
...晨,美国科技公司OpenAI在春季发布会上发布了最新GPT-4o多模态大模型。据OpenAI公司首席技术官米拉·穆拉蒂(Mira Murati)介绍,GPT-4o可以接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合进行...……更多
2024-05-14 13:59:00进一,模态,易用,易用性,人机,模型

...的。现在试想,如果上传的商品信息既能在文字、图像等模态上保持不变,又能够与文字、图片、视频等模态模型实现很好的融合,从而为商家产出AI商品图、海报、短视频,甚至是3D交互内容,这个市场需求是很大的。今年,...……更多
2023-12-26 17:49:00网易,生成,大会,视频,文生,生成

...也出现了大模型独角兽智谱AI的身影。36氪获悉,近日多模态AI模型公司生数科技完成新一轮数亿元融资。该轮融资由启明创投领投,达泰资本、鸿福厚德、智谱AI、老股东BV百度风投和卓源亚洲跟投。据介绍,融资主要用于多模...……更多
2024-03-14 15:12:00清华,班底,中国,架构,训练,公司

... OpenAI o1 技术的深入分析累计点击量已超过 15 万。如何全模态大模型与人类的意图相对齐,已成为一个极具前瞻性且至关重要的挑战。在当前 AI 领域的快速发展中,「有效加速」和「超级对齐」已经成为两个主要的发展动向,...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据
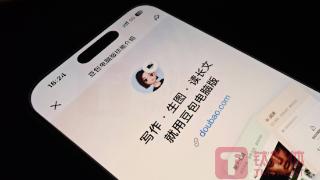
(图片来源:林志佳拍摄)国内活跃度最高的AI大模型应用正走向“多元化”。12月3日消息,钛媒体AGI获悉,字节跳动豆包日前上线了一项实用功能——图片理解。目前,豆包APP及豆包PC新增照片及相机按钮,上传图片后可识别...……更多
2024-12-04 09:51:00模态,豆包,字节,模型,媒体,图片
●多模态使人形机器人能融合图像、语义、力感知、环境感知等多种因素,综合判断、生成任务并执行任务,是让人形机器人具有自主思考能力的关键核心技术●标志着成都在我国多模态模型应用于人形机器人领域率先取得突...……更多
2024-08-13 06:37:00模态,人多,双臂,协作,模型,机器
...刚刚显现,未来还存在巨大的探索空间。第二个是关于多模态理解和生成的统一。在当前「scaling law 撞墙」的相关讨论中,多模态其实是一个被寄予厚望的方向。但是,这个领域目前面临一个严峻的挑战,即多模态的理解和生成...……更多
2024-11-27 13:32:00潜力,模型,图像,起点,领域,还是

...同完成,是全球首个同时支持文本描述、图像、点云等多模态输入的计算机辅助设计(CAD)生成大模型。计算机辅助设计(Computer-Aided Design,简称 CAD)软件是工业软件的重要分支,也是工业设计流程中的核心工具。然而,目前...……更多
2024-11-26 09:46:00一键,模态,高质量,生成,模型,图像

...灵奖得主Yoshua Bengio教授。博士期间的主要工作聚焦于多模态、GFlowNet、多智能体强化学习、AI于气候变化的应用。目前已在ICML、ICLR、ICASSP等机器学习顶会发表论文。代表作为Large-scale Contrastive Language-Audio Pretrai……更多
2024-06-29 09:37:00模态,基准,弱点,团队,模型,任务
更多关于科技的资讯:

月之暗面大语言推理系统专利获授权天眼查财产线索信息显示,近日,Kimi关联公司北京月之暗面科技有限公司申请的“一种大语言推理系统及方法”专利获授权
2025-03-04 10:42:00

近日,奥哲宣布将于3月13日至21日在上海、北京、广州举办数智新程·2025奥哲低代码数智化峰会暨云枢新品发布会。奥哲创始人兼CEO徐平俊
2025-03-04 10:45:00

在苏州工业园区企业苏大维格的无尘实验室里,一台名为"iGrapher3000"的巨型设备正挥动着无形画笔——它以0.1微米的超精度(相当于头发丝的千分之一)
2025-03-04 10:52:00

图一:搜狗录音笔电商页面宣称“终身免费录音转写文字的会员功能”。 图二:“搜狗AI黑科技”的客服给邵女士提出了补偿方案
2025-03-04 11:08:00
2025全国两会天津北方网讯:2025年全国两会期间,津云记者探访脑机交互与人机共融海河实验室,天津大学神经工程团队为记者介绍了最新科研成果——全球首个片上脑机接口智能交互系统
2025-03-04 11:11:00
3月3日,雀巢集团(以下简称“雀巢”)公告称,已与徐氏家族达成协议,收购徐福记国际集团(以下简称“徐福记”)剩余40%的股份
2025-03-04 11:14:00

近日,字节跳动的豆包语音大模型在小说演播场景取得突破,无需对话旁白、情感、角色等额外标签,也能实现高表现力、高自然度、高语义理解的小说演播效果
2025-03-04 11:14:00

3月3日晚,据大量玩家反馈和对应官微公告,网易旗下的《逆水寒手游》《燕云十六声》《蛋仔派对》《光遇》《第五人格》《阴阳师》等多款游戏同时出现服务器异常
2025-03-04 11:14:00
鲁网3月4日讯近日,山东省地质测绘院完成国产人工智能大模型DeepSeek的本地化部署,并启动内部测试,将其应用于院内办公场景
2025-03-04 11:37:00


近日,“莲花LIANHUA官方旗舰店”抖音账号发布了一则澄清视频:清汤大老爷们,莲花控股是卖调料的,是莲花味精啊,俺不卖跑车
2025-03-04 11:46:00
本文转自:人民网人民网北京3月4日电 (高清扬)3月4日,十四届全国人大三次会议在人民大会堂举行新闻发布会。大会发言人娄勤俭在回答记者提问时表示
2025-03-04 13:17:00
随着元宇宙技术的快速迭代与教育数字化转型的深入推进,虚拟现实(VR)、区块链、人工智能(AI)等技术正重构教育生态。作为数字原住民的大学生群体
2025-03-04 11:47:00
海外网3月4日电 新加坡《联合早报》3月3日刊发两会特稿表示,中国科技发展等经济议题预计将贯穿今年两会。报道说,宇树科技人形机器人等中国人工智能项目崭露头角
2025-03-04 11:48:00

2024年深圳新能源汽车产量超293万辆,卫冕中国新能源汽车第一城。智能网联汽车产业亦是深圳20个战略性新兴产业重点发展领域和8个未来产业重点发展方向之一
2025-03-04 11:51:00