- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...优秀开源开发者提供1000亿免费API tokens。GLM-4文生图和多模态理解得到增强。1月16日,在智谱AI(即北京智谱华章科技有限公司)首届技术开放日上,智谱AI发布新一代基座大模型GLM-4,支持128K的上下文窗口长度,单次提示词能处...……更多
2024-01-17 16:47:00模型,基座,基金,模型,文生,模态

...混元API服务调用,可满足文生文、图生文、文生图等不同模态以及角色扮演、FunctionCall、代码等不同专项的模型需求。2024年年初,腾讯混元就宣布在国内率先采用MoE架构模型,总体性能比上一代密集模型提升50%。此后,腾讯混...……更多
2024-11-06 09:41:00模型,腾讯,全家,生成,同时,语言
多模态大模型是当下很火的一种创新技术,加快对多模态大模型技术的布局,可进一步提高金融服务效率,缓解行业发展困境。为了攻克创新技术领域的难题,度小满联合哈尔滨工业大学共同研发出一种创新的自适应剪枝算法...……更多
2024-05-17 13:00:00模态,算法,模型,联合,模态,模型

...候选选项、引入纯视觉输入设置)更严格地评估模型的多模态理解能力;模型在新基准上的性能下降明显,表明MMMU-Pro能有效避免模型依赖捷径和猜测策略的情况。多模态大型语言模型(MLLMs)在各个排行榜上展现的性能不断提...……更多
2024-09-18 13:31:00模态,史诗,基准,难度,问答,文本

...内部特征同等的高度,进行显式的逻辑映射,通过整合多模态数据,如点云、图像、声音和文字,构建出对环境的全面细致的表示。这些不同形式的数据提供了丰富的环境信息,从三维形状和空间位置、到视觉特征、再到上下文...……更多
2024-03-22 10:31:00模态,语法,校友,模型,智能,智能
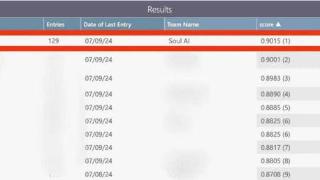
... AI 发起挑战的高规格赛事落下了帷幕!这就是第二届多模态情感识别挑战赛(MER24),它由清华大学陶建华教授、中国科学院自动化研究所连政、帝国理工学院 Björn W.Schuller、奥卢大学赵国英以及南洋理工大学 Erik Cambra 联合在 A...……更多
2024-08-01 09:34:00模态,拟人,玩家,模态,情感,模型

...多样性和系统性——涵盖文字、音频、图片、视频等多种模态,以及TTS(文本转语音)、OCR(光学字符识别)等跨模态数据,使模型能够学习更复杂的语义关联,显著提升多轮对话、图像生成等任务的准确性,构建的“预训练集...……更多
2025-06-23 23:26:00数据,建好,贵阳,粮仓,交易所,高质量

...能够受邀参加36氪AI Partner大会。今天我的演讲主题是《多模态智能激发应用新场景》,借这个场合与各位新老朋友分享趣丸科技在人工智能方面的最新探索成果,以及赋能智能音频和数字安全方面的一些思考。首先,请允许我简...……更多
2024-05-24 22:22:00模态,生产力,副总,场景,大会,智能
...源研究院创始人、创始理事长张宏江表示,今天大热的多模态大模型未来发展方向一定不光是做视频生成、视频剪辑、拍电影或是生成电视剧。从技术角度观察,可以用它来做机器的大脑、识别外围的世界、武装未来的自动驾驶...……更多
2024-03-25 20:31:00张宏,北京,创始人,研究院,模型,背后

...箱底的技术实力?按百度说法,文心4.5定位新一代原生多模态基础大模型,在多个基准测试中超过GPT-4o,得分最高的则是DocVQA,该基准主要测试文档图像的问答能力。在文本能力方面,文心4.5则在多个主流基准测试中超过DeepSeek-...……更多
2025-03-20 11:38:00成色,补课,模型,文心,模型,模态

...的扩散模型架构 OmniGen,一种新的用于统一图像生成的多模态模型。OmniGen 具有以下特点:统一性:OmniGen 天然地支持各种图像生成任务,例如文生图、图像编辑、主题驱动生成和视觉条件生成等。此外,OmniGen 可以处理经典的计...……更多
2024-10-30 09:53:00易用,架构,生成,模型,图像,高度

文|武静静编辑|邓咏仪36氪获悉,多模态大模型公司「若愚科技」完成超5000万天使轮融资,本轮融资由东方精工领投,昆仲跟投,源合资本担任独家融资顾问。公司称,资金将主要用于产品研发,业务拓展以及团队搭建等方...……更多
2024-03-21 05:19:00机器人,融资,大脑,模型,机器,天使

...与微软争相拼臂力秀肌肉。Gemini 1.5 Pro的横空出世,将多模态大模型的标准提到了一个新高度。一、极致性能背后的模型架构当地时间2月15日,Alphabet与Google公司首席执行官Sundar Pichai携首席科学家Jeff Dean等众高管在X平台发布了多...……更多
2024-02-21 14:05:00劲敌,高产,模式,模型,上下文,处理
...刚刚显现,未来还存在巨大的探索空间。第二个是关于多模态理解和生成的统一。在当前「scaling law 撞墙」的相关讨论中,多模态其实是一个被寄予厚望的方向。但是,这个领域目前面临一个严峻的挑战,即多模态的理解和生成...……更多
2024-11-27 13:32:00潜力,模型,图像,起点,领域,还是

IT之家 8 月 26 日消息,云知声于 23 日宣布推出山海多模态大模型。通过整合跨模态信息,山海多模态大模型能够接收文本、音频、图像等多种形式作为输入,并实时生成文本、音频和图像的任意组合输出。▲云知声山海助手微...……更多
2024-08-27 09:38:00模态,山海,实时,生成,模型,图像

...zhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com本文出自启元世界多模态算法组,共同一作是来自清华大学的一年级硕士生谢之非与启元世界多模态负责人吴昌桥,研究兴趣为多模态大模型、LLM Agents 等。本论文上线几天内在 github 上斩获 1...……更多
2024-09-07 09:44:00模型,语音,对话,机构,语音,文本

...山大学、联想的研究团队推出了ConsistentID,可在细粒度多模态面部提示下,仅利用单张参考图像生成多样的肖像,且保持五官的一致性。
最终在人脸个性化任务处理上,相比腾讯的photomaker和小红书的instantID,在五官一致性保持...……更多
2024-05-22 15:47:00小兰,中山大学,人脸,中山,成果,个性

...的主要方向,表示 OPPO 会在 AI 方面带来更多的惊喜。多模态和个性化是将要深耕的方向,同时端云协同将是重点架构。“我们相信,在这些领域持续投入后,一定能为用户带来更加与众不同的体验。”张峻进一步说明,未来会...……更多
2024-10-22 09:48:00模态,总监,方向,个性,产品,模态
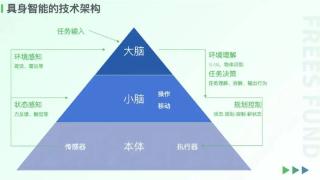
...策,并向控制模块发出指令。该环节以中央计算单元与多模态决策算法为核心。【小脑】负责运动控制、感知外界状态,在大脑的策略下实现机器人动作的执行和反馈。控制:将决策指令转化为实际操作,实现与物理世界的互动...……更多
2024-12-03 09:50:00小脑,瓶颈,机器人,新一代,机器,突破

...为了AI发展的最大障碍。当前的数字化世界,信息以多种模态存在——自然语言、程序代码、图像、视频、音频、3D模型、数学符号……这些信息形式各自独立,彼此之间的“对话”几乎不存在。AI虽然能够在单一模态下表现出色...……更多
2024-09-20 09:51:00阿里,生成,统一,语言,世界,模态

...导读】面壁小钢炮MiniCPM-V 2.6重磅出击,再次刷新端侧多模态天花板!凭借8B参数,已经取得单图、多图、视频理解三项SOTA ,性能全面对标GPT-4V。再次刷新端侧多模态天花板,面壁「小钢炮」 MiniCPM-V 2.6 模型重磅上新!仅8B参数...……更多
2024-08-07 09:42:00多图,小钢炮,模态,上端,手机,视频

...技术普惠的理念,在今天上线备受期待的第一款免费的多模态模型——GLM-4V-Flash。GLM-4V-Flash 不仅基于 4V 系列模型的各项优秀能力,更在图像处理上实现了精确度的提升。这一多模态免费模型将进一步降低开发者在各个领域深入...……更多
2024-12-12 09:49:00费多,模态,模型,开放,平台,模型
...原生HTAP数据库,支持包括向量数据、时序数据在内的多模态数据管理和检索能。MatrixOne不仅实现了向量类型、向量搜索和向量索引功能,还通过其MatrixGenesis产品提供大模型托管和多模态检索服务,为企业搭建一站式生成式AI应...……更多
2024-11-29 19:41:00向量,矩阵,起源,前景,数据库,报告

...主组装IKEA家具,或者通过AI驱动的AR眼镜。」突破性的多模态对齐组装一件IKEA家具需要理解多种形式的指令:说明书提供了任务的整体分解和关键步骤;视频展示了详细的组装过程;而3D模型则定义了部件之间的精确空间关系。I...……更多
2024-12-04 09:53:00斯坦,斯坦福,指令,全自动,场景,家具

...大招了!一连发布两大更新——Pixtral Large:前沿级124B多模态模型,用于驱动新Le Chat。全新Le Chat:具备网页搜索、Canvas、图像生成、图像理解等功能——而且所有功能免费提供!Mistral的CEO兼联创Arthur Mensch宣布道:「此次发布是...……更多
2024-11-20 09:43:00巨无霸,免费版,模态,突袭,模型,生成

...进行统一的处理。在本文中,研究者通过提出创新型的多模态模型架构,以及统一的物理可解释动作空间,来解决这些挑战。设计 RDT:双臂机器人操作的新架构「模仿学习」是当前开发通用机器人模型的主流方法。即机器人通...……更多
2024-10-21 09:55:00清华,双臂,机器人,模型,机器,全球

近日,世优科技“波塔发布会”在京举行,AI数字人多模态交互系统——波塔重磅发布。世优波塔是以世优科技多年积累的全栈数字人技术为基础,致力于打造人工智能时代有温度的多模态人机交互界面。 医疗水平提升、市场...……更多
2024-06-13 10:45:00优波,模态,人多,医疗服务,智慧,升级

...像与语音识别能力。本月初,微软更是公布了 166 页的多模态版 GPT-4V 的相关文档,详细探讨了 GPT-4V 的功能和使用情况,这一举动引起了业界的广泛关注。然而,在视觉语言模型的角逐中,谷歌也不甘示弱。
近日,Google Research...……更多
2023-10-17 16:31:00更快,模型,视觉,语言,训练,模型

...2年世界上最早的灵巧手Belgrade诞生,到如今高自由度、多模态感知的灵巧手在多个领域的广泛应用。六十多年的发展过程中,灵巧手的进化始终以复刻人手的灵活为终极目标,自由度的堆叠成为首选,例如英国老牌灵巧手企业Sha...……更多
2025-05-30 14:01:00灵巧,困局,中国,团队,指数,体系

...一年,人工智能领域风起云涌,模型架构、训练数据、多模态、超长上下文、智能体发展突飞猛进。大模型的技术演进路在何方?3月24日,在2024全球开发者先锋大会的大模型前沿论坛上,上海人工智能实验室领军科学家林达华...……更多
2024-03-25 10:53:00林达,模型,之路,结构,发展,模型
更多关于国际的资讯:
新华社加拉加斯12月20日电 委内瑞拉副总统兼石油部长罗德里格斯20日谴责美国在国际水域针对运载委内瑞拉石油的私人船只实施“盗窃和劫持”
2025-12-21 15:29:00
新华社纽约12月20日电 美国蓝色起源公司的“新谢泼德”飞行器20日在一次载人太空飞行中,把6名乘员送入太空,其中包括一名截瘫女性
2025-12-21 15:29:00
央视新闻客户端讯 当地时间20日,土耳其外交部长费丹就其在美国迈阿密参加有关加沙问题会议的相关情况向媒体作出介绍。费丹表示
2025-12-21 15:29:00
央视新闻客户端讯 当地时间20日,俄罗斯副外长鲁登科表示,俄罗斯对日本围绕“拥核”可能性展开的讨论持反对态度。鲁登科说
2025-12-21 15:29:00
一列客运列车20日在印度东北部阿萨姆邦行驶时与野象群相撞,多节车厢脱轨,没有造成人员伤亡,但8头野象死伤。印度铁路公司发言人夏尔马告诉美联社
2025-12-21 15:30:00
央视新闻客户端讯 当地时间20日,荷兰国防部发表声明说,针对加勒比地区库拉索飞行情报区国际空域发生的多起危险事件,荷兰国防部
2025-12-21 15:30:00
央视新闻客户端讯 当地时间12月20日,委内瑞拉外交部长希尔表示,已收到伊朗提出的“全方位”合作提议,以应对美国在加勒比海域部署军事力量所造成的威胁
2025-12-21 15:30:00
央视新闻客户端讯 当地时间20日,世界贸易组织发布《2025年世界贸易报告》指出,在配套政策到位的情况下,人工智能有望通过提升生产率
2025-12-21 15:30:00
央视新闻客户端讯 当地时间12月20日,有消息称,美国卫生部长小罗伯特·肯尼迪长期推动的食品券项目改革将在明年1月1日生效
2025-12-21 15:30:00
新华社莫斯科12月20日电 据俄罗斯媒体20日报道,俄莫斯科州希姆基市当日发生的爆炸事故由烟火装置引起,爆炸导致一人死亡、两人受伤。据俄新社报道,初步调查显示,事故由生活用易爆物
2025-12-21 15:30:00
新华社旧金山12月20日电 据美国太平洋天然气和电力公司网站消息,加利福尼亚州旧金山市20日发生大规模停电事故,影响约13万家庭和商户
2025-12-21 16:00:00
新华社波哥大12月20日电 哈瓦那消息:古巴共产党20日在官网发表声明,以“最强烈的措辞”谴责美国政府针对委内瑞拉的侵略升级
2025-12-21 16:00:00
央视新闻客户端讯 17日至22日,日本多个和平团体在东京举办主题展览,揭露日本侵略历史,呼吁日本政府正视历史,并反对所谓“拥核”主张
2025-12-21 16:00:00
12月20日,香港特区政府警务处处长周一鸣召开记者会表示,在已发现的一具香港大埔宏福苑火灾遇难者遗体中检测出夫妇二人的DNA,至此,该火灾遇难者人数增至161人。周一鸣还表示,由
2025-12-20 14:30:00