- 我的订阅
- 头条热搜
我们正处于一个信息大暴发的时代,每天都能产生数以百万计的新闻资讯!
虽然有大数据推荐,但面对海量数据,通过我们的调研发现,在一个小时的时间里,您通常无法真正有效地获取您感兴趣的资讯!
头条新闻资讯订阅,旨在帮助您收集感兴趣的资讯内容,并且在第一时间通知到您。可以有效节约您获取资讯的时间,避免错过一些关键信息。

...深度学习算法,提升了神经网络的结构和效率,特别是在自然语言处理(NLP)领域表现出色。这些技术的创新使得Gemini 2.0能够更好地理解和生成自然语言,增强了人机交互的智能性。即日起,开发人员便可在AI Studio和Vertex AI中...……更多
2024-12-12 07:15:00模型,音频,模态,自然语言,文生,多语
...国科技公司OpenAI在春季发布会上发布了最新GPT-4o多模态大模型。据OpenAI公司首席技术官米拉·穆拉蒂(Mira Murati)介绍,GPT-4o可以接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合进行输出,...……更多
2024-05-14 13:59:00进一,模态,易用,易用性,人机,模型

...多个细粒度原则进行标注,提供复杂精细化偏好标注。
自然语言语言反馈:提供细粒度批评和润色反馈,可利用此自然语言反馈开发算法及提升模型性能
跨模态 QA 对:输入输出包含混合模态,在不同模态之间实现更丰富的交...……更多
2024-10-18 09:47:00模态,指令,框架,模态,模型,数据

...智能(AI)巨头OpenAI又出王炸,其最新推出的文生视频大模型Sora因其“逼真”和“富有想象力”被广泛赞誉,其生成视频可达60秒也颠覆了传统视频生成领域平均只有4秒的视频生成长度。OpenAI官网介绍,Sora是一种扩散模型,它...……更多
2024-02-19 08:10:00颠覆,布局,行业,视频,公司,模型

...正在火山口跳动冒出。这段 10 秒的视频是豆包视频生成模型基于以上提示词想象创造的。可以说这段视频的拟真度非常高,并且有着娴熟的运镜,足以放入任何影视作品中。有着剪映、即梦等视频创作工具的字节跳动,正式宣...……更多
2024-09-30 09:51:00豆包,字节,生成,视频,模型,豆包

智东西12月3日报道,今天,腾讯混元大模型正式上线视频生成能力,这是在腾讯文生文、文生图、3D生成之后的最新技术进展。据腾讯混元多模态生成技术负责人凯撒现场介绍,此次更新中,HunYuan-Video模型经历了四项核心改进...……更多
2024-12-04 09:49:00文生,腾讯,提示,建议,视频,生成

...装置,五年累计超过128亿元的投入,以及在计算机视觉、自然语言理解等大模型领域的多点开花。“AI大模型会带来新的生产范式,将为我们带来无限的可能性,这件事情无比让人兴奋。我们也会将AGI作为核心的发展目标,在未...……更多
2023-04-14 14:00:00商汤,模型,体系,关键,模型,商汤

...元导读】Meta最近开源了一个7B尺寸的Spirit LM的多模态语言模型,能够理解和生成语音及文本,可以非常自然地在两种模式间转换,不仅能处理基本的语音转文本和文本转语音任务,还能捕捉和再现语音中的情感和风格。在纯文本...……更多
2024-11-23 09:43:00音频,模态,重磅,文本,任务,情感

...技术方向,仍然值得关注,但可以明确的是,随着大型AI模型的产业化进程不断深入,国内外参与者也越来越冷静,更加专注于自身的AI策略与节奏。有人将这两场发布会比作是一场斗地主游戏,OpenAI打出一对二,谷歌就跟四个...……更多
2024-05-19 16:32:00全能,模型,只有,世界,模态,模型

...《捉妖记》海报。 赵宜OpenAI开发的文(图)生视频模型Sora演示素材发布后,再次在全球范围引发了对生成式人工智能的迭代进化及内容生成能力的关注。它可以根据简单的文本指令生成长达60秒的高质量视频。这些视频不...……更多
2024-04-10 10:41:00文化,模拟器,偏见,竞争,时代,世界
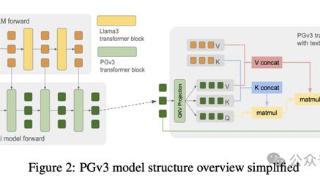
【新智元导读】Playground Research推出了新一代文本到图像模型PGv3,具备240亿参数量,采用深度融合的大型语言模型,实现了在图形设计和遵循文本提示指令上甚至超越了人类设计师,同时支持精确的RGB颜色控制和多语言识别。自...……更多
2024-10-08 09:48:00文生,图形设计,深度,图形,人类,参数

...基准测试,GPT-4o的性能对比GPT-4 Turbo处于优势,对比其他模型更是大幅领先。GPT-4o可通过呼吸来辨别情绪,它甚至可以指导使用者怎么深吸慢呼平复心情,在分析用户喘气声后进行呼吸指导。
GPT-4o响应时间越来越短。它可以在...……更多
2024-05-20 02:59:00人工智能,人工,模型,智能,人工智能,情绪
...果、微软,苹果推出Apple Intelligence AI系统等等。而在AI大模型方面,最主要事件则是OpenAI推出多模态大模型ChatGPT-4o,这一版本具有实时处理和生成文本、音频以及图像等多种模态的能力,被誉为技术上一个巨大突破。事实上,中...……更多
2024-12-26 21:56:00中国,模型,厂商,优势,领域,模型

...的根本。尤其在AI领域,语言的重要性愈发凸显。AI通过自然语言处理来理解和生成文本,通过代码语言来执行任务,通过视觉语言来识别和处理图像。这些不同的“语言”构成了AI理解世界的多种维度。然而,这些语言之间的割...……更多
2024-09-20 09:51:00阿里,生成,统一,语言,世界,模态

5月17日,智源研究院举办大模型评测发布会,正式推出智源评测体系,发布并解读国内外140余个开源和商业闭源的语言及多模态大模型全方位能力评测结果。本次智源评测,分别从主观、客观两个维度考察了语言模型的简单理...……更多
2024-05-17 17:26:00评测,评估,体系,结果,模型,评测

... GPT4o,引起全球轰动。其中 GPT4o 展现出了与人类相近的自然语言交互能力,实现了 AI 能同时读懂人类语音中的内容及情绪,并实时做出反馈。同时,GPT4o 也给众多语音研究人员带来「新的春天」,语音文本多模态大模型成为热...……更多
2024-09-07 09:44:00模型,语音,对话,机构,语音,文本

...又多了一个选择!今日,腾讯宣布旗下的混元视频生成大模型(HunYuan-Video )对外开源,模型参数量 130 亿,可供企业与个人开发者免费使用。目前该模型已上线腾讯元宝 APP,用户可在 AI 应用中的「AI 视频」板块申请试用。腾讯...……更多
2024-12-04 09:48:00文生,腾讯,模型,参数,社区,视频

在 AIGC 技术的推动下,视频生成模型领域正迎来创新的高潮。出门问问独立研发的数字人克隆及生成服务,以其领先的创新能力,提供了高度真实与生动的数字体验,吸引了众多用户的目光。目前,这一先进技术已经成功部署...……更多
2024-04-09 14:00:00重磅,全新,数字,系统,数字,系统

...编辑|邓咏仪1月30日,科大讯飞发布新升级的讯飞认知大模型星火V3.5,并发布了自研的语音大模型,以及星火开源大模型——星火开源-13B。过去一年,科大讯飞的重点都在大模型方向上,临近岁末放出大量更新,某种程度也展...……更多
2024-01-31 07:32:00讯飞,拟人,语音,模型,能力,升级
...作为智谱清言打造的视频创作智能体,清影依托于智谱大模型团队自研打造的视频生成大模型CogVideoX,现已支持文生视频、图生视频多个能力,让用户“自助式”地完成艺术视频创作,首发测试期间,所有用户均可免费使用。同...……更多
2024-07-27 10:00:00更快,生成,高度,视频,清影,视频

【新智元导读】音视频大语言模型在处理视频内容时,往往未能充分发挥语音的作用。video-SALMONN模型通过三部分创新:音视频编码和时间对齐、多分辨率因果Q-Former、多样性损失函数和混合未配对音视频数据训练。该模型不仅...……更多
2024-08-01 09:45:00模态,清华,领衔,模型,视频,音视

...大语言模型,全球科技巨头纷纷入局,后来各家不仅限于自然语言技术,更是将文生图、文生音频、文生视频、图生视频等多模态技术“玩”出了新高度,近期大模型生成的兵马俑,还跳起了“科目三”的热舞。大模型的热潮为...……更多
2024-02-06 13:00:00模型,高薪,正在,数据,工作,模型

...获得了广泛关注。作为一款开源模型,R1在数学、代码、自然语言推理等任务上的性能能够比肩OpenAI o1模型正式版,并采用MIT许可协议,支持免费商用、任意修改和衍生开发等。更令市场惊讶的是,据DeepSeek介绍,R1的预训练费用...……更多
2025-01-28 09:10:00文生,科技股,模型,测试,科技,模型

...人机交互将迎来新的发展阶段。1月30日,讯飞星火认知大模型V3.5升级发布会即将举行,会上将同步发布讯飞星火语音大模型, 此外还将发布开源大模型等。2023年5月6日,科大讯飞正式发布了讯飞星火认知大模型,可以基于自然...……更多
2024-01-29 15:57:00音大,讯飞,星火,语音,模型,突破
...性等方面具备惊人效果……近日,OpenAI发布的文生视频大模型Sora迅速引发人们关注。业内分析认为,该项新产品或将促使大模型厂商加大对多模态大模型的研发投入,并进一步推动AGI(通用人工智能)进程。一直以来,视频领...……更多
2024-02-26 08:58:00模态,行业应用,模型,进程,场景,应用
...专家模块处理,生成连续的视频序列。整个过程可视为将自然语言描述转化为动态视觉内容的复杂系统。在模型架构设计中,CogVideoX特别采用了因果3D卷积(Causal 3D Convolution),以高效捕捉时空维度上的复杂变化,使得模型能够...……更多
2024-11-09 09:54:00画质,音效,高清,国产,电影,生成

...道相似。清华大学人工智能研究院常务副院长、计算机系自然语言处理与社会人文计算实验室负责人孙茂松向《中国新闻周刊》解释,这是基于Transformer架构模型的“硬伤”。科学家曾希望人工智能像人类一样能“演绎推理”,...……更多
2024-03-19 05:31:00中国,模型,生成,视频,文生,中国

...注。Midjourney、Imagen3、Stable Diffusion和Sora等模型能够根据自然语言提示词生成美观且逼真的图像和视频,广受用户喜爱。然而,这些模型在处理复杂的提示词时仍存在不足。例如,当让Stable Diffusion或Midjourney生成「棕色的狗绕着一...……更多
2024-11-07 09:53:00文生,次数,联合,方案,模型,文生
...括商量、秒画、如影、琼宇、格物五大模型,分别对应着自然语言交互、AI文生图、数字人、3D大场景重建、3D小物体生成这五个主流的AIGC应用。在技术交流日,记者发现,这五大模型以全新版本全面亮相,其中一些局部能力甚...……更多
2024-04-29 04:36:00商汤,模型,科技,商汤,能力,模型
...奉毅说。大模型是人工智能领域的重要发展方向,可以为自然语言处理、计算机视觉等领域带来更加先进的技术,推动人工智能与其他领域的交叉融合,为各个行业带来新的机遇和挑战。作为承办单位,新疆理化所在多语言智能...……更多
2024-05-15 10:42:00新疆,模型,研究,技术,论坛,多语
更多关于科技的资讯:

1月24日,美年健康集团与美团医药健康在上海签署战略合作协议,双方宣布通过结合各自的资源与技术优势,共同打造个性化、智能化的体检服务
2025-01-29 17:32:00
1月28日消息,太重数智科技股份有限公司和太原高科锐志物流仓储设备有限公司各有一项应用进入工信部实数融合典型案例名单。经地方推荐
2025-01-29 18:14:00

大皖新闻讯 在2025年蛇年央视春晚的网络直播中,新增设的“实时字幕”成为一大亮点。据悉,本次实时字幕技术由皖企科大讯飞提供
2025-01-29 18:35:00


1月29日消息,据媒体报道,今天是大年初一,又到了每年山东硬核拜年刷屏的日子,大家排队下跪磕头。网友表示,不愧是礼仪之邦
2025-01-29 12:37:00

快科技1月29日消息,今天是大年初一,余承东用华为三折叠屏Mate XT非凡大师给大家拜年,祝大家一开迎春,二开纳福,三开大展鸿图
2025-01-29 13:37:00

快科技1月29日消息,在央视蛇年春晚中,创意融合舞蹈节目《秧BOT》引起了广泛的关注。这些机器人下场时拿手绢脚步直哆嗦
2025-01-29 14:07:00
1月29日消息,今天,微博话题“金晨你怎么可以捅这么大的篓子”冲上热搜榜。据报道,在昨天的央视春晚舞台上,演员金晨把手里的蛇年吉祥物扔了出去
2025-01-29 14:07:00

快科技1月29日消息,B站是央视蛇年春晚独家弹幕视频合作平台,今日已经公布了除夕当晚的相关数据。除夕当晚,B站春晚直播间观看人数创历史新高
2025-01-29 15:37:00

1月29日消息,微博话题“马丽甲状腺”冲上热搜榜第一名。据报道,在2025年央视蛇年春晚舞台上,沈腾、马丽演绎小品《金龟婿》
2025-01-29 16:07:00

快科技1月29日消息,昨晚的春晚开始之前,小米集团董事长特别助理、战略市场部副总经理徐洁云透露,去年春晚现场首次登台的小米SU7车模散场后被“带走”
2025-01-29 16:07:00

快科技1月29日消息,在今年的春晚上,小品《小明一家》节目上呼叫了小爱同学,主角小明的爷爷提出有问题找同学,小明爸爸问找什么同学
2025-01-29 16:37:00

快科技1月29日消息,据官方数据,截至1月29日2时,央视春晚全媒体累计触达168亿人次,比去年增长了18.31%,其中移动端受众规模3
2025-01-29 17:07:00

1月29日消息,据媒体报道,时隔七年,王菲带着一首《世界赠与我的》第五次登上春晚舞台,温暖了无数观众。这首歌由袁晶作词
2025-01-29 17:37:00

1月29日消息,据媒体报道,在央视春晚上,宇树科技人形机器人H1登上舞台与人类演员共同呈现了名为《秧Bot》的节目。它们动作流畅
2025-01-29 17:37:00